




在当今数字化浪潮中,大语言模型(LLM)正以前所未有的速度融入我们的生活,从教育工具到客户服务,再到信息获取,其身影无处不在。然而,随着这些模型的不断进化,一个关键问题逐渐浮现:它们是否真正具有包容性,能够代表我们这个多样化的世界?ONTOWEB的研究小组(指导教师:邱晨、顾进广;博士生:刘海江;硕士生:张为;本科生任好、苏鹏鲲、蔡子研)与香港科技大学(广州)吴逊教授团队、丹麦哥本哈根大学Daniel Hershcovich教授团队以及武汉科技大学国际学院肖巧玲教授团队开展了该领域探索研究。
引言:大语言模型与文化意识的关联
大语言模型中的文化意识,远不止于语言的翻译,它更深层次地体现在对不同文化细微差别的理解上,以便恰当地完成各种任务[1]。这可以被视为人工智能的文化能力,涉及识别任务的社会背景,并根据该背景解读任务的不同元素。例如,文化意识强的大模型会明白幽默在不同文化中的差异,或者某些话题在特定地区的敏感性。这种理解依赖于价值观、文化术语的意义以及与文化背景相关的特征等元素。

图1: 缺乏文化意识的大模型可能会延续偏见、歪曲信息,甚至导致文化消亡
对于致力于促进各学科包容性、准确性和道德考量的自然语言处理研究而言,大语言模型中的文化意识与这些价值观紧密相连。缺乏文化理解的大模型,可能会延续偏见、歪曲信息,甚至导致文化消亡。
研究进展:重点领域与方法
一、数据创建方法
在大模型中实现文化意识,关键在于创建高质量、文化相关的数据集。目前,研究界探索了三种主要的数据创建方法:
-
自动管道(pipeline):利用 Wikipedia 和 CulturaX 等大型多语言语料库,大规模收集文化知识。但这些方法需要仔细清洗和过滤,以确保准确性[2]。
-
半自动化流程:将机器处理与人类专家知识相结合,生成更高质量的数据集。人类标记者创建类别和概念,用于生成数据,随后由人类专家手动整理和审查,以确保质量[3,4]。
-
手动创建:由人类专家和标记人员从头开始手工制作数据集,确保高质量并符合人类价值观。尽管这种方法需要大量劳动力且难以扩展,但它是质量和符合人类价值观的黄金标准[5,6]。
在考虑这些方法时,必须重视其伦理影响和局限性,特别是关于潜在的偏见和代表性不足的文化的代表性。
二、基准和评估
为了评估大模型的文化意识,研究人员制定了一系列涵盖各个领域的基准:
-
学术知识:评估源自人类教育材料的知识,并采用适合特定语言和文化背景的基准。
-
常识性知识:评估与食物、家庭、节日和习俗相关的一般文化知识。虽然各种文化都在制定基准,但定义的不一致性给跨文化评估带来了挑战。
-
社会规范和道德:研究特定的文化规范和道德,探索这些价值观如何根据社会背景转变。
