






在20GB的数据上测试(迭代更多的次数)
root@master:/opt/spark# ./run spark.examples.SparkKMeans master@master:5050 hdfs://master:900
0/user/LijieXu/Kmeans/Square-20GB.txt 8 0.8
Task数目:320
时间:
迭代次数
时间
1
100.9 s
2
0.93 s
3
4.6 s
4
3.9 s
5
3.9 s
6
3.9 s
迭代轮数对内存容量的影响:
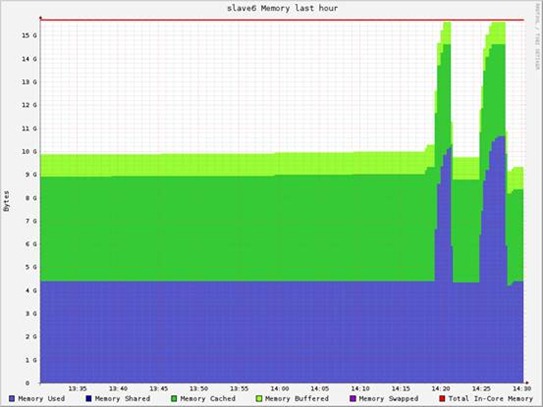
基本没有什么影响,主要内存消耗:20GB的输入数据RDD,20GB的中间数据。
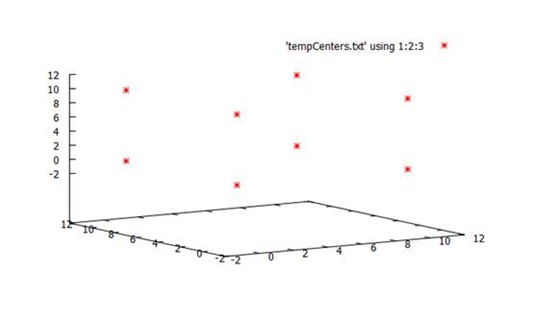
Final centers: Map(5 -> (-4.728089224526789E-5, 3.17334874733142E-5, -2.0605806380414582E-4), 8 -> (1.1841686358289191E-4, 10.000062966002101, 9.999933240005394), 7 -> (9.999976672588097, 10.000199556926772, -2.0695123602840933E-4), 3 -> (-1.3506815993198176E-4, 9.999948270638338, 2.328148782609023E-5), 4 -> (3.2493629851483764E-4, -7.892413981250518E-5, 10.00002515017671), 1 -> (10.00004313126956, 7.431996896171192E-6, 7.590402882208648E-5), 6 -> (9.999982611661382, 10.000144597573051, 10.000037734639696), 2 -> (9.999958673426654, -1.1917651103354863E-4, 9.99990217533504))
结果可视化
2. HdfsTest
测试逻辑:
package spark.examples
import spark._
object HdfsTest {
def main(args: Array[String]) {
val sc = new SparkContext(args(0), "HdfsTest")
val file = sc.textFile(args(1))
val mapped = file.map(s => s.length).cache()
for (iter
val start = System.currentTimeMillis()
for (x
// println("Processing: " + x)
val end = System.currentTimeMillis()
println("Iteration " + iter + " took " + (end-start) + " ms")
}
}
}
首先去HDFS上读取一个文本文件保存在file
再次计算file中每行的字符数,保存在内存RDD的mapped中
然后读取mapped中的每一个字符数,将其加2,计算读取+相加的耗时
只有map,没有reduce。
测试10GB的Wiki
实际测试的是RDD的读取性能。
root@master:/opt/spark# ./run spark.examples.HdfsTest master@master:5050 hdfs://master:9000:/user/LijieXu/Wikipedia/txt/enwiki-20110405.txt
测试结果:
Iteration 1 took 12900 ms = 12s
Iteration 2 took 388 ms
Iteration 3 took 472 ms
Iteration 4 took 490 ms
Iteration 5 took 459 ms
Iteration 6 took 492 ms
Iteration 7 took 480 ms
Iteration 8 took 501 ms
Iteration 9 took 479 ms
Iteration 10 took 432 ms
每个node的内存消耗为2.7GB (共9.4GB * 3)
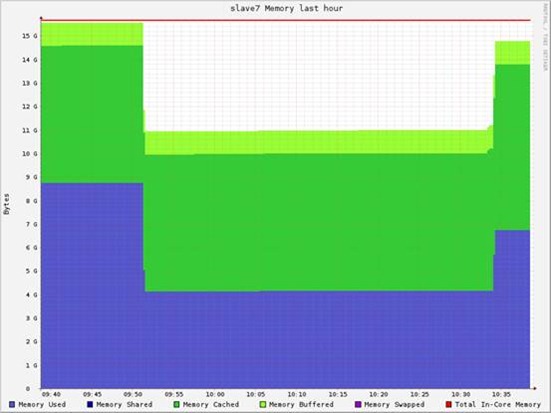
实际测试的是RDD的读取性能。
root@master:/opt/spark# ./run spark.examples.HdfsTest master@master:5050 hdfs://master:9000/user/LijieXu/Wikipedia/txt/enwiki-20110405.txt
测试90GB的RandomText数据
root@master:/opt/spark# ./run spark.examples.HdfsTest master@master:5050 hdfs://master:9000/user/LijieXu/RandomText90GB/RandomText90GB
耗时:
迭代次数
耗时
1
111.905310882 s
2
4.681715228 s
3
4.469296148 s
4
4.441203887 s
5
1.999792125 s
6
2.151376037 s
7
1.889345699 s
8
1.847487668 s
9
1.827241743 s
10
1.747547323 s
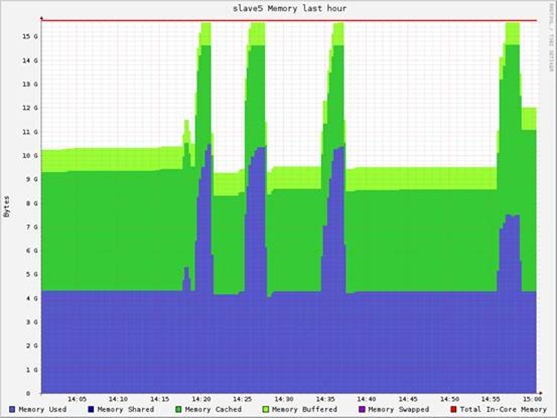
内存总消耗30GB左右。
单个节点的资源消耗:
















 1333
1333











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









