









2016年google推出一篇文章,利用生成对抗网络保护通信(Learning to Protect Communications with Adversarial Neural Cryptography),设计了基于生成对抗网络GAN的私钥加密算法和公钥加密算法,2018年,Aidan N. Gomez往ICLR会议投稿Unsupervised cipher cracking using discrete GANs论文,此论文主要介绍了利用GAN破译移位密码和维吉尼亚密码,将GAN应用于离散数据。虽然移位密码和维吉尼亚密码属于古典密码,已属于能够被破译的密码,但是此篇是首次将密码分析和GAN联系起来,那至此,GAN已经应用于密码设计和密码分析,相信以后会有越来越多的paper问世。
移位密码和维吉尼亚密码
移位密码又称为凯撒密码,是一种简单的加密方法,即将明文中的每个字母在字母表中移动固定长度的位置,凯撒当时是将信息中的每一个字母用字母表中的该字母后的第三个字母替代,例如A用D替代,B用E替代,现在已不限于移位3,可移位1-25位,不过这种密码可用频率分析的方法破解,或者如果知道是移位密码的情况下,穷尽搜索,也就最多26种可能而已,加密解密和破解都比较简单
给出移位密码的数学定义,其中p表示明文,c表示密文,k表示密钥,也就是明文要移的位数
假设k=3,明文为‘attackatdawn’,加密之后密文则为'DWWDFNDWGDZQ'
维吉尼亚密码是在移位密码的基础上扩展的而来的多表密码,为了生成密码,需要使用表格法,表格包括26行字母表,每一行都由前一行向左偏移一位得到,具体使用哪一行字母进行编译是基于密钥进行的,在过程中会不断地变换。假设以上面第一行代表明文字母,左面第一列代表密钥字母,对如下明文TO BE OR NOT TO BE THAT IS THE QUESTION进行加密,当选定RELATIONS作为密钥时,加密过程是,明文第一个字母为T,密钥第一个字母为R,因此可以在R行和T列找到密文K,以此类推,密钥长度通常明文长度,这时就需要将密钥多次重复使用,RE LA TI ONS RE LA TION SR ELA TIONSREL,可得到密文KS ME HZ BBL KS ME MPOG AJ XSE JCSFLZSY,维吉尼亚密码分解后实则就是多个移位密码,只要只要密钥长度,就能够将其分解,可使用kasiski测试法和重合指数法确定密钥长度,恢复明文

维吉尼亚密码的数学定义,P表示明文,C表示密文,K为密钥,运算在上进行
GAN
2014年,Goodfellow等人首次提出生成对抗网络GAN,GAN是一种通过对抗过程估计生成模型的深度学习模型,GAN框架中同时训练两个模型,生成模型G和判别模型D,生成模型G以噪声为输入生成数据,判别器D判别生成模型生成的输出数据和真实数据,生成模型想要生成能够与真实数据一样的数据来迷惑判别器D,判别器想要最大概率地判断出伪造的数据和真实数据,G和D构成了一个动态的‘博弈’,通过两个模型互相对抗达到最好的生成效果。原始GAN的目标方程当判别器最优时,最小化真实数据分布与生成数据分布
之间的JS散度,由于
和
之间几乎不可能有不可忽略的重叠,所以无论它们相距多远,JS散度都是常数log2,最终导致生成器的梯度近似于0,梯度消失,这也是原始GAN模型崩溃,训练不稳定的原因。为了使模型训练更加固,WGAN中提出了Wasserstein距离,又称Earth-Mover(EM)距离,度量两个概率分布
和
之间的距离。Wasserstein距离相比KL散度,JS散度的优越性在于,即使两个分布没有重叠,Wasserstein距离仍然能够反映它们的远近。虽然WGAN解决了原始GAN训练不稳定的问题,但是WGAN中由于使用K-Lipschitz函数,限制参数在一个范围中,参数的修剪策略(weight clipping)会导致最优化困难,后来又有论文对WGAN提出改进,提出gradient penalty策略,使得学习到的参数分布正常
cycleGAN
cycleGAN主要目的是让两个domain里的图片互相转化,思想主要是在不配对的训练样本中,从一类图片中捕获出特定的特征,然后找出如何将这些特征转化成另一类图片,cycleGAN不同于pix2pix中需要成对的数据(paired data),最值得称赞的地方利用非成对的数据(unpaired data)也能够进行训练,毕竟,不成对的数据比成对的数据好收集和整理。cycleGAN首先尝试通过一个映射关系G将domain X映射到domain Y,然后再通过另一映射F返回domain X,作者介绍循环一致性(cycle consistency loss)来约束,为此cycleGAN不同于原始GAN只有一个生成器和一个判别器,cycleGAN中包括两个生成器G和F,两个判别器
和
,判别器
的作用是区分图片
和转换的图片
![]() ,判别器
,判别器的作用是区分图片y和转换的图片
![]()
cipherGAN
GAN更多地应用在图像方向,目前将GAN应用与离散数据生成仍然是一个值得关注的开放性研究问题。利用GAN训练生成离散数据的主要困难在于在计算图中缺少离散节点的梯度。判别器可能会使用一个与re-discretized生成数据的正确性无关的优化判别准则,作为产生离散数据输出的替代,例如在离散元素上生成器输出一个categorical分布,这是倾向于uninformative discrimination。在我们的离散元素的连续分布例子中,生成的样本都位于k维的standard samplex 中,维度k等于分布中的元素数目,在这种情况下,来自于真实数据分布的样本通常情况下位于samplex的顶点
,然而一些次佳的(sub-optimal)的生成器将会产出在samplex内部
的样本。在这个例子中,一个具有uninformative discriminationde判别器可能评估在samplex顶点上的样本关系作为一个最优判别器标准,这完全对来自生成器的re-discretized样本的正确性是uninformative
我们的工作主要利用了WGAN和离散随机变量的松弛(relaxation of discrete random variables),例如Gumbel-softmax;在实现cycleGAN过程中,加入WGAN Jacobian norm regularization term成功避免了模型的不稳定性,而且同样发现,把判别器放到embedding space中运行,而不是直接在生成器输出的sofrmax向量上运行,性能有所提高。假设在整个训练的过程中,进行了小噪声更新,以至于embedding向量可以作为离散随机变量的连续松弛continuous relaxation,此假设可被论文中给出的命题1证明,而且命题1中还指出如果用一个连续的变量替代离散随机变量,那么判别器就不能任意逼近Dirac delta分布(Dirac delta distribution,狄拉克δ分布,又称单位脉冲函数。通常用δ表示。在概念上,它是这么一个“函数”:在除了零以外的点都等于零,而其在整个定义域上的积分等于 1 。至于为什么要用在这里,并不是很明白???)。
下图展示的是一个toy任务,一个判别器被训练辨别samplex上的一个单个顶点作为真实数据,从左向右,以此是缺少正则化,利用WGAN Jacobian norm regularization 和 relaxed sampling technique,可以看到缺少正则化使得导致判别器坍塌到simplex的顶点,几乎每一处的梯度为0;而使用WGAN Jacobian norm regularization导致连接真实数据和生成数据的直线覆盖的空间有低概率的改变,但是simplex的其他区域的梯度仍然为0;最后,使用连续样本替换真实数据的离散随机变量导致一个更平缓的过渡,提供了一个更强的梯度信号学习。