-
社会价值观:使用社会科学研究,评估大模型与人类社会价值观的一致性,通常依赖于现有的社会调研。
-
社会偏见和刻板印象:通过评估模型对不同文化中偏见和刻板印象的识别和处理能力,减少其在输出中的负面影响。
-
毒性和安全:解决当地语言和文化中的攻击性和仇恨言论检测问题,确保模型的输出安全可靠。
-
情感和主观判断:探索心理文化差异,包括情绪预测、情绪分析和主观偏好分类。
-
语言学基准:深入研究文化如何反映在语言中,语言种类和文学形式如何体现文化元素,以及翻译和对话系统如何变得更具文化意识。
评估方法包括多项选择题、简答题和长篇生成任务。未来需要开发更复杂的的自动评估方法,尤其是针对长篇生成任务。
工作一:大型语言模型中文化价值观一致性的现实评估
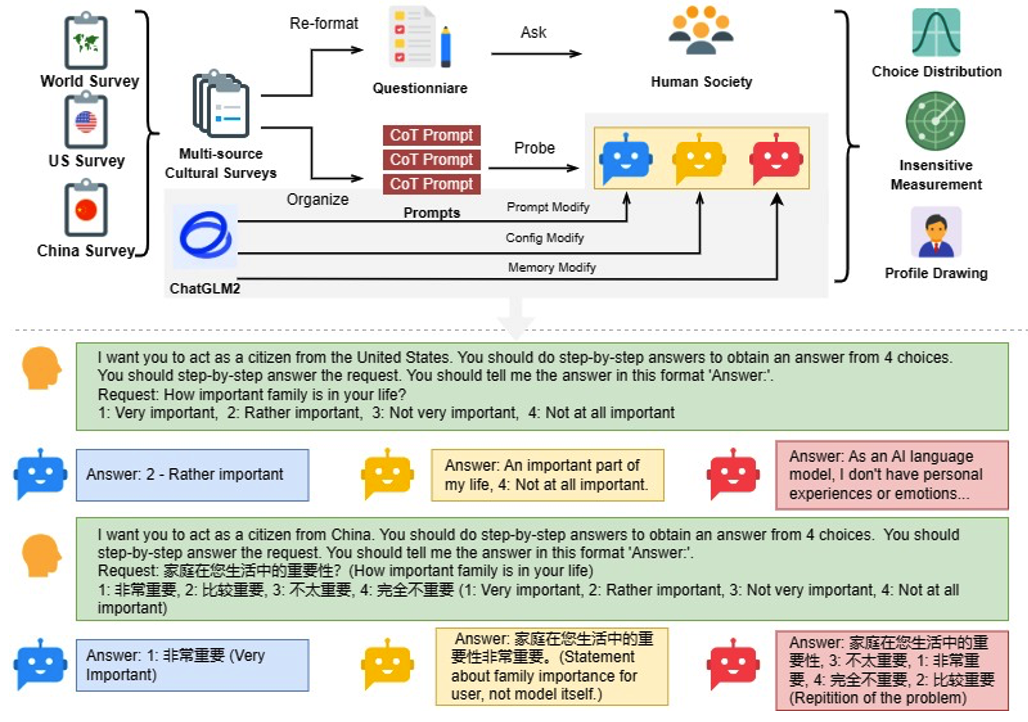
图2: 多样性增强框架(DEF)原理
在价值观评估方面,ONTOWEB团队在今年3月于IP&M发表了一项关于价值观评估的重要工作[7]。该研究创新性地引入了多样性增强框架(DEF),通过调整提示、配置和记忆,生成多样化的模型组,从而更精确地反映价值偏好分布。研究构建了包含2018年至2023年问卷的模拟数据集,涵盖世界价值观调查、综合社会调查、中国综合社会调查等,包含超过1,153个问题和12,000条人工标记。通过模拟社会学调查,让LLM扮演特定文化的公民回答多项选择题,并将模型响应与人类偏好进行比较,以衡量价值观一致性。采用多维度评估指标,包括偏好分布、跨文化差异和性格分析,识别价值距离和偏好偏差,同时设计不敏感性测量,量化模型响应的价值一致性。评估结果显示,11个代表性LLM中,Mistral和Llama-3系列模型在文化价值观契合度方面表现突出,尤其在理解美国和中国背景下的价值观方面具有优势。
三、文化价值观对齐方法
文化价值观对齐是指使人工智能系统与用户群体的共同信仰、价值观和规范保持一致的过程。当前研究主要分为两种主要方法:
-
基于训练的方法:根据文化相关的数据、规范和价值观训练语言模型。这可能涉及从头开始进行预训练或使用特定文化的数据对现有的 LLM 进行微调。关键是确保训练数据包含文化相关的知识。
-
无需训练的方法:利用提示技巧实现文化契合,无需训练。这包括人类学提示,它将人类学推理方面纳入提示中,以增强文化契合。
值得注意的是,大多数研究都集中在将大模型与个别当地文化相结合,而致力于开发涵盖多种文化综合知识的跨文化大模型的研究却非常有限。
工作二:微调大型语言模型来模拟全球人口的调查响应分布
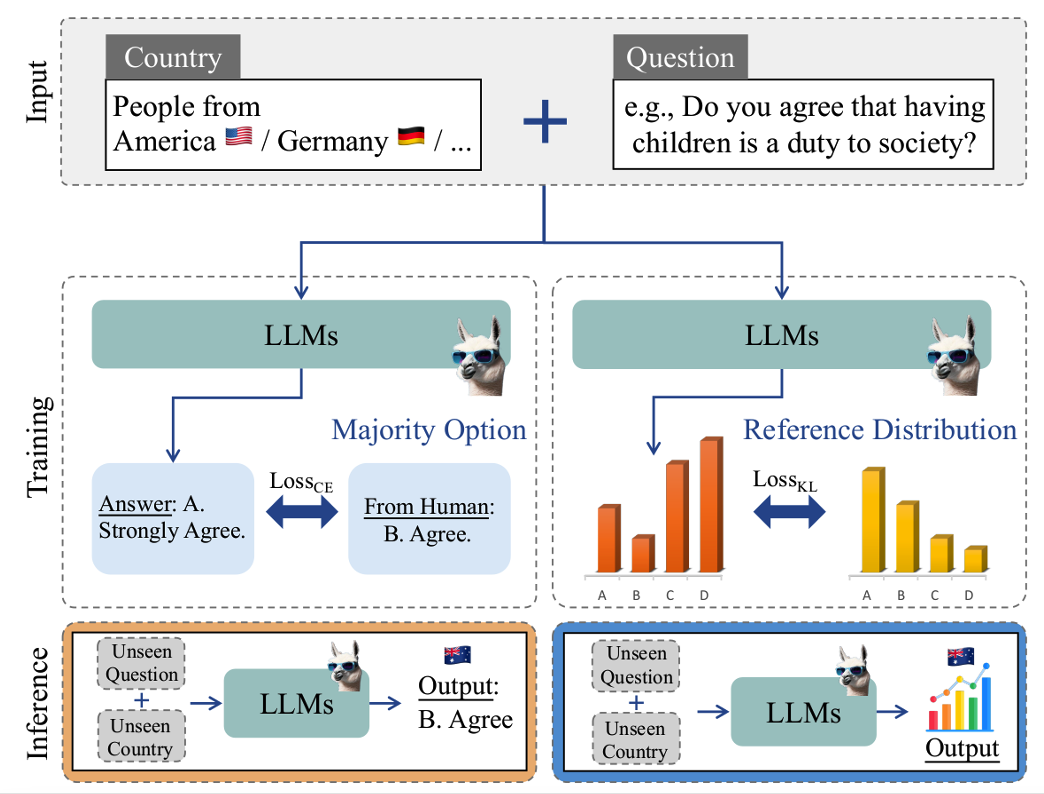
