







目录
前言
几乎每个大一点公司都有一个“运行时间长,维护的工程师换了一批又一批”的项目,如果参与到这样的项目中来,大部分人只有一个感觉——”climb the shit mountain“。所以我们经常会说谁谁谁写的代码就像排泄物一样,为了避免成为别人嘴里的谁谁谁,所以我写的代码一般不注明作者日期信息(抖机灵,其实是因为 Git 能够很好的管理这些信息),所以在项目中,我们应该编写可维护性良好的代码。同时,对于工程师而言,提高自身的编码能力和编写易于阅读和维护的代码,是提高开发效率和职业身涯中必做的事情。我在面试的时候发现很多面试者拥有所谓的多年工作经验,一直在平庸的写着重复的代码,而从未去推敲、提炼和优化,这样是不可能提高编程水平的。
那么如何编写出可维护的、优雅的代码呢?
首先,我们应该明确的认识到,代码是写给自己和别人看的,代码应该保持清晰的结构,方便后人阅读和维护,假如有一天需要回头修改代码,别人和你都会感谢你!
其次,不管公司大小,不管项目大小,不管工期有多紧张,制定良好的编码规范并落到实地。如果代码质量不够好的话,在需求较多的情况下,就可能会牵一发动全身,大厦将倾。所以在项目的开始或者 现在 制定良好的编码规范,每个人都应该有自己的或者团队的编码规范!
最后,嗅出代码的 Bad Smell,比如重复的代码、命名不规范、过长的函数、数据泥团等等,然后在不改变代码外在行为的前提下,不断的优化重构,以改进代程序的内部结构。
接下来,我总结整理了一大套理论和实操,以飨各位。
避免使用 js 糟粕和鸡肋
这些年来,随着 HTML5 和 Node.js 的发展,JavaScript 在各个领域遍地开花,已经从“世界上最被误解的语言”变成了“世界上最流行的语言”。但是由于历史原因,JavaScript 语言设计中还是有一些糟粕和鸡肋,比如:全局变量、自动插入分号、typeof、NaN、假值、==、eval 等等,并不能被语言移除,开发者一定要避免使用这些特性,还好下文中的 ESLint 能够检测出这些特性,给出错误提示(如果你遇到面试官还在考你这些特性的话,那就需要考量一下,他们的项目中是否仍在使用这些特性,同时你也应该知道如何回答这类问题了)。
编写简洁的 JavaScript 代码
下这些准则来自 Robert C. Martin 的书 “Clean Code”,适用于 JavaScript。 整个列表 很长,我选取了我认为最重要的一部分,也是我在项目用的最多的一部分,但是还是推荐大家看一下原文。这不是风格指南,而是 使用 JavaScript 生产可读、可重用和可重构的软件的指南。
变量
使用有意义,可读性好的变量名
Bad:
var yyyymmdstr = moment().format('YYYY/MM/DD')
Good:
var yearMonthDay = moment().format('YYYY/MM/DD')使用 ES6 的 const 定义常量
反例中使用"var"定义的"常量"是可变的,在声明一个常量时,该常量在整个程序中都应该是不可变的。
Bad:
var FIRST_US_PRESIDENT = "George Washington"
Good:
const FIRST_US_PRESIDENT = "George Washington"
使用易于检索的名称
我们要阅读的代码比要写的代码多得多, 所以我们写出的代码的可读性和可检索性是很重要的。使用没有意义的变量名将会导致我们的程序难于理解,将会伤害我们的读者, 所以请使用可检索的变量名。 类似 buddy.js 和 ESLint 的工具可以帮助我们找到未命名的常量。
Bad:
// What the heck is 86400000 for?
setTimeout(blastOff, 86400000)Good:
// Declare them as capitalized `const` globals.
