









欢迎来到python爬虫大讲堂,现在开始你的爬虫旅程吧!
开始你的爬虫
我将以爬取我的博客页面为例,为大家解析爬虫基础知识,首先我们要安装requests库:
- 打开cmd窗口
- 输入pip install requests
首先我们要使用requests库获取页面:
import requests
link='https://blog.csdn.net/weixin_42183408'
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'}
r=requests.get(link,headers=headers)
print(r.text)
上面的代码获取了博客网页的源代码,首先import requests,再用requests.get(link,headers=headers)获取网页,有几个地方需要注意:
- 用user-agent伪装成浏览器访问
- r.text是网页源代码
关于headers我们之后会介绍
运行完代码后,你会看到所有的网页代码,像这样:

提取数据
接下来你需要安装bs4库:
- 打开cmd窗口
- 输入pip install bs4
代码如下:
import requests
from bs4 import BeautifulSoup
link='https://blog.csdn.net/weixin_42183408'
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'}
r=requests.get(link,headers=headers)
soup=BeautifulSoup(r.text,'lxml')
date=soup.find('span',class_='date').text.strip()
print(date)
你会得到类似于这样的结果:2019-02-14 16:56:10,当然你可能会和我的不一样,这里获取了我的博客发布日期,那么我们来看看程序:
这里我们用了BeautifulSoup库对网页进行解析,首先导入库,再把网页代码解析成beautifulsoup形式,接下来用soup.find('span',class_='date').text.strip()找到我们需要的日期
那在那么长的代码中怎么找到标题的位置呢?
