







注:本博客需要读者具备初级的ES技能即可,了解index,type,document等概念。
一、搭建elasticsearch、kibana服务器
1、docker安装
可以自行百度搜索docker安装,这里就不再赘述。最好将源换成aliyun源,下载快
2、下载并启动elasticsearch、kibana
拉取elasticsearch, kibana镜像
#这里选择6.X版本,稳定,随大流嘛
docker pull elasticsearch:6.8.3
docker pull kibana:6.8.3
查看下载镜像的image_id
docker images

启动elasticsearch, kibana容器
docker run -e ES_JAVA_OPTS="-Xms256m -Xmx256m" -d -p 9200:9200 -p 9300:9300 --name ES 1d0fd79266e6
docker run -e ELASTICSEARCH_URL=http://192.168.0.130:9200 -d -p 5601:5601 --name kibana 388661dcd03e
启动成功

浏览器输入http://192.168.0.130:5601/app/kibana#/dev_tools/console?_g=()出现kibana客户端界面。
二、SpringBoot项目搭建
1、骨架搭建
SpringBoot的版本是2.1.6 核心依赖 pom.xml
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jdbc</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-thymeleaf</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>2.1.0</version>
</dependency>
<!--elasticsearch start-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
<dependency>
<groupId>io.searchbox</groupId>
<artifactId>jest</artifactId>
<version>5.3.3</version>
</dependency>
<dependency>
<groupId>net.java.dev.jna</groupId>
<artifactId>jna</artifactId>
<version>4.5.1</version>
</dependency>
<!--elasticsearch end-->
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-lang3</artifactId>
<version>3.7</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-devtools</artifactId>
<scope>runtime</scope>
<optional>true</optional>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.47</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
WeiboV 实体类
这是储存在MySQL中的原始数据,查询结果我们需要新增部分字段,所以创建了WeiboVSearch实体类
@NoArgsConstructor
@AllArgsConstructor
@Data
public class WeiboV implements Serializable {
private Integer id;
private String vId;