const MILLISECONDS_IN_A_DAY = 86400000
setTimeout(blastOff, MILLISECONDS_IN_A_DAY)
使用说明性的变量(即有意义的变量名)
Bad:
const address = 'One Infinite Loop, Cupertino 95014'
const cityZipCodeRegex = /^[^,\\]+[,\\\s]+(.+?)\s*(\d{5})?$/
saveCityZipCode(
address.match(cityZipCodeRegex)[1],
address.match(cityZipCodeRegex)[2],
)
Good:
const address = 'One Infinite Loop, Cupertino 95014'
const cityZipCodeRegex = /^[^,\\]+[,\\\s]+(.+?)\s*(\d{5})?$/
const [, city, zipCode] = address.match(cityZipCodeRegex) || []
saveCityZipCode(city, zipCode)
方法
保持函数功能的单一性
这是软件工程中最重要的一条规则,当函数需要做更多的事情时,它们将会更难进行编写、测试、理解和组合。当你能将一个函数抽离出只完成一个动作,他们将能够很容易的进行重构并且你的代码将会更容易阅读。如果你严格遵守本条规则,你将会领先于许多开发者。
Bad:
function emailClients(clients) {
clients.forEach((client) => {
const clientRecord = database.lookup(client)
if (clientRecord.isActive()) {
email(client)
}
})
}
Good:
function emailActiveClients(clients) {
clients
.filter(isActiveClient)
.forEach(email)
}
function isActiveClient(client) {
const clientRecord = database.lookup(client)
return clientRecord.isActive()
}
函数名应明确表明其功能(见名知意)
Bad:
function addToDate(date, month) {
// ...
}
const date = new Date()
// It's hard to to tell from the function name what is added
addToDate(date, 1)
Good:
function addMonthToDate(month, date) {
// ...
}
const date = new Date()
addMonthToDate(1, date)
使用默认变量替代短路运算或条件
Bad:
function createMicrobrewery(name) {
const breweryName = name || 'Hipster Brew Co.'
// ...
}
Good:
function createMicrobrewery(breweryName = 'Hipster Brew Co.') {
// ...
}
函数参数 (理想情况下应不超过 2 个)
限制函数参数数量很有必要,这么做使得在测试函数时更加轻松。过多的参数将导致难以采用有效的测试用例对函数的各个参数进行测试。
应避免三个以上参数的函数。通常情况下,参数超过三个意味着函数功能过于复杂,这时需要重新优化你的函数。当确实需要多个参数时,大多情况下可以考虑这些参数封装成一个对象。
Bad:
function createMenu(title, body, buttonText, cancellable) {
// ...
}
Good:
function createMenu({ title, body, buttonText, cancellable }) {
// ...
}
createMenu({
title: 'Foo',
body: 'Bar',
buttonText: 'Baz',
cancellable: true
})
移除重复代码
重复代码在 Bad Smell 中排在第一位,所以,竭尽你的全力去避免重复代码。因为它意味着当你需要修改一些逻辑时会有多个地方需要修改。
重复代码通常是因为两个或多个稍微不同的东西, 它们共享大部分,但是它们的不同之处迫使你使用两个或更多独立的函数来处理大部分相同的东西。 移除重复代码意味着创建一个可以处理这些不同之处的抽象的函数/模块/类。
Bad:
function showDeveloperList(developers) {
developers.forEach((developer) => {
const expectedSalary = developer.calculateExpectedSalary()
const experience = developer.getExperience()
const githubLink = developer.getGithubLink()
const data = {
expectedSalary,
experience,
githubLink
}
render(data)
})
}
function showManagerList(managers) {
managers.forEach((manager) => {
const expectedSalary = manager.calculateExpectedSalary()
const experience = manager.getExperience()
const portfolio = manager.getMBAProjects()
const data = {
expectedSalary,
experience,
portfolio
}
render(data)
})
}
Good:
function showEmployeeList(employees) {
employees.forEach((employee) => {
const expectedSalary = employee.calculateExpectedSalary()
const experience = employee.getExperience()
const data = {
expectedSalary,
experience
}
switch (employee.type) {
case 'manager':
data.portfolio = employee.getMBAProjects()
break
case 'developer':
data.githubLink = employee.getGithubLink()
break
}
render(data)
})
}
避免副作用
当函数产生了除了“接受一个值并返回一个结果”之外的行为时,称该函数产生了副作用。比如写文件、修改全局变量或将你的钱全转给了一个陌生人等。程序在某些情况下确实需要副作用这一行为,这时应该将这些功能集中在一起,不要用多个函数/类修改某个文件。用且只用一个 service 完成这一需求。
Bad:
const addItemToCart = (cart, item) => {
cart.push({ item, date: Date.now() })
}
Good:
const addItemToCart = (cart, item) => {
return [...cart, { item, date: Date.now() }]
}
避免条件判断
这看起来似乎不太可能。大多人听到这的第一反应是:“怎么可能不用 if 完成其他功能呢?”许多情况下通过使用多态(polymorphism)可以达到同样的目的。第二个问题在于采用这种方式的原因是什么。答案是我们之前提到过的:保持函数功能的单一性。
Bad:
class Airplane {
//...