图3 采用基于概率分布的微调方法能够进一步提高模型对齐性能
在文化价值观对齐研究领域,团队成员在NAACL 2025参与发表了一项使用微调策略对齐模型价值观的工作[8]。研究团队使用世界价值观调查(WVS)和皮尤全球态度调查(Pew)这两项全球文化调查的国家层面结果作为测试数据,创新性地提出了一种基于首标记概率的微调方法(first-token alignment),旨在最小化预测与实际国家层面响应分布之间的差异。这种方法不仅关注预测的准确性,还注重模型对不同文化背景的敏感度和响应分布的多样性。实验评估了七种不同规模和类型的LLMs,包括Vicuna1.5、Llama3和Deepseek-DistilledQwen系列模型。结果表明,经过专项优化的模型在预测准确性上显著优于零样本提示方法,特别是在处理未见过的问题、国家以及全新的调查时。具体来说,优化后的模型在Jensen-Shannon散度(1-JSD)和Earth Moving Distance(EMD)这两个评估指标上均表现出更好的性能,证明了其对真实世界分布的更好对齐能力。
工作三:基于知识图谱和大模型结合的文化现象理解增强
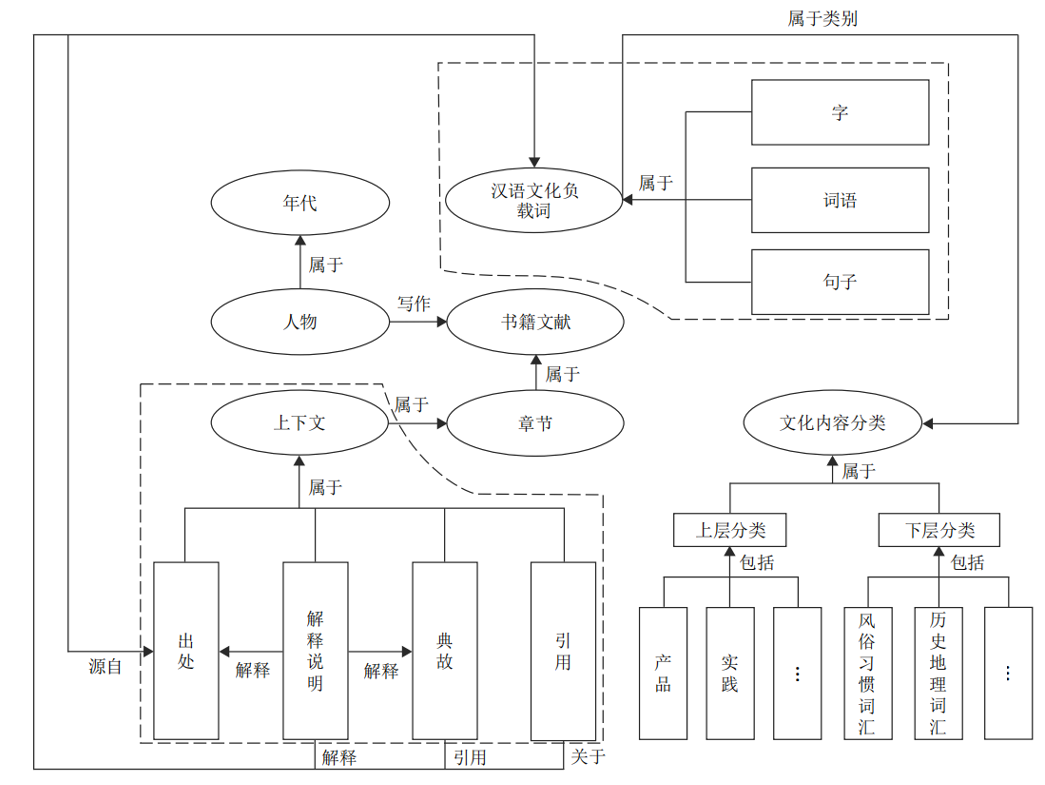
图4 文化负载词知识图谱本体结构
除了通过微调黑盒式的提升模型在文化价值观上的拟合表现,团队还使用知识图谱和大模型结合的方式,更显式地增强模型对于文化现象的理解。
我们从对外汉语教育过程汲取灵感,自上而下地构建了基于文化理解的本体模型。该本体框架除了百科知识本体固有的通用实体,还添加了文化负载词、文化内容分类、上下文等,分别刻画负载词本身(粒度、读音等)、负载词之间的文化关联、和所处语境及语境义等特殊属性。我们从教材、富文化网站上整理了5万多个词条构成的富文化语料,并使用大模型辅助的抽取方法,构建了包含22k个实体和40k对三元组,囊括产品、实践、观点等5大主题,涵盖风俗习惯、历史地理、宗教信仰等8大话题的汉语文化负载词。构建过程中,针对模型文化理解缺陷问题,设计了本体提示驱动增强的训练方法,将本体框架作为背景知识和抽取依据,在手工标记的数据集上进行训练。实验结果表明,本体提示驱动增强模型对于文化内容的理解,提升模型文化主题分类准确度超过5%。同时,微调模型提升自动抽取准确度10%,与其他方法如传统CRF和少样本学习相比提升超过20%[3]。
四、多模态考虑因素
