






在实际生产开发当中,适当的设计agent的数量和模式,并很好的将数据采集过来,是我们分析数据的第一步,即先要有数据
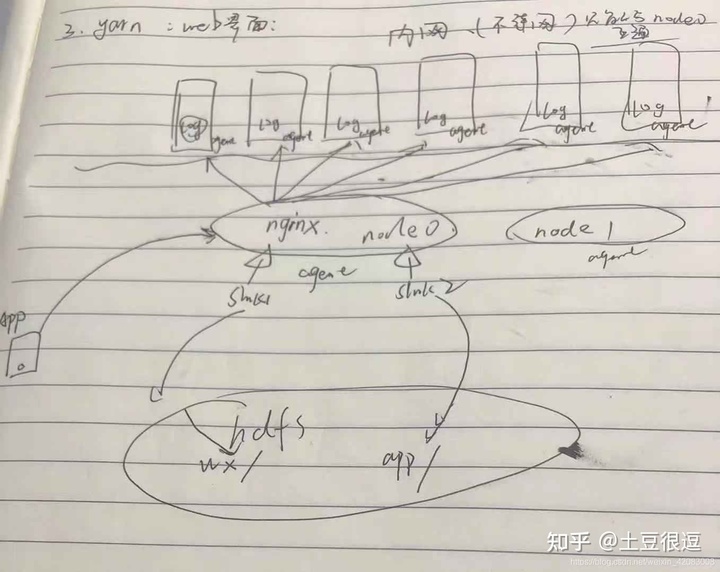
业务系统那边进行埋点,记录日志,到服务器本地磁盘当中
考虑使用高可用模式,并使用级联模式,上游一个agent,下游两个agent,因为要对数据进行简单的清洗 、处理,所以需要一个自定义拦截器
上游agent
高可用模式
1个source taildir类型
1个channel file类型
高可用:2个sink 获得的数据一样 但同时只有一个sink在运转 当主sink发生故障 即使用备用sink进行传输数据 但每过一段时间(惩罚时间) 就会尝试着重新启动主sink
a1.sources = r1
a1.channels = c1
a1.sinks = k1 k2
a1.sources.r1.channels = c1
a1.sources.r1.type = TAILDIR
a1.sources.r1.filegroups= g1 g2
a1.sources.r1.filegroups.g1= /opt/data/logdata/app/event.*
a1.sources.r1.filegroups.g2= /opt/data/logdata/wx/event.*
a1.sources.r1.headers.g1.dataType = app
a1.sources.r1.headers.g2.dataType = wx
a1.sources.r1.batchSize = 100
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type=cn.study.demo03.SelectorInterceptor$EventStampInterceptorBuilder
a1.sources.r1.interceptors.i1.to_encrypt = account
a1.sources.r1.interceptors.i1.to_time = timeStamp
a1.channels.c1.type = file
a1.channels.c1.checkpointDir = /opt/data/flumedata/file-channel/checkpoint
a1.channels.c1.dataDirs = /opt/data/flumedata/file-channel/data
a1.sinks.k1.type=avro
a1.sinks.k1.channel=c1
a1.sinks.k1.hostname = linux02
a1.sinks.k1.port = 41414
a1.sinks.k1.batch-size = 100
a1.sinks.k2.type=avro
a1.sinks.k2.channel=c1
a1.sinks.k2.hostname = linux03
a1.sinks.k2.port = 41414
a1.sinks.k2.batch-size = 100
# 定义sink组及其配套的sink处理器
a1.sinkgroups = g1
a1.sinkgroups.g1.sinks = k1 k2
a1.sinkgroups.g1.processor.type = failover
a1.sinkgroups.g1.processor.priority.k1 = 5
a1.sinkgroups.g1.processor.priority.k2 = 1
a1.sinkgroups.g1.processor.maxpenalty = 10000下游 两个agent配置一样:
a1.sources = r1
a1.channels = c1
a1.sinks = k1
a1.sources.r1.channels = c1
a1.sources.r1.type = avro
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = 41414
a1.channels.c1.type = file
a1.channels.c1.checkpointDir = /opt/data/flumedata/file-channel/checkpoint
a1.channels.c1.dataDirs = /opt/data/flumedata/file-channel/data
a1.sinks.k1.channel = c1
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs://linux01:8020/logdata/%{dataType}/%Y-%m-%d/
a1.sinks.k1.hdfs.filePrefix = DoitEduData
a1.sinks.k1.hdfs.fileSuffix = .log.gz
