






更新:评论里文章都没看完,我怎么解释都不听,张口就骂的,直接删评论,不再一一回复。
最后一次解释:ub不是“不去搞清楚工作原理”的借口,软件工程中的任何一层都是在制造抽象隐藏细节,也必定会存在无法精确给出定义的情况。编译器处理ub也不是瞎处理,其背后也有自己的逻辑,我的目的是从这样一个简单的程序出发,能够了解一些更加本质的东西,如果你有信心一辈子不碰任何自己或者别人的ub,那请你左上角退出,别在这里嘴臭。
我最后最后重申一遍,这篇文章不是任何一道“题目”的“答案”!如果谁把这个题目出成给大一新生的考试题目,我第一个骂出题人,但是如果你在工程中遇到与变长参数相关的bug呢?难道你就丢下一句ub不了了之?还是你觉得你不用学习这方面的知识,就能完美定位并解决bug?
谢谢。
同学们好,让我们打开本节课的课本:《The art and science of C》

做一道非常简单的题目:

请问:题目的输出是?
把这道题目交给5个初学者去做,大概会各自到自己的电脑上跑一遍,然后把自己编译器给出的结果当作正确答案。当然,或许当一些mac用户兴奋地打开clang的时候,编译器会直接告诉他float不能用%ld来输出,编译都过不了。
除此以外,考虑到大部分初学者都在使用windows+dev cpp(别问我为什么不是vs),然后在如今的9102年基本正常人用的电脑都是x64架构,他们得到的答案多半是:
0 0 123123123 456456456
桥豆麻袋!如果说后两个输出还算正常的话,前面两个3.0,就算强行转成了long,怎么着也不应该输出0啊?
一位同学作为本校lug的一员,冷笑一声,道:windows就是垃圾,看我的!于是他掏出自己的linux+gcc,也跑了一遍这个小程序,结果得到的竟然是:
123123123 456456456 94356794144432 140193333050752
甚至后面两个值还会变来变去,着实令人费解。
好巧不巧,靠窗倒数第二排的同学,手上拿着的赫然是一台古老的32位windows机器,同样拿devcpp编译运行一下,岂料结果竟然更加不同,赫然是:
0 1074266112 0 1074266112
正是风云变幻,世事难料,一个看起来区区几行的程序,竟然得出了截然不同的结果!这到底是人性的毁灭还是道德的沦丧?(逃)
看到这里,可能很多人要说,这实际上是ub,即undefined behavior,也就是说理论上生成什么汇编指令,执行结果如何,全看编译器的心情,本就没有什么讨论的意义。不过有趣的地方在于,这些输出结果并不是那么的不可预测,而是精确地符合对应系统和架构的调用惯例的。