getCruisingAltitude() {
switch (this.type) {
case '777':
return getMaxAltitude() - getPassengerCount()
case 'Air Force One':
return getMaxAltitude()
case 'Cessna':
return getMaxAltitude() - getFuelExpenditure()
}
}
}
Good:
class Airplane {
//...
}
class Boeing777 extends Airplane {
//...
getCruisingAltitude() {
return getMaxAltitude() - getPassengerCount()
}
}
class AirForceOne extends Airplane {
//...
getCruisingAltitude() {
return getMaxAltitude()
}
}
class Cessna extends Airplane {
//...
getCruisingAltitude() {
return getMaxAltitude() - getFuelExpenditure()
}
}
使用 ES6/ES7 新特性
箭头函数
Bad:
function foo() {
// code
}
Good:
let foo = () => {
// code
}
模板字符串
Bad:
var message = 'Hello ' + name + ', it\'s ' + time + ' now'
Good:
const message = `Hello ${name}, it's ${time} now`
解构
Bad:
var data = { name: 'dys', age: 1 }
var name = data.name,
age = data.age
Good:
const data = {name:'dys', age:1}
const {name, age} = data
使用 ES6 的 classes 而不是 ES5 的 Function
典型的 ES5 的类(function)在继承、构造和方法定义方面可读性较差,当需要继承时,优先选用 classes。
Bad:
// 那个复杂的原型链继承就不贴代码了
Good:
class Animal {
constructor(age) {
this.age = age
}
move() { /* ... */ }
}
class Mammal extends Animal {
constructor(age, furColor) {
super(age)
this.furColor = furColor
}
liveBirth() { /* ... */ }
}
class Human extends Mammal {
constructor(age, furColor, languageSpoken) {
super(age, furColor)
this.languageSpoken = languageSpoken
}
speak() { /* ... */ }
}
Async/Await 是比 Promise 和回调更好的选择
回调不够整洁,并会造成大量的嵌套,ES6 内嵌了 Promises,但 ES7 中的 async 和 await 更胜过 Promises。
Promise 代码的意思是:“我想执行这个操作,然后(then)在其他操作中使用它的结果”。await 有效地反转了这个意思,使得它更像:“我想要取得这个操作的结果”。我喜欢,因为这听起来更简单,所以尽可能的使用 async/await。
Bad:
require('request-promise').get('https://en.wikipedia.org/wiki/Robert_Cecil_Martin')
.then(function(response) {