a1.sinks.k1.hdfs.rollInterval = 600
a1.sinks.k1.hdfs.rollSize = 268435456
a1.sinks.k1.hdfs.rollCount = 0
a1.sinks.k1.hdfs.batchSize = 100
a1.sinks.k1.hdfs.codeC = gzip
a1.sinks.k1.hdfs.fileType = CompressedStream
a1.sinks.k1.hdfs.useLocalTimeStamp = false采集完成,存储到hdfs中
接下来构建ods层表数据
先根据两个业务域的数据 创建不同的表数据
#app表
DROP TABLE IF EXISTS `ods.event_app_log`;
CREATE EXTERNAL TABLE `ods.event_app_log`(
`account` string ,
`appid` string ,
`appversion` string ,
`carrier` string ,
`deviceid` string ,
`devicetype` string ,
`eventid` string ,
`ip` string ,
`latitude` double ,
`longitude` double ,
`nettype` string ,
`osname` string ,
`osversion` string ,
`properties` map<string,string> ,
`releasechannel` string ,
`resolution` string ,
`sessionid` string ,
`timestamp` bigint
)
PARTITIONED BY (`dt` string)
ROW FORMAT SERDE
'org.apache.hive.hcatalog.data.JsonSerDe'
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
TBLPROPERTIES (
'bucketing_version'='2',
'transient_lastDdlTime'='1610337798'
);
#wx表
DROP TABLE IF EXISTS `ods.event_wx_log`;
CREATE EXTERNAL TABLE `ods.event_wx_log`(
`account` string ,
`carrier` string ,
`deviceType` string ,
`ip` string ,
`latitude` double ,
`longitude` double ,
`netType` string ,
`openid` string ,
`osName` string ,
`osVersion` string ,
`resolution` string ,
`sessionId` string ,
`timeStamp` bigint ,
`properties` map<string,string> ,
`eventId` string
)
PARTITIONED BY (`dt` string)
ROW FORMAT SERDE
'org.apache.hive.hcatalog.data.JsonSerDe'
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
TBLPROPERTIES (
'bucketing_version'='2',
'transient_lastDdlTime'='1610337798'
);
写个脚本,将hdfs中的数据导入到hive表中
脚本------导入数据到ods层表(hive) wx表
#!/bin/bash
export JAVA_HOME=/opt/apps/jdk1.8.0_141/
export HIVE_HOME=/opt/apps/hive-3.1.2/
DT=$(date -d'-1 day' +%Y-%m-%d)
${HIVE_HOME}/bin/hive -e "
load data inpath '/logdata/wx/${DT}' into table ods.event_wx_log partition(dt='${DT}')
"
if [ $? -eq 0 ]
then
echo "${DT}app埋点日志,入库成功"
else
echo "入库失败"
fi
导入成功之后:
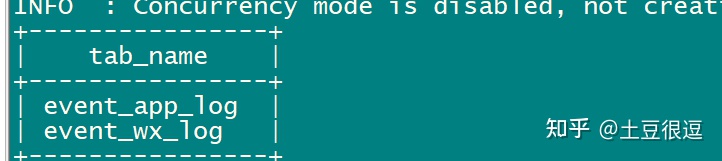
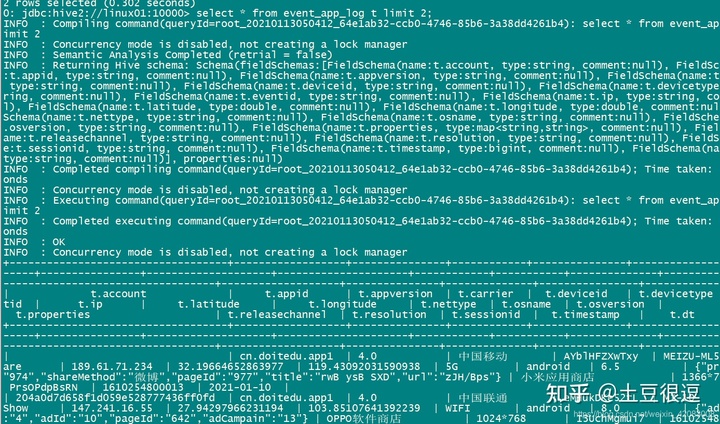
更多学习、面试资料尽在微信公众号:Hadoop大数据开发














 425
425











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









