







论文地址:https://openreview.net/pdf?id=Bkg3g2R9FX
个人主页版:https://www.luolc.com/publications/adabound/
GitHub地址:https://github.com/Luolc/AdaBound

这篇论文提出来一个神经网络优化算法--AdaBound。而且刷新很多AI新纪录,目前已经被 2019 AI 顶会 ICLR收录。
优化算法已经很多了,那么为什么这个优化算法比较突出?
简单来说:它训练速度与Adam(自适应矩阵估计)不相上下,收敛性能又可以媲美SGD(随机梯度下降)。
SGD:历史悠久,利用梯度下降与固定的学习率,能够一步一步慢慢的向模型的最小值方向更新。缺点就是比较慢,一步一步。其次模型可能会停留在局部最优解左右来回震荡,以至于停留在局部最优点上。
Adam:其自适应优化方法方法,能够让梯度在陡峭的地方下降的更快,平缓的地方下降的步伐小一些,以最快的速度让结果收敛。速度很快,但是缺点是可能不收敛、可能找不到最优解、因此泛化性能不太好。
其实Adam速度还是很棒的,就是泛化性能不太好,那么问题出现在哪里?

如上图,作者根据之前的论文,最后推测不仅仅是极大值,极小值的学习率也有可能引起平平淡淡的泛化性能。然后后面就是作者的验证与改进。

如上图,他的思路是对学习率进行一个动态的裁剪。
因为:SGD 学习率的取值上限=下限;Adam 学习路的取值是 0 到 无穷大(难怪有极端值)
因此将学习率的取值让一个关于时间t的函数动态的变化,那么就会避免出现极大值,而且随着时间的推移,
学习率上限与下限会越来越紧,自然而然模型也会越来越稳定。
实验结果:
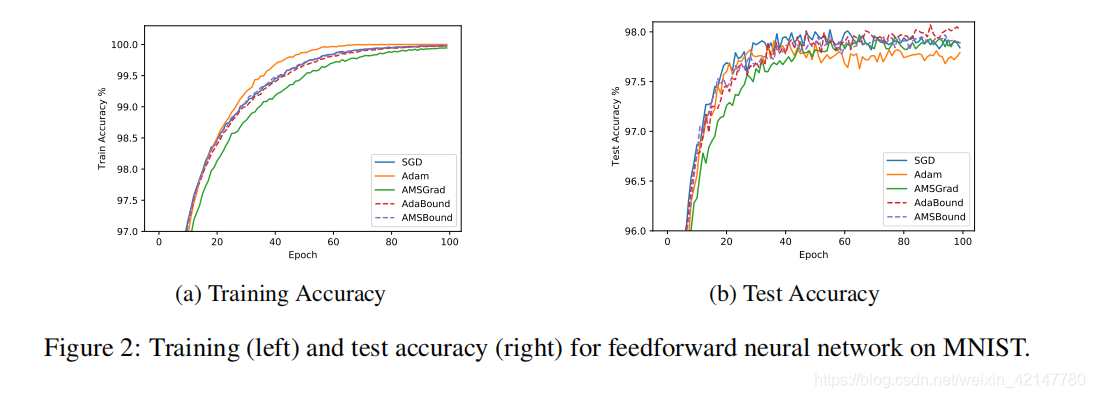
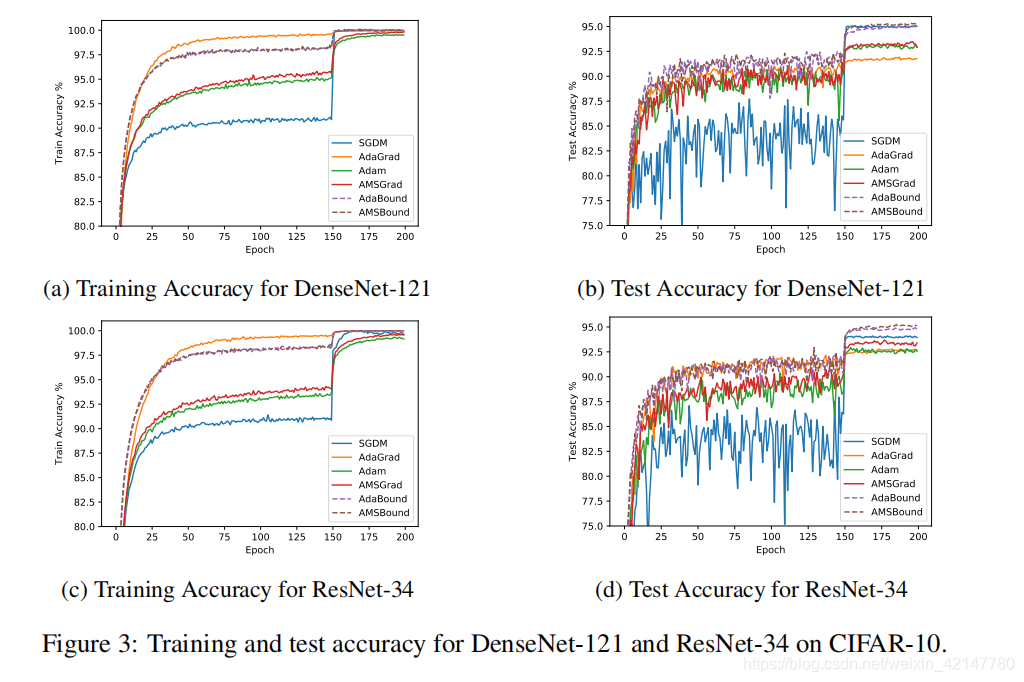
曲线越平滑,则表明基本差不多完成收敛。而曲线的水平高低代表准确率高低,水平位置越高,准确率高,那收敛的结果意思就好。看图就知道了。
额外的惊喜:对超参数不敏感。(意味着更高的鲁棒性,以及可以减少调参的工作时间)
其次代码已经开源pytorch版本,pip安装,可以像其他优化算法一样直接调用。nice~
最后比起他的论文,我更喜欢他的个人主页签名。
A foll living in the amazing world...

====================================附加=================================================
三月初看的论文,对作者刮目相看。
三月中旬在实际场景中检验的时候,有点难堪。














 1337
1337











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