于是,Chrome的检查功能隆重登场:
步骤1:
用你的Chrome浏览器打开https://blog.csdn.net/weixin_42183408,右击页面,在弹出的菜单中点击‘检查’:
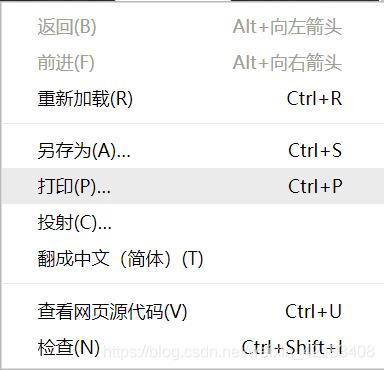
步骤2
单击elements旁边的鼠标按钮(左上角),选中你想要查看的元素,就会自动定位到该元素的位置了:
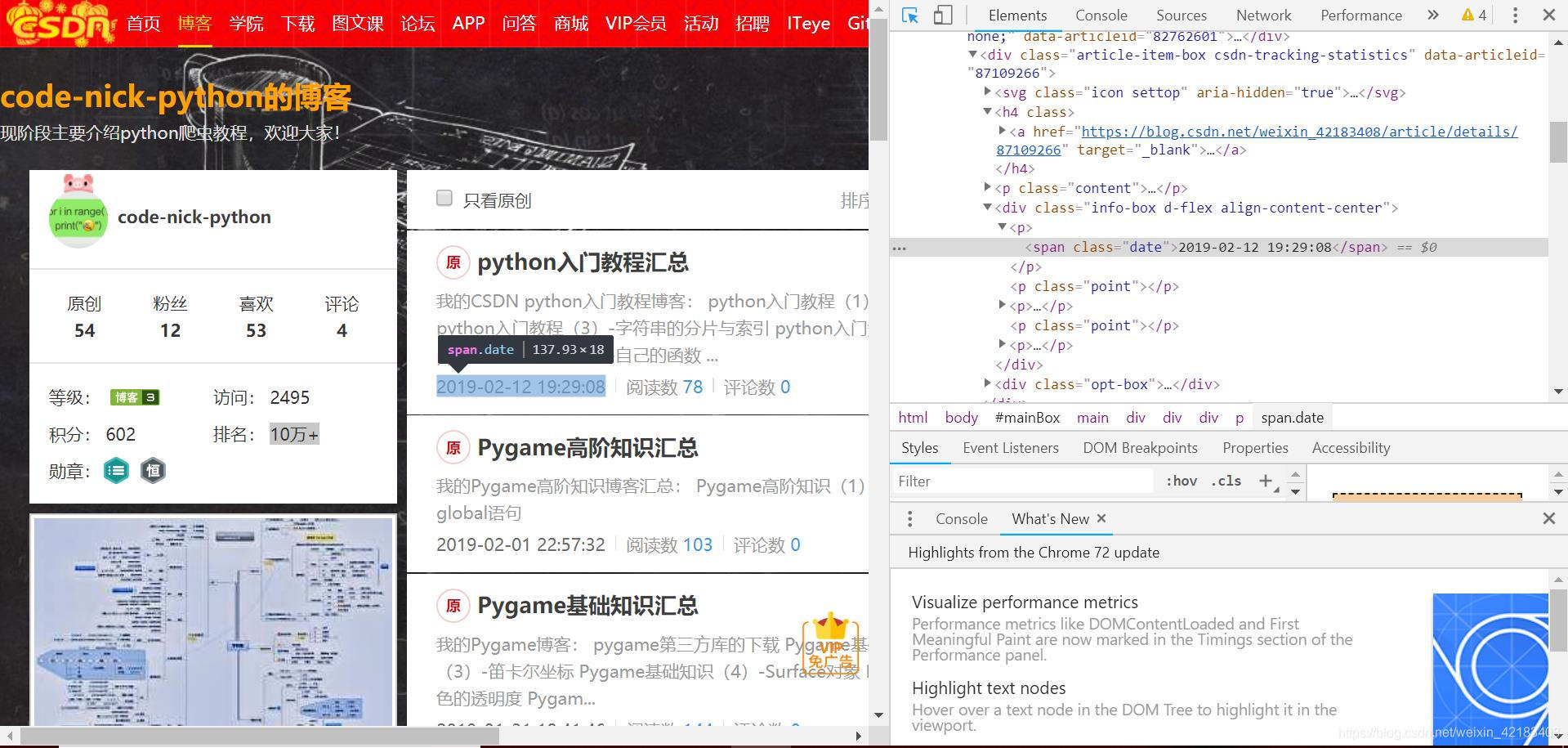
步骤3
我们发现这里的代码是:<span class="date">2019-02-12 19:29:08</span>,因此我们可以用soup.find('span',class_='date').text.strip()来找到日期,关于BeautifulSoup后面会进行详细解析
存储数据
import requests
from bs4 import BeautifulSoup
link='https://blog.csdn.net/weixin_42183408'
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'}
r=requests.get(link,headers=headers)
soup=BeautifulSoup(r.text,'lxml')
date=soup.find('span',class_='date').text.strip()
with open('date.txt','a+') as t:
t.write(date)
t.close()
存储到txt非常简单,详细过程可以参见我的这篇文章:
Python入门知识(8)-open()函数
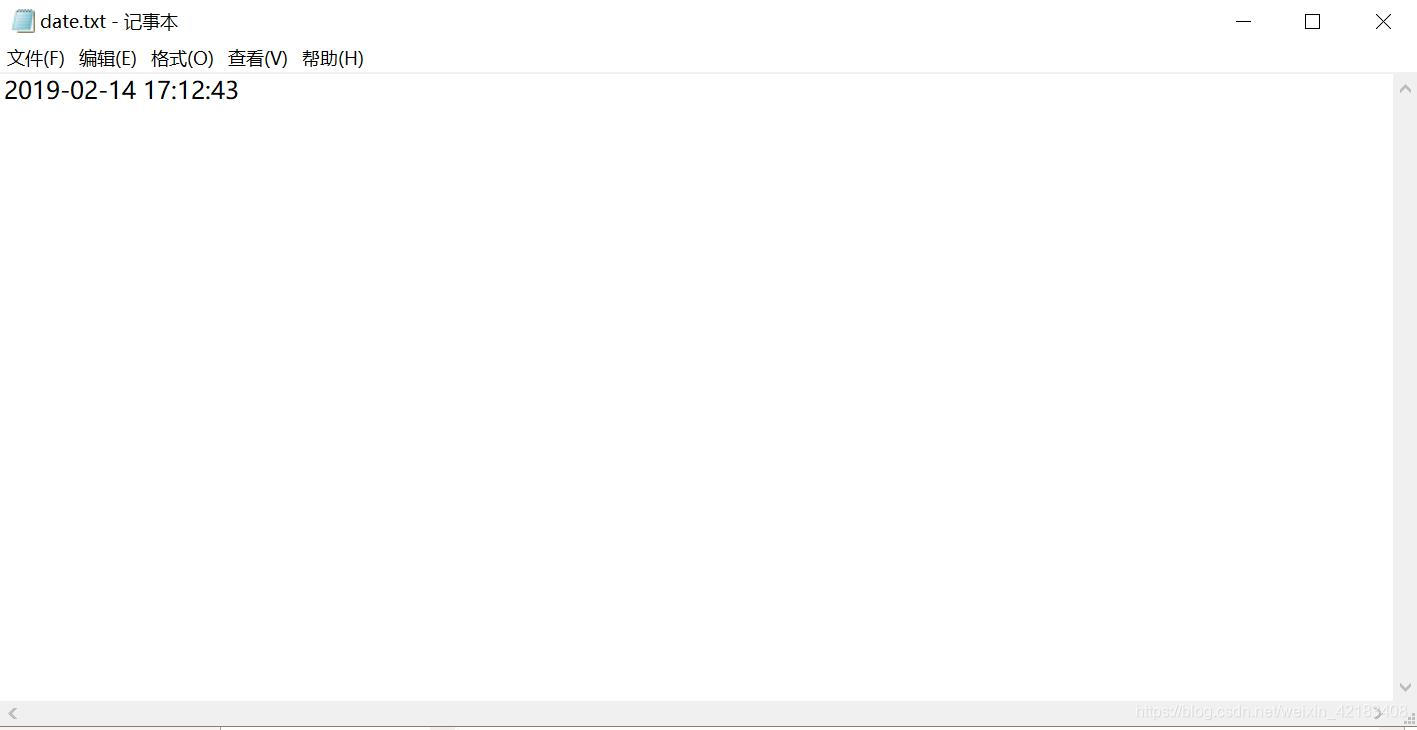
接下来我们打开date.txt文件进行查看,发现日期已经写进去了:
学完第一个爬虫例子后,是不是感觉不难呢?当然,我建议大家自己手写代码,而不是直接复制黏贴,只有自己写代码才能发现自己的缺点,加以改进,代码也能真正被记到心中,久而久之,熟能生巧。
下次我们将开始讲解我们用到的requests库来获取网页,下次见!














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









