






概述
动态主机设置协议 (DHCP) 用于为用户提供网络参数配置,其最重要的功能就是动态分配 IP 地址。作为一种核心的网络服务,要求其具有高鲁棒性,高灵活性,简单说就是具有冗余备份功能。传统的简单冗余实现,往往会带来 IP 地址空间不足,无法实现在线切换等问题。目前由 ISC (Internet Software Consortium) 提供的开源 DHCP 软件实现了 Failover( 灾难备份 ) 的功能 , 很好地解决了传统方法带来的问题,在业界得到广泛地应用,特别是 Linux 平台,很早就采用了该实现方法。但实践中由于客户对该功能的理解不够深入,影响了工程中使用,本文归纳了灾难备份中的几个主要概念:服务器状态机转 移,IP 地址绑定状态的变更等 , 着重对灾备的原理进行详细介绍 , 有利于用户在工程中充分发挥灾备的强大功能,另外在文末也给出了灾备的简单配置。本文作者参与了 ISC DHCP 在 IBM 平台上的开发和测试工作,希望能够通过本文给读者一定的帮助。
灾备中 DHCP 服务器的状态机切换
IETF 的 draft-ietf-dhc-failover-07.txt 文档中描述了 DHCP 灾备协议,ISC DHCP 4.1 服务器对这一协议进行了实现,它允许两台服务器共享公共地址池,每个服务器可以分配地址池中一半的地址,这时候我们说两个服务器都处于 NOMAL 状态下。如果其中一台服务器 S1 出现故障,虽然两台机子的通信失败,但另外一台 S2 的 DHCP 服务不会有任何影响,他可以响应已分配地址客户端的 renew 消息,也可以接收新客户端的 discovery 消息,然后基于自己管理的一半地址池,分配给他们可用的地址,这种情况下 S2 会自动切换到 COMMUNICATION-INTERRUPTED 状态。
如果故障服务器 S1 长期无法恢复,我们就需要将 S1 宕机的消息告知 S2(通常是向 S2 发送 omshell 外部命令), 这时候 S2 会等待一个安全期(由配置文件中的 MCLT 定义),保证 S1 服务的 IP 地址都已过期,然后 S2 将会回收先前由 S1 管理的另外一半地址池,对整个地址池进行管理和分配,同时 S2 会自动切换到 PARTNER-DOWN 状态。之后当 S1 恢复时,它会自动检测网络,与 S1 进行通信,然后向 S1 发出同步地址数据库的请求,等同步完成后,两个服务器就会像以前一样各自管理一半的地址池,自动进入 NORMAL 状态。
总之,NORMAL, COMMUNICATION-INTERRUPTED, PARTNER-DOWN 是 DHCP 灾备机制中的三种主要状态机,事实上,灾备切换是一个复杂的过程,其中还包含很多中间状态,比如,RECOVER 状态、RECOVER-DONE 状态、 POTENTIAL-CONFLICT 状态,等等。下图是灾备中主要状态机的切换。
图 1. 灾备中的主要状态机切换
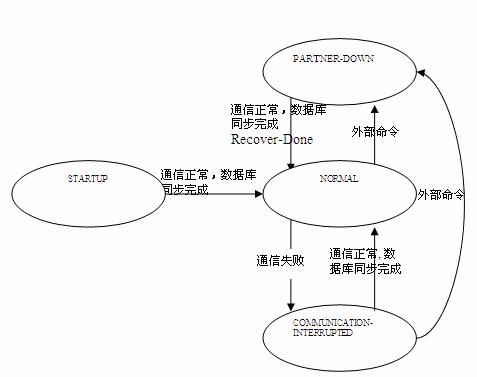
NORMAL 状态下的 DHCP 服务操作 当 DHCP 服务器处于 NORMAL 状态时,每个服务器都会响应所有的 DISCOVERY 消息,响应来至于自己已分配地址客户端的 REQUEST 消息(REQUEST/RENEWAL 和 REQUEST/REBINDING 除外),而对于地址池中任何客户端的 REQUEST/RENEWAL 和 REQUEST/REBINDING 消息,每个服务器都可以响应。另外,一个服务器 S1 对客户端的消息响应可能会引起其地址数据库的数据更新,比如新分配了地址,时间戳发生变化,或客户端地址过期,这时 S1 会将更新消息(BNDUPD)及更新内容发送给它的 PARTNER 服务器 S2,S2 完成对自己的地址数据库更新后,会向 S1 回复消息(BNDACK);