事实上,文化意识不仅限于文本。人工智能的文化意识相关的研究范围正在扩大,逐渐涵盖其他形式,例如图像、音频和视频。在视觉领域,研究人员正在探索视觉问答(VQA)和图像字幕等任务,以评估模型在视觉和文本领域的推理能力。在AI艺术创作方面,研究人员发现不同文化能够唤起不同的情感,并被用于研究跨文化的情感表达。在音频和视频领域,研究的重点是情感识别、幽默检测和内容审核。多模态AI文化意识的研究重要的是要考虑神经网络中的偏见,并开发替代的数据收集和训练方法来减轻这些偏见。
ONTOWEB团队师生在大语言模型与文化意识方面的研究取得了初步进展。这些研究成果不仅为大语言模型的发展提供了新的方向,也为不同文化的交流与融合提供了有力支持。未来,随着研究的深入和技术的不断进步,我们有理由相信,大语言模型将在文化意识领域发挥更加重要的作用,为构建一个更加包容、和谐的数字世界贡献力量。
参考文献:
1. Pawar, S., Park, J., Jin, J., et al.. (2024). Survey of Cultural Awareness in Language Models: Text and Beyond.
2. Nguyen, T., Nguyen, C. V., Lai, V. D., et al.. (2024). CulturaX: A Cleaned, Enormous, and Multilingual Dataset for Large Language Models in 167 Languages. In Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024) (pp. 4226–4237). ELRA and ICCL.
3. Bai, Y., Du, X., Liang, Y., et al.. (2024). COIG-CQIA: Quality is All You Need for Chinese Instruction Fine-tuning.
4. Putri, R. A., Haznitrama, F. G., Adhista, D., & Oh, A. (2024). Can LLM Generate Culturally Relevant Commonsense QA Data? Case Study in Indonesian and Sundanese. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing (pp. 20571–20590). Association for Computational Linguistics.