某种意义上,你可以看出这些编译器的实现往往都是遵循着KISS原则——keep it simple and stupid——在符合标准规定的前提下,以最直观的方式写出来的程序。
好了,话不多说,让我们先从(对各位猿们来说)最常见的环境:linux+x64来讲起好了。
上回提到,linux+x64下程序的运行结果是:
123123123 456456456 94356794144432 140193333050752
其中后面两个值还会变来变去,说明它实际上越界了,读取到了未定义的内存区域,也就没有一个固定的值。因此让我们疑惑的主要问题在于,为什么printf直接跳过了前面两个浮点数,优先打印出了123123123和456456456这两个整数呢?
这里我们就需要提到调用惯例这个概念了。这里假定读者有关于汇编等原理的基础知识,在此基础上,我们可以大致这么描述:各种操作系统和架构之间有着各种各样的差异,而从c语言的层面上来说,函数调用永远是一样的,因此为了实现源码级跨平台,我们需要一种方法来“实现”c中的函数调用,而为了让不同编译器编译出来的二进制文件能够互相调用,我们希望这种方法是标准、通用的。这种方法就是调用惯例了。
那么,linux+x64的调用惯例长什么样呢?我们可以通过查看标准文档来一探究竟:
https://www.uclibc.org/docs/psABI-x86_64.pdfwww.uclibc.org当然,这里无需读者阅读整篇文档,让我们直奔重点——3.2.3节Parameter Passing(传参)。
首先注意到的是,linux+x64下所有函数调用都优先使用寄存器——这一点继承于x86的fastcall调用惯例,而与cdecl(通过栈传参)则有较大不同,这样做最大的好处是可以提高函数调用的速度。在我们这份标准中可以看到,其调用惯例允许将函数的前六个参数使用寄存器传递,依次分别为rdi,rsi, rdx,rcx,r8,r9,而在此之后的参数仍然需要通过栈来进行传递。
另外,由于x64架构定义了MMX寄存器, 函数参数中的浮点数将被直接存入MMX寄存器中,不计入上述的6个参数范围,从xmm0到xmm7, 共有8个可用,更多的参数同样需要通过栈传递。
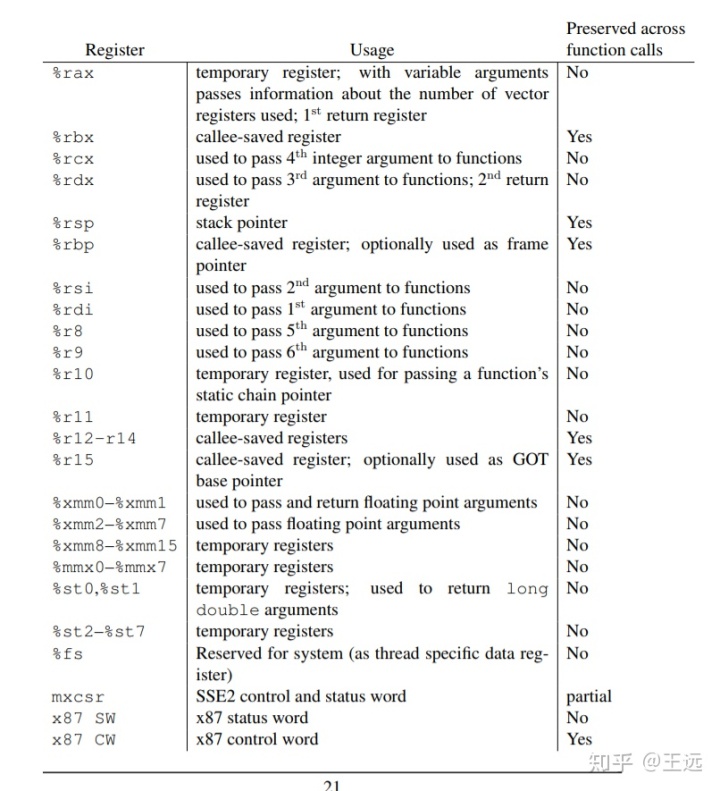
在此之后,文档也给出了函数返回值的传递方法,在此不多赘述,感兴趣的读者可以直接阅读原文。另外,文档中也给出了一个例子,便于读者理解参数传递的具体方法:

在这里,我们需要格外注意到的一点是,由于在参数传递的过程中,整数(以及可以视作整数的指针等)与浮点数被完全分成了两组,因而只有整数与整数之间、浮点数与浮点数之间的传递顺序得到了保存,整数与浮点数交错的顺序则无从得知。
也就是说,当调用一个参数为int, float和一个参数为float, int的函数时,在寄存器中存储的值是完全相同的。(当然前提时整数和浮点数的值都不变)
这对于绝大多数普通的函数都不存在问题——因为传参的方法以标准的方法得到了指定,被调用的函数只需要用同样的规则解析一遍自己的参数列表,就可以知道哪个参数被存在了什么地方,从中读取便是——
——但偏偏还有一种东西叫做变长参数,这便导致了问题的产生。
如果读者用c语言写过处理边长参数的程序,应该知道其处理的基本方法:
#include <stdarg.h>
void foo(int n, ...) {
va_list args;
va_start(args, n);
...
int i = va_arg(args, int);
...
va_end(args);
}在x86的cdecl调用惯例中,其实现原理很容易就能猜个大概:va_start将args初始化为n在栈中地址之后的地方(注意这里的n实际上并不是取的值,而是通过某种宏操作来实现需要的效果);va_arg从args的位置开始,读取sizeof(int)这么多字节的内容作为返回值,并且更新args的地址; va_end则负责一切可能的收尾处理 。
然而在x64的调用惯例中,就出现了一个严重的问题:va_arg需要从参数列表中取出“下一个”参数,然而由于MMX寄存器的存在,我们无法辨别下一个应该是整数还是浮点数,为了兼容性又不好随便修改接口,怎么办呢?
我们不如先想象一下printf这一类的函数的大致实现方法,因为它们是我们需要首先考虑兼容性的目标。由于printf的格式字符串中按顺序给出了所有需要的参数类型,其实现方法很大程度上就是解析格式字符串,在找到某个需要读取的参数时,根据其类型调用va_arg。也就是说,我们只要解析格式字符串,就可以得到整个函数应有的函数签名,再使用调用惯例所规定的传参方法,就可以得出每个参数所在的位置了。
当然实现中不可能要求stdarg中的什么东西去主动解析格式字符串,而是采用一种简单但有效的解决方案——这里便是之前所说的KISS原则——即:因为函数签名转换为传参步骤是按照参数顺序一个一个来的,理论上我们可以通过“之前的所有参数类型”和“下一个参数类型”决定该参数所应该处于的位置。那么,在va_arg中,我们也可以保存“之前所有的参数类型”,在得到“下一个参数类型”之后,解析出其所应在的位置,从此位置读出参数的值即可。
上面这几段话可能有些拗口,需要多读几遍才能理解,不过其体现的正是,用最有效也最简单地方法解决问题,往往正好能够得到最好的结果。
于是我们便实现了我们的所有目标:保持stdarg接口不变,保证源码级兼容,并且实现变长参数的功能。一切都很美妙,世界一片光明,仿佛天堂就在眼前。
——是吗?
我们之所以能够根据格式字符串中的参数类型,获取到调用时传入的值,建立在这样一个前提上,即,传入时的参数类型和格式字符串完全匹配,至少在整数和浮点数的数量和顺序上应当匹配。不然的话,stdargs甚至做不到按照顺序将浮点数输出为整数,而是直接会访问越界,产生的后果难以预测。
回过头来看最前面的例子,可以发现的是其反映的正是这个现象。为什么输出的是:
123123123 456456456 94356794144432 140193333050752
现在的我们已经能够解释这个现象的产生原理了:在读到第一个%ld的时候,printf内部执行了va_arg(args, long),就从“第二个整数参数”(因为格式字符串是char *,也算一个)的rsi寄存器中进行读取,也就得到了123123123这个值;第二个%ld如法炮制,读到了“第三个整数参数”的rdx,也就是456456456。
当读到第三个%ld的时候,同样的道理,va_arg试图从“第四个整数参数”也就是rcx中取值,然而我们在调用printf的时候只给出了三个整数参数,没有给rcx赋值,从而va_arg读到的实际上是这个寄存器之前的值,其值没有明确的定义,大致上也可以理解为随机的了。第四个%ld则不再赘述,原理相同。
至此,我们就基本讲完了这个问题在linux+x64下的解法,迫于篇(tou)幅(fa)所限,另外两种情况只能放到下次再讲了。
课后习题(雾):
- 请读者根据linux+x64的调用惯例,写一个自己的
stdargs.h,只需支持int,char *,double和float。更新:评论中指出实现完整的stdargs.h在x64下需要编译器支持来分析语法,不太可能自己实现。因此我们这里将题目约定为,变长参数之前正好有一个整数类型的参数,这样的话应该就能够实现了。 - 写一个自己的简单版
printf来验证上一题中的stdargs.h可用。














 172
172











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