COMMUNICATIONS-INTERRUPTED 状态下的 DHCP 服务操作 当两个服务器处于 COMMUNICATIONS-INTERRUPTED 状态下时,每个服务器都独立地提供 DHCP 服务,而并不假定 PARTNER 服务器已经宕机。事实上,它的 PARTNER 服务器也许工作正常只是通信发生了问题,或者是真的不工作了。在这样的情形下,每个服务器都会响应来自任意客户端的请求消息,而当它们之间的通信恢复后, 双方服务器会自动地进行一个地址数据库的同步整合操作;
PARTNER-DOWN 状态下的 DHCP 服务操作 当一个服务器处于 COMMUNICATIONS-INTERRUPTED 状态下时,该服务器假定它的 PARTNER 处于宕机状态,并基于整个地址池为所有的 DHCP 客户端提供服务。
DHCP 地址数据库中 IP 地址的状态切换
大多数 DHCP 服务器中,一个 IP 地址能呈现多种状态。灾备工作模式下,对于管辖范围内的所有 IP, 一个服务器和它的 PARTNER 需要共同维护了一份信息一致的地址池数据库,因此在两个服务器之间会进行很多的数据同步工作。一个服务器 S1 的任何地址状态发生变化,比如租约更新,地址过期,地址释放等,都需要 PARTNER S2 同步变化,具体的流程是:S1 将更新消息(BNDUPD)发送到 S2,S2 根据消息对数据库进行相应的更新,完成后再向 S1 回复确认消息(BNDACK)。以下是主要地址状态机的简介以及状态机切换。
ACTIVE– 客户端已经获取了该 IP 的租约。
EXPIRED– 意味着该 IP 的租约已经过期。在这种状态下,服务器会向 PARTNER 发送更新信息,当收到 PARTNER 端的确认消息(BNDACK)后,服务器把该 IP 的状态进一步置为 FREE,这样就可以对它重新分配了。
RELEASED– 意味着客户端向服务器发送了 DHCPRELEASE 的消息。在这种状态下,服务器会向 PARTNER 发送更新信息,当收到 PARTNER 端的更新确认消息(BNDACK)后,服务器把该 IP 的状态进一步置为 FREE。
FREE– 当 DHCP 服务器通过 ICMP 探测到某 IP 地址未被使用,并且也不是刚刚被释放或过期的地址,它就将该 IP 设置为 FREE,然后向 PARTNER 发送同步请求,这样该 IP 就可以重新分配了。(注意:如果在 PARTNER-DOWN 状态下,需要等待 MCLT (Maximum Client Lead Time, 该延迟确保其 PARTNER 上维护的地址租约已经过期 ),然后将其 PARTNER 所维护的地址置为 FREE)。
图 2. IP 地址的状态转换
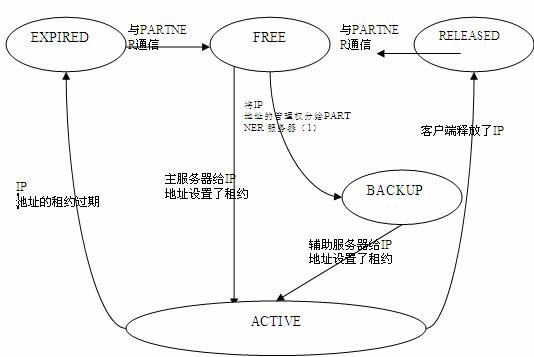
(1) DHCP 服务器处于 PARTNER-DOWN 状态,并且经过了 MCLT 延迟,这时服务器将自动管理整个地址池的 IP,并把把先前由其 PARTNER 维护的地址置为 FREE 状态。
灾备的配置
配置灾备时,我们需要定义 peer, peer 的定义包含灾备协议所需的参数,同时也需要在实施灾备的 pool 中定义 peer 的引用,pool 的定义和使用如下所示:
pool {
failover peer "foo";
pool specific parameters
};
我们在 DHCP 服务器的配置文件(dhcpd.conf)中进行灾备配置,以下给出了一个基本的例子:
failover peer "foo" {
/* 是主服务器还是辅助服务器 */
primary/secondary;
address 192.168.1.1/vanilla.cn.ibm.com;
port 519;
/* PARTNER 服务器的 IP 或者 FQDN 名字 */
peer address 192.168.2.1/d60b85ae.cn.ibm.com;
/* PARTNER 服务器的端口 */
peer port 520;
/* 认定服务器间连接失败的最大时间延迟 */
max-response-delay 60;
/* 在未收到 PARTNER 回复时,BNDUPD 消息的最多重发次数 */
max-unacked-updates 10;