下面是命题1所需要的定义和命题1是该技术的理论基础,至于证明过程在这里略,论文附录中给出证明过程。


先前尝试用GANs生成离散序列通常利用生成器输出在token空间上的概率分布,这使得判别器从真实数据分布中接受离散随机变量序列和从生成数据分布中接受连续的随机变量序列,这使得判别的任务不重要并且使得潜在的数据分布uninformation,所以为了避免这种情况,通过允许生成器的输出分布来定义相应embedding的convex combination,使得判别器运行在embedding space中,所以损失函数被定义如下:

我们定义了the embeddings 和x的one-hot向量之间的内积(inner product),同样,也定义了the embeddings
和G与F输出的softmax向量之间的内积,前者相当于在嵌入向量中的查找操作,后者相当于在字典中所有向量之间的凸组合。the embeddings
在每一步被训练去最小化
和最大化
,意味着the embeddings易于被映射并且易于区分。
使用上面的损失函数,会出现训练不稳定的问题,所以作者借鉴improved GAN,以求得模型稳定性提高,则损失函数则相应地变成如下形式:
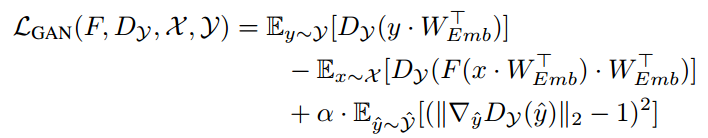
随后,作者又借鉴了Mao等人最初提出平方差损失来代替对数似然损失函数,替换的原始动机在于为了提高训练中的稳定性和为了避免梯度消失问题,在此工作中,作者发现了对训练稳定性的重要影响,所以最后的判别器损失函数如下:
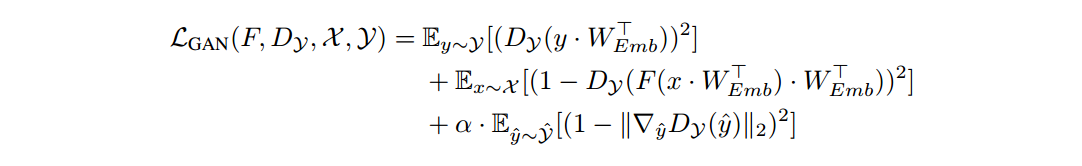
最后,总的损失函数则为:
训练
实现中使用的明文自然语言样本来自于Brown English text dataset,我们生成2倍batch_size大小的明文样本,前一batch_size部分被作为cycleGAN's的X分布,后一batch_size部分通过密钥的选择作为Y分布。我们使用的Brown英语语料库在57340句子中包含一百多万个单词,我们实现了word-level 的'Brown-W'和‘character-level’的'Brown-C'。
对于world-level的单词表,我们选取频率最高的k个单词来控制词汇表的大小,并且引入一个‘unkown’记号来表示所有不在单词表中的单词,作者展示了他们的方法在使用world-level词汇表时有能力扩展到更大的词汇表,而且现代加密技术更多地依赖于具有大量元素的S-boxes。















 1499
1499











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