return require('fs-promise').writeFile('article.html', response)
})
.then(function() {
console.log('File written')
})
.catch(function(err) {
console.error(err)
})
Good:
async function getCleanCodeArticle() {
try {
var request = await require('request-promise')
var response = await request.get('https://en.wikipedia.org/wiki/Robert_Cecil_Martin')
var fileHandle = await require('fs-promise')
await fileHandle.writeFile('article.html', response)
console.log('File written')
} catch(err) {
console.log(err)
}
}
Babel
ES6 标准发布后,前端人员也开发渐渐了解到了ES6,但是由于兼容性的问题,仍然没有得到广泛的推广,不过业界也用了一些折中性的方案来解决兼容性和开发体系问题。其中最有名的莫过于 Babel 了,Babel 是一个广泛使用的转码器,他的目标是使用 Babel 可以转换所有 ES6 新语法,从而在现有环境执行。
Use next generation JavaScript, today
Babel 不仅能够转换 ES6 代码,同时还是 ES7 的试验场。比如已经支持 async/await,使开发者更容易编写异步代码,代码逻辑和可读性简直不能太好了。虽然主流浏览器可能还需要一段时间才能支持这个异步编码方式,但是基于 Babel,开发者现在就可以在生产环境使用上它。这得益于 Babel 与 JavaScript 技术委员会保持高度一致,能够在 ECMAScript 新特性在标准化之前提供现实世界可用的实现。因此开发者能 在生产环境大量使用未发布或未广泛支持的语言特性,ECMAScript 也能够在规范最终定稿前获得现实世界的反馈,这种正向反馈又进一步推动了 JavaScript 语言向前发展。
Babel 最简单的使用方式如下:
# 安装 babel-cli 和 babel-preset-es2015 插件
npm install -g babel-cli
npm install --save babel-preset-es2015在当前目录下建立文件.babelrc,写入:
{
"presets": ['es2015']
}
更多的功能请参考官网。
ESLint
一个高质量的项目必须包含完善的 lint,如果一个项目中还是 tab、两个空格、四个空格各种混搭风,一个函数动不动上百行,各种 if、嵌套、回调好几层。加上前面提到的各种 JavaScript 糟粕和鸡肋,一股浓厚的城乡结合部风扑面而来,这还怎么写代码,每天调调代码格式好了。
这又怎么行呢,拿工资就得好好写代码,因此 lint 非常有必要,特别是对于大型项目,他可以保证代码符合一定的风格,有起码的可读性,团队里的其他人可以尽快掌握他人的代码。对于 JavaScript 项目而言,目前 ESLint 将是一个很好的选择。ESLint 的安装过程就不介绍了,请参考官网,下面讲一个非常严格的 ESLint 的配置,这是对上面编写简洁的 JavaScript 代码一节最好的回应。
{
"parser": "babel-eslint",
"env": {
"es6": true,
"browser": true
},
"extends": ["airbnb", "prettier", "plugin:react/recommended"],
"plugins": ["react", "prettier"],
"rules": {