private String vName;
private String vIntro;
private Integer concernAmount;
private Integer fansAmount;
private String sex;
private Integer lv;
private String imagePath;
}
WeiboVSearch 实体类
此处,为了简便只新增了相关性得分字段 hotScore
@NoArgsConstructor
@AllArgsConstructor
@Data
public class WeiboVSearch implements Serializable {
private Integer id;
private String vId;
private String vName;
private String vIntro;
private Integer concernAmount;
private Integer fansAmount;
private String hotScore;
private Integer lv;
private String imagePath;
}
根据实体类的字段构建elasticsearch的数据结构,在kibana客户端设计好数据结构并运行。
//这里使用ik分词器
PUT weibo
{
"mappings": {
"WeiboV": {
"properties": {
"id": {
"type": "keyword",
"index": true
},
"vId": {
"type": "keyword",
"index": true
},
"vName":{
"type": "text",
"analyzer": "ik_smart",
"index": true
},
"vIntro": {
"type": "text",
"analyzer": "ik_smart",
"index": true
},
"concernAmount": {
"type": "keyword"
},
"fansAmount": {
"type": "keyword"
},
"hotScore": {
"type": "double"
},
"lv": {
"type": "keyword"
},
"imagePath": {
"type": "keyword",
"index": false
}
}
}
}
}
将mysql中的数据库导入elasticsearch,我写在了测试类中。
BeanUtils是Spring中的工具类,可以将WeiboV类中的数据赋值到WeiboVSearch中。
JestClient是Elasticsearch客户端,类似于操作Redis的Jedis客户端。(ES官网推荐6.X版本使用JestClient)
@RunWith(SpringRunner.class)
@SpringBootTest
public class WeiboEsFansApplicationTests {
private static final String ES_INDEX_NAME = "weibo";
private static final String ES_TYPE_NAME = "WeiboV";
@Autowired
private WeiboVService weiboVService;
@Autowired
private JestClient jestClient;
@Test
public void insertES() {
//获取mysql中所有微博大V数据
List<WeiboV> weiboVAll = weiboVService.getWeiboVAll();
List<WeiboVSearch> weiboVSearches = new ArrayList<>();
for (WeiboV weiboV : weiboVAll) {
WeiboVSearch weiboVSearch = new WeiboVSearch();