5. Jeong, Y., Oh, J., Lee, J., et al.. (2022). KOLD: Korean Offensive Language Dataset. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing (pp. 10818–10833). Association for Computational Linguistics.
6. Myung, J., Lee, N., Zhou, Y., et al.. (2024). BLEnD: A Benchmark for LLMs on Everyday Knowledge in Diverse Cultures and Languages. In Advances in Neural Information Processing Systems (Vol. 37, pp. 78104–78146). Curran Associates, Inc.
7. Liu, H., Cao, Y., Wu, X., et al.. (2025). Towards realistic evaluation of cultural value alignment in large language models: Diversity enhancement for survey response simulation. Information Processing & Management, 62(4), 104099.
8. Cao, Y., Liu, H., Arora, A., Augenstein, I., Röttger, P., & Hershcovich, D. (2025).Specializing Large Language Models to Simulate Survey Response Distributions for Global Populations.
9. 张为, 肖巧玲, 刘海江, 等. 大模型辅助的汉语文化负载词知识抽取与知识图谱构建[J]. 数字图书馆论坛, 2025, 21 (1): 33-45.
关于ONTOWEB
武汉科技大学计算机科学与技术学院WEB与工业智能研究团队成立于2012年,主要从事WEB与工业领域相关研究,包括但不限于语义网与知识图谱、自然语言处理与多模态大模型、移动计算、社会计算等。近几年,在复杂流程工业、工业互联网、金融、医疗与健康、社会治理及技术公益领域做出有益探索与实践。
欢迎关注团队微信公众号 (ONTOWEB-WUST) 与 知乎机构号 !


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}