"prettier/prettier": [
"error",
{
"semi": false,
"singleQuote": true,
"trailingComma": "es5"
}
],
// 一个函数的复杂性不超过 10,所有分支、循环、回调加在一起,在一个函数里不超过 10 个
"complexity": [2, 10],
// 一个函数的嵌套不能超过 4 层,多个 for 循环,深层的 if-else,都是罪恶之源
"max-depth": [2, 4],
// 一个函数最多有 3 层 callback,使用 async/await
"max-nested-callbacks": [2, 3],
// 一个文件的最大行数
"max-lines": ["error", {"max": 400}],
// 一个函数最多 5 个参数。参数太多的函数,意味着函数功能过于复杂,请拆分
"max-params": [2, 5],
// 一个函数最多有 10 个变量,如果超过了,请拆分之,或者精简之
"max-statements": [2, 10],
// 坚定的 semicolon-less 拥护者
"semi": [2, "never"],
"class-methods-use-this": 0,
"jsx-a11y/anchor-is-valid": [
"error",
{
"components": ["Link"],
"specialLink": ["to"]
}
],
"jsx-a11y/click-events-have-key-events": 0,
"jsx-a11y/no-static-element-interactions": 0,
"arrow-parens": 0,
"arrow-body-style": 0,
"import/extensions": 0,
"import/no-extraneous-dependencies": 0,
"import/no-unresolved": 0,
"react/display-name": 0,
"react/jsx-filename-extension": [1, {"extensions": [".js", ".jsx"]}],
"react/prop-types": 0
}
}
Prettier
Prettier 一个 JavaScript 格式化工具. 它的灵感来源于 refmt,它对于 ES6、ES7、 JSX 和 Flow 的语言特性有着高级的支持。通过将 JavaScript 解析为 AST 并且基于 AST 美化和打印,Prettier 会丢掉几乎全部的原始的代码风格,从而保证 JavaScript 代码风格的一致性,你可以先感受一下。
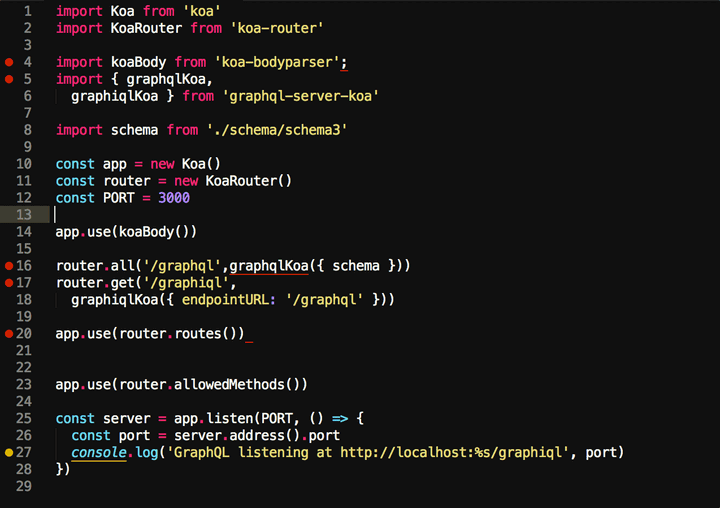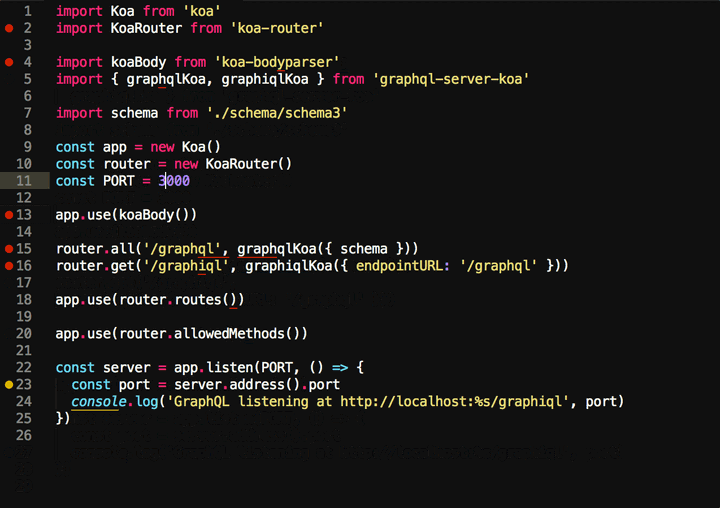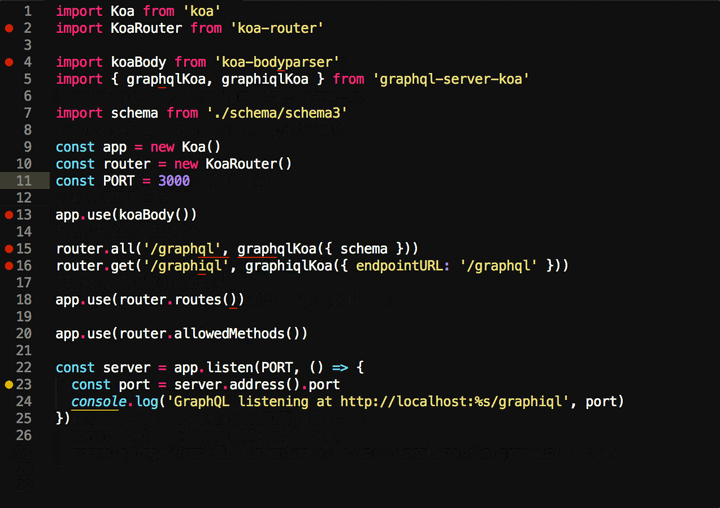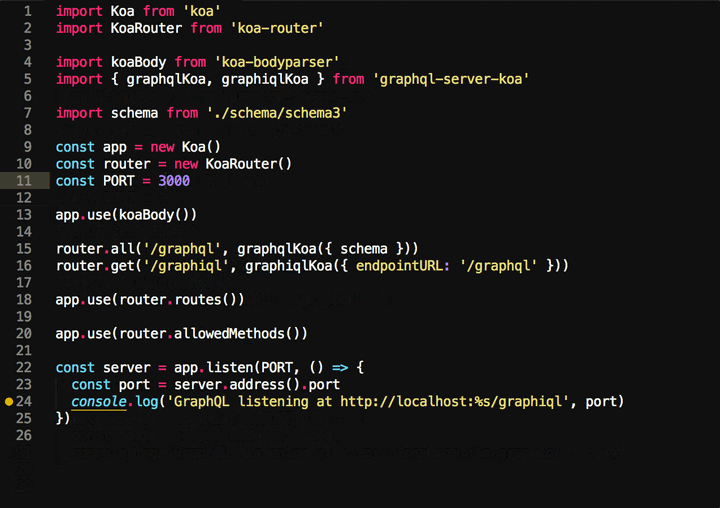
自动格式化代码,不管你原先的代码格式乱成什么样,他都会格式化成一样的,这个功能 非常棒,真的非常棒。以后我们再也不用关心代码格式的问题了。
ESLint 和 Prettier 确定了以后,一定要加到 pre commit hook 里面,因为人都是懒惰的,不要指望所有工程师都会主动去执行 ESLint 和 Prettier,所以新建了下面的 .pre-commit 文件,在 package.json 的scripts 的 postinstall 时 soft link 到 .git/hooks/pre-commit,这样在 pre commit 时会自动执行以下脚本。尽量在项目初始阶段就加入 pre commit hook,在项目中途加入可能会遇到团队的反对,执行起来较难。这也是面试的时候可以关注的一个地方,我们提高效率需要切实可行的手段,需要落到实处。