//将WeiboV类中的数据赋值到WeiboVSearch
BeanUtils.copyProperties(weiboV, weiboVSearch);
//再添加到集合中
weiboVSearches.add(weiboVSearch);
}
for (WeiboVSearch weiboVSearch : weiboVSearches) {
Index index = new Index.Builder(weiboVSearch).index(ES_INDEX_NAME).type(ES_TYPE_NAME).id(weiboVSearch.getId() + "").build();
try {
//执行构建数据结构命令
jestClient.execute(index);
} catch (IOException e) {
e.printStackTrace();
}
}
System.out.println("导入ES成功");
}
}
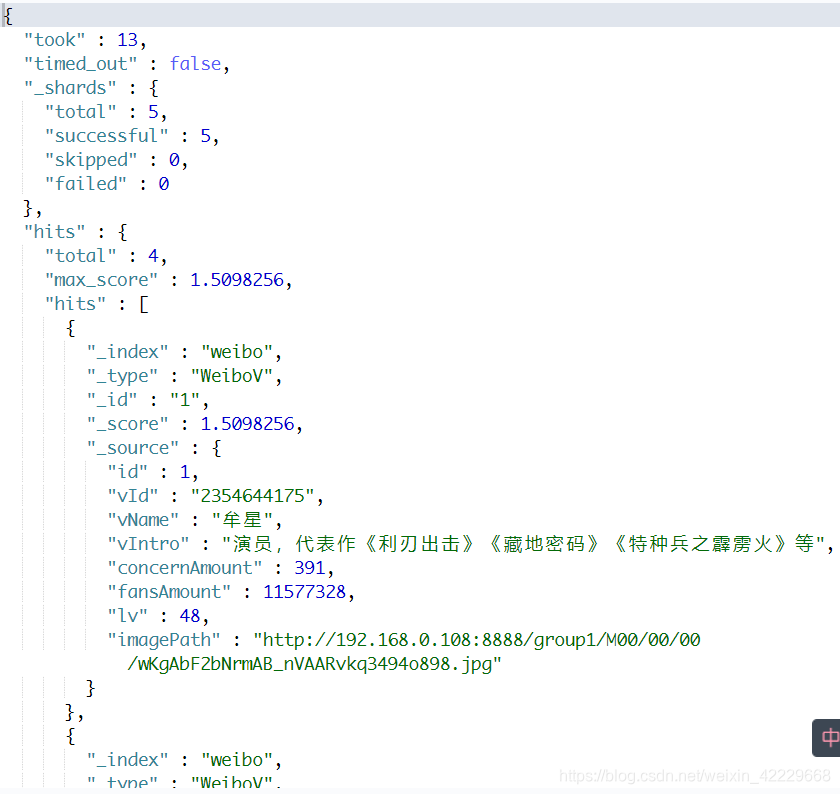
导入成功后,我们可以在kibana客户端测试查询,可以得到结果。
multi_match可以匹配多个值,query就是需要进行查找的值,fields是需要对应的字段。
GET weibo/WeiboV/_search
{
"query": {
"bool": {
"must": [
{
"multi_match": {
"query": "星,霹雳火",
"fields": [
"vName",
"vIntro"
]
}
}
]
}
}
}
查询结果如下:
controller(只列出了核心搜索部分)
@Controller
public class WeiboVController {
private final WeiboVSearchService weiboVSearchService;
@Autowired
public WeiboVController(WeiboVSearchService weiboVSearchService) {
this.weiboVSearchService = weiboVSearchService;
}
@GetMapping("/weiboVSearch/{searchParam}")
public String weiboVSearch(@PathVariable SearchParam searchParam, Model model) {
List<WeiboVSearch> weiboVSearches = weiboVSearchService.weiboVSearch(searchParam);
model.addAttribute("weiboVSearches", weiboVSearches);
return "indexSearch";
}
}
service部分
List<WeiboVSearch> weiboVSearch(SearchParam searchParam);
serviceImpl部分
这里,将上面卸载kibana的查询json转换为java,注释比较清楚可以对比起来看。
@Service
public class WeiboVSearchServiceImpl implements WeiboVSearchService {
private static final String ES_INDEX_NAME = "weibo";
private static final String ES_TYPE_NAME = "WeiboV";
@Autowired
private JestClient jestClient;
@Override
public List<WeiboVSearch> weiboVSearch(SearchParam searchParam) {
String searchKeyWord = searchParam.getSearchKeyWord();
