







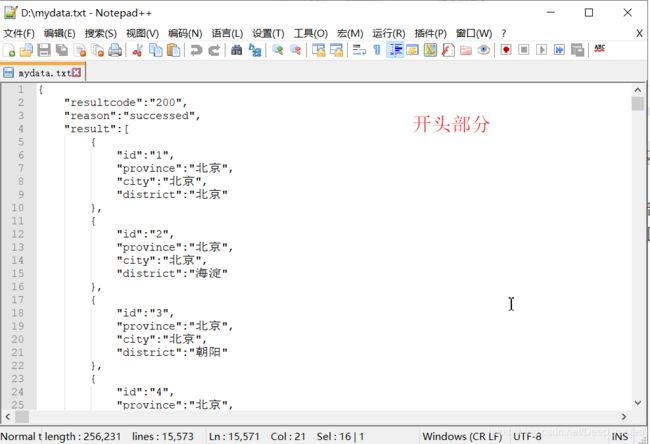
一、数据是从“聚合数据”这个网站获取的,点我下载json文件,访问相应的地址,就返回很长的json格式的数据。因为不太了解json数据格式,我自己另外加了双引号(其实值的部分可以是数字类型的,不用引号)添加后如下图所示:
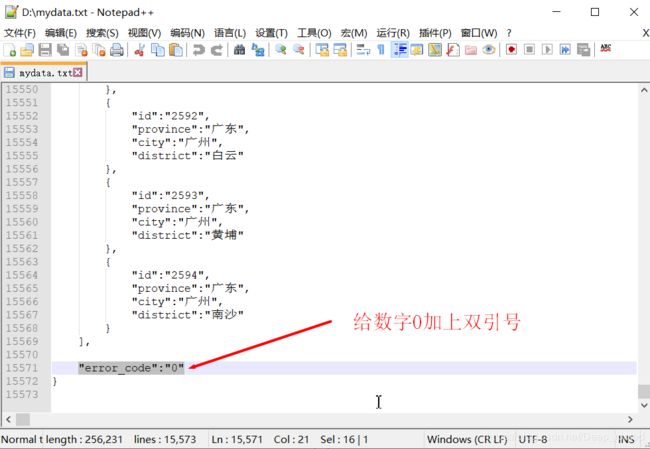
可以看出来数据是有很多行的,因为中间的部分格式比较统一,所以我再截个开头部分的图片吧,如下图所示:
这个json文件的结构也不是很复杂,最外层的大括号(大括号表示对象)里面有四个键,分别是resultcode、reason、result、error_code,其中呢,我只关心result里面的数据,所以我要把result里面的省市县数据保存到数据库当中。
二、解析这个json文件数据需要4种jar包,分别是:
①“mysql数据库驱动jar包”
②“阿里巴巴数据库连接池druid驱动jar包”
③“JdbcTemplate相关jar包”
④“fastjson”
点击我下载所需jar包和druid的配置文件。
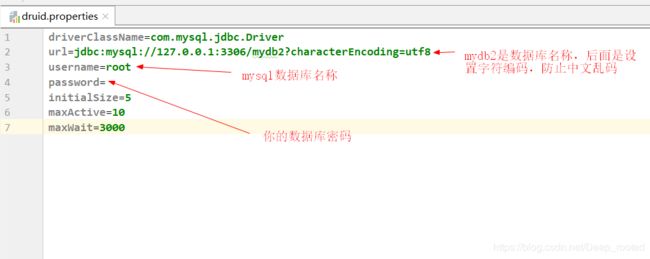
其中呢,druid配置文件需要你自己修改,如下图所示:
三、另外还需要一个JDBCUtils这么一个工具类,没特殊需要的话,不用修改,代码如下:
package bao;
import com.alibaba.druid.pool.DruidDataSourceFactory;
import javax.sql.DataSource;
import java.io.IOException;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
import java.util.Properties;
/**
* Druid连接池的工具类
*/
public class JDBCUtils {
//1.定义成员变量 DataSource
private static DataSource ds ;
static{
try {
//1.加载配置文件
Properties pro = new Properties();
pro.load(JDBCUtils.class.getClassLoader().getResourceAsStream("druid.properties"));
//2.获取DataSource
ds = DruidDataSourceFactory.createDa
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 3823
3823











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