/* Maximum Client Lead Time. 在灾备方案中,该时间延迟保证 PARTNER 上的 IP 租约已经过期。
该参数只能定义在主服务器中。*/
mclt 3600;
/* 主辅服务器的地址分割,通常是各一半 */
split 128;
/* 关于负载均衡的参数 */
load balance max seconds 3;
}
以下是一个具体的灾备配置例子:
On Primary server:
failover peer "myfailover" {
primary; # declare this to be the primary server
address 192.168.1.1;
port 647;
peer address 192.168.1.2;
peer port 647;
max-response-delay 30;
max-unacked-updates 10;
load balance max seconds 3;
mclt 1800;
split 128;
}
subnet 192.168.2.0 netmask 255.255.255.0
{
pool {
failover peer "myfailover";
range 192.168.2.0 192.168.2.255;
}
}
On Secondary server:
failover peer "myfailover" {
secondary; # declare this to be the secondary server
address 192.168.1.2;
port 647;
peer address 192.168.1.1;
peer port 647;
max-response-delay 30;
max-unacked-updates 10;
load balance max seconds 3;
}
subnet 192.168.2.0 netmask 255.255.255.0
{
pool {
failover peer "myfailover";
range 192.168.2.0 192.168.2.255;
}
}
这样 primary server 和 secondary server 组成了一对 failover peer,其地址分别为 192.168.1.1 和 192.168.1.2,它们共同管理子网 192.168.2.0 的地址分配,由于 split 参数是 128,两个服务器各自负责一半的地址分配,primary server 管理 192.168.2.0~192.168.2.127 网段,secondary server 管理 192.168.2.128~192.168.2.255 网段。Normal 状态下,二者独立负责自己所辖的地址段,响应所有的 DHCP 消息,通过相互通信进行地址数据库信息更新,维护一致的地址池状态,当某个服务器 failover 时,另外一个将自动承担起整个 192.168.2.0~192.168.2.127 网段的分配管理工作,而当 failover 服务器重新恢复时,二者会进行一个地址数据库的同步,然后继续共同管理子网 192.168.2.0。整个过程都是系统自动切换,不需任何人工干预,对用户的网络使用不会造成任何影响。
结论
DHCP 服务器的灾备有效地保证了用户网络的稳定性,减少了网络的人工干预,减轻了网络管理员的负担,提高了 IP 资源的使用效率,将会得到更广泛地应用。
作者简介
张晓光,就职于 IBM CSTL,目前的工作主要是基于 IBM i 平台,从事 TCP/IP 应用的开发和测试,包括 DHCP、DNS、OSPF、SMTP、POP 等组件。
胡���波,就职于 IBM CSTL,目前的工作主要是基于 IBM i 平台,从事 TCP/IP 应用的开发和测试,包括 DHCP、DNS、OSPF、SMTP、POP 等组件。















 3176
3176











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