//jest的dsl工具
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(null);
//bool
BoolQueryBuilder boolQueryBuilder = new BoolQueryBuilder();
//must
//multi_match 匹配多个字段
if (StringUtils.isNotBlank(searchKeyWord)) {
MultiMatchQueryBuilder multiMatchQueryBuilder = new MultiMatchQueryBuilder(searchKeyWord);
multiMatchQueryBuilder.field("vName");
multiMatchQueryBuilder.field("vIntro");
boolQueryBuilder.must(multiMatchQueryBuilder);
}
//query
searchSourceBuilder.query(boolQueryBuilder);
//from, size 可以用来做分页
searchSourceBuilder.from(0);
searchSourceBuilder.size(20);
String dslStr = searchSourceBuilder.toString();
List<WeiboVSearch> weiboVSearches = new ArrayList<>();
Search search = new Search.Builder(dslStr).addIndex(ES_INDEX_NAME).addType(ES_TYPE_NAME).build();
SearchResult searchResult;
try {
searchResult = jestClient.execute(search);
List<SearchResult.Hit<WeiboVSearch, Void>> resultHits = searchResult.getHits(WeiboVSearch.class);
for (SearchResult.Hit<WeiboVSearch, Void> resultHit : resultHits) {
WeiboVSearch source = resultHit.source;
Double score = resultHit.score;
System.out.println("相关性算分:" + score);
source.setHotScore(score + "");
//sort
searchSourceBuilder.sort("hotScore", SortOrder.ASC);
weiboVSearches.add(source);
System.out.println(source);
}
} catch (IOException e) {
e.printStackTrace();
}
return weiboVSearches;
}
}
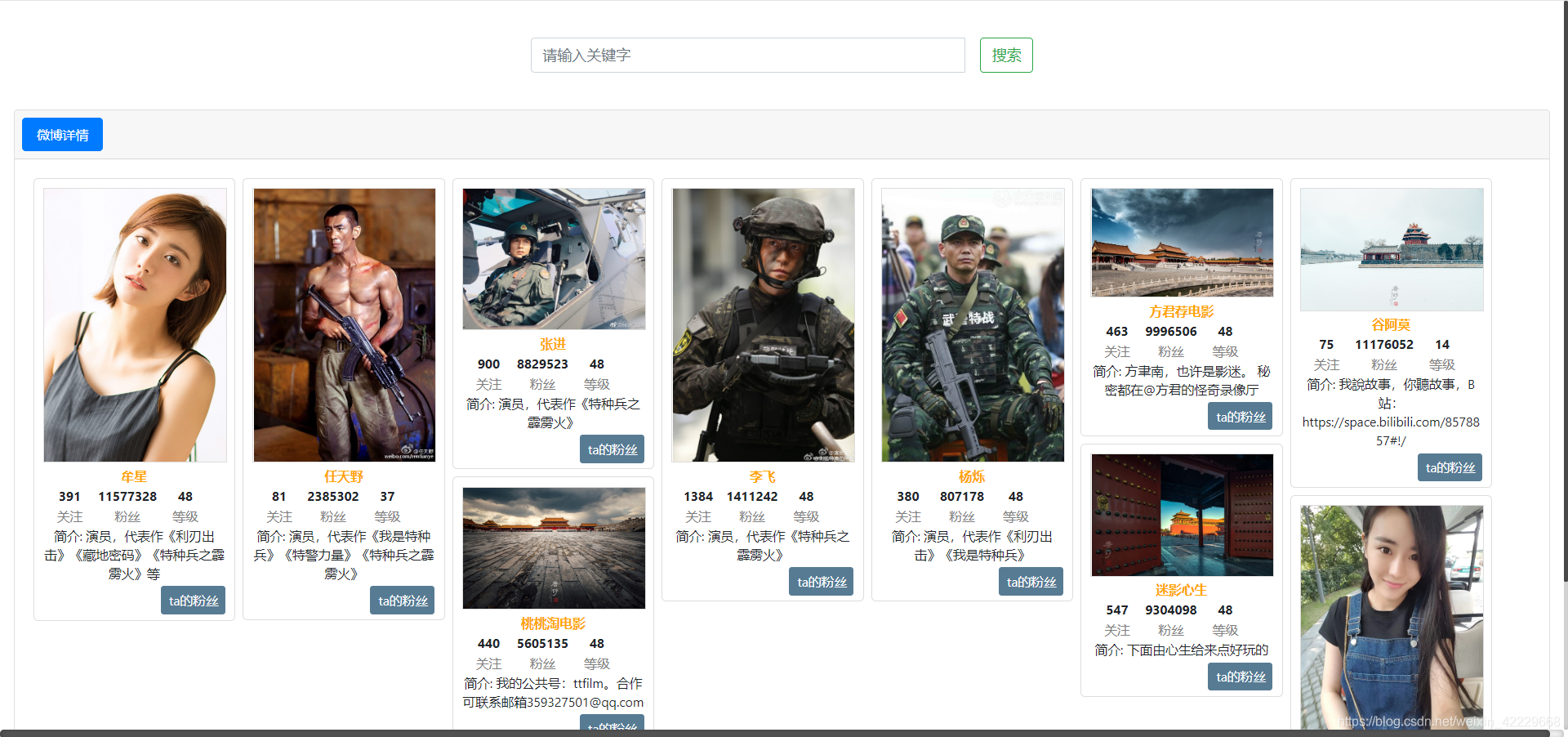
最后的效果图:不是不整齐,用了瀑布流布局就会这样错落排列感觉更好看
搜索特种兵就会按照相关性得分的降序排列,相关性最高的在第一个依次往后。
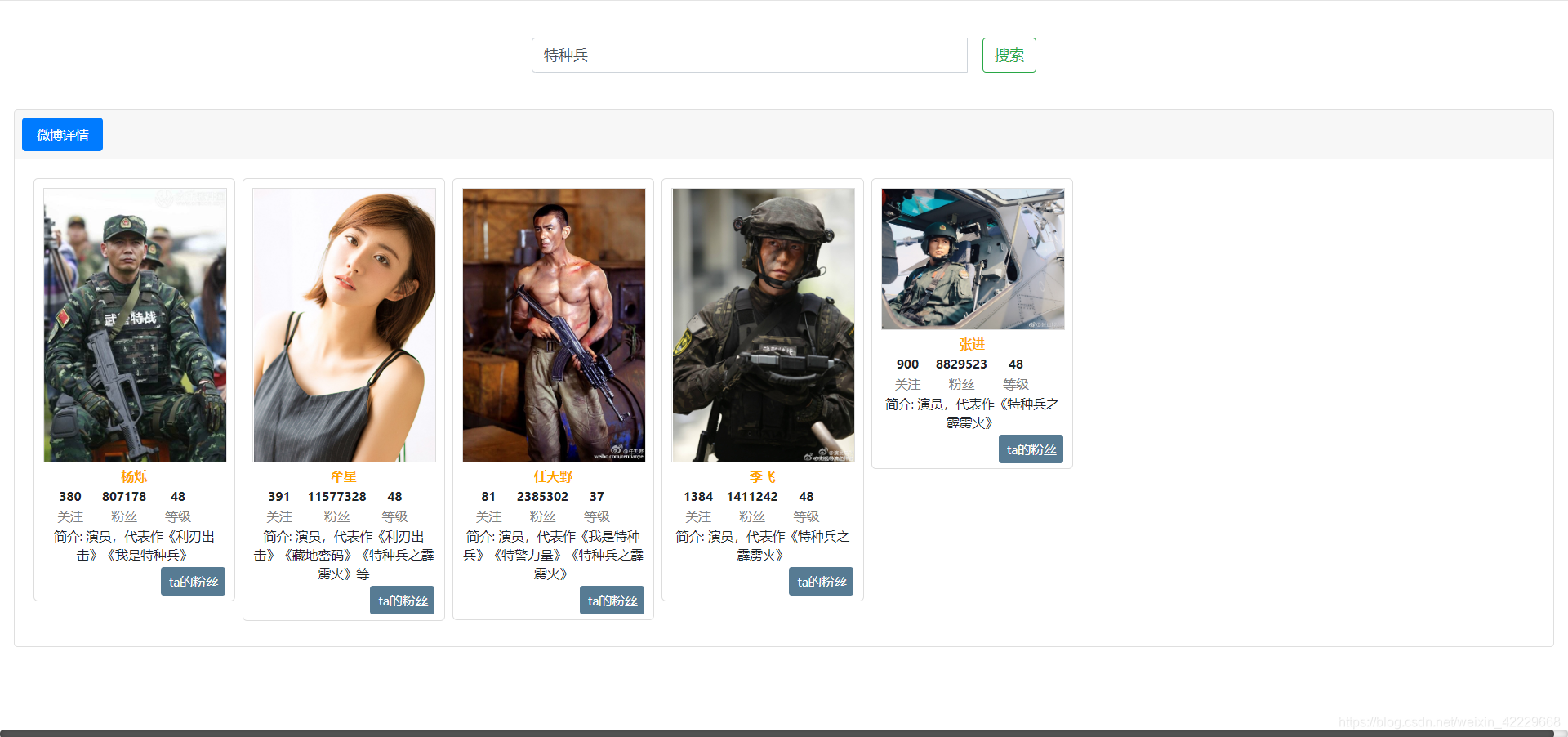
图片全部储存在fastDFS分布式文件上,如果对fastDFS不熟悉可以参考前面关于fastDFS文件系统搭建的文章。
最后附上GitHub地址,想看详细代码的可以clone下来跑一跑,sql脚本也在GitHub上,如果觉得文章还能看得上眼还请点个赞呗。
注:所有数据信息来源于网上,如有任何问题联系作者删除。















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









