






1. 问题描述
在复现论文的过程中,遇到了训练模型Loss一直为负的情况。
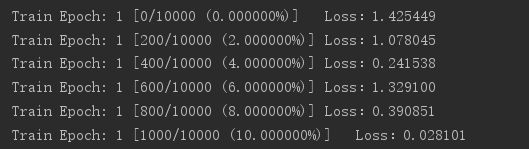
程序主要通过深度学习实现一个分类任务。编程与debug过程全部在windows10系统,Pycharm2018v1.4的IDE下完成,主要框架为pytorch 1.2.0。复现过程中采用了交叉熵损失函数计算Loss。训练过程中输出信息如下:

输出部分的代码段:
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output, target.squeeze())
loss.backward()
optimizer.step()
if batch_idx % log_interval == 0:
print("Train Epoch: {} [{}/{} ({:0f}%)]\tLoss:{:.6f}".format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100.*batch_idx/len(train_loader), loss.item()
))
print("output:", output)2. 解决过程与方案
在检查确认训练代码无误之后,通过查找资料和逐步排查,寻找到了两个出错原因。
针对交叉熵损失函数:
一般情况下,分类任务的输出y采用One-hot Encoding,即每个值非0即1,对应公式中的y或(1-y)一定是1,而一定要是负值才能保证Loss大于零。所以初步判断实验数据和模型输出是错误的根源。
原因一 输入数据未归一化
数据没有归一化会造成取对数的过程中数据跨度超过了[0,1]这个范围,那么自然会造成为正,从而Loss小于零。解决办法就是对数据进行归一化。于是构造了一个归一化函数,从而解决问题。代码如下
def data_in_one(inputdata):
min = np.nanmin(inputdata)
max = np.nanmax(inputdata)
outputdata = (inputdata-min)/(max-min)
return outputdata原因二 torch.nn.functional.nll_loss()使用条件不满足
执行方案一,并不能解决我的问题。于是开始寻找交叉熵函数本身的问题,于是查询了torch.nn.functional.nll_loss()函数上。不同于nn.CrossEntropyLoss(),nn.functional.nll_loss()并没有对预测数据进行对数运算,这样一来,就需要再网络模型的输出中补充上对数运算。
我的原本网络输出层是:
self.softmax = nn.Softmax(dim=1)改为:
self.softmax = nn.LogSoftmax(dim=1)
即可解决问题。或者将nn.functional.nll_loss()换成模型中的nn.CrossEntropyLoss(),不过这样需要修改的代码较多,我采用了前者作为解决方案,解决了问题。
3. 总结
针对解决方案一,我认为应该是主要针对回归问题而言的,因为回归问题中的模型输出具有很大的不确定性,需要归一化处理。而分类问题中,大多数输出都是转化成独热码形式,按理说不应该出现范围溢出的情况。
所以遇到此类问题,回归任务主要检查方案一中的问题;分类问题主要检查方案二中的问题,基本就能解决。














 584
584











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