ESLint 和 Prettier 确定了以后,一定要加到 pre commit hook 里面,因为人都是懒惰的,不要指望所有工程师都会主动去执行 ESLint 和 Prettier,所以新建了下面的 .pre-commit 文件,在 package.json 的scripts 的 postinstall 时 soft link 到 .git/hooks/pre-commit,这样在 pre commit 时会自动执行以下脚本。尽量在项目初始阶段就加入 pre commit hook,在项目中途加入可能会遇到团队的反对,执行起来较难。这也是面试的时候可以关注的一个地方,我们提高效率需要切实可行的手段,需要落到实处,以上操作可以通过 husky 方便解决。
Install it along with husky:
yarn add lint-staged husky --devand add this config to your package.json:
{
"scripts": {
"precommit": "lint-staged"
},
"lint-staged": {
"*.{js,json,css,md}": ["prettier --write", "git add"]
}
}以上命令会在 pre commit 时先执行 Prettier 格式化,然后再执行 ESLint 的校验。如果想要在编辑时就格式化代码,Prettier 针对当前主流编辑器也有插件,请参考 这里 ,另外 ESLint 可以和 Prettier 很好的搭配使用,参考 eslint-plugin-prettier ,以上所有的配置和文件我都整理到了 这个项目 里,为了让大伙能够好好写代码,真的是操碎了心。
采用函数式编程
在谈到函数式编程及其有什么优点之前,我们先看我们常见的编程方式,imperative programming(命令式编程)有什么缺点。
function getData(col) {
var results = []
for (var i = 0; i < col.length; i++) {
if (col[i] && col[i].data) {
results.push(col[i].data)
}
}
return results
}
这段代码很简单,它过滤一个传入的数组,取出里面每个元素的 data 域,然后插入新的数组返回。相信很多人都会撰写类似的代码。它有很多问题:
- 我们在告诉计算机怎么样一步步完成一件事情,引入了循环,使用一个无关紧要的局部变量 i 控制循环(或者迭代器)。事实上我根本不需要关心这个变量怎么开始,怎么结束,怎么增长,这和我要解决的问题无关。
- 我们引入了一个状态 results,并不断变更这个状态。在每次循环的时候,它的值都会发生改变。
- 当我们的问题稍微改变的时候,比如我要添加一个函数,返回有关 data 长度的一个数组,那么我们需要仔细研读已有的代码,搞清楚整个逻辑,然后新写一个函数(多数情况下,工程师会启用「复制-粘贴-修改」大法。
- 这样的代码可读性很差,一旦内部状态超过 10 个,且互相依赖,要读懂它的逻辑并不容易。
- 这样的代码无法轻易复用。
如果是函数式编程,你大概会这么写:
function extract(filterFn, mapFn, col) {
return col.filter(filterFn).map(mapFn)
}
有没有觉得世界都清净了,这段代码非常简洁、明了,如果你了解 filter / map,几乎很难写错。这几乎就是一个通解,一台 machine,有了它,你可以解决任何数据集过滤和映射的问题。当然,你还可以这么抽象:
function extract(filterFn, mapFn) {
return function process(col) {
return col.filter(filterFn).map(mapFn)
}
}
注意,这两者虽然抽象出来的结果相似,但应用范围是不尽相同的。后者更像一台生产 machine 的 machine(函数返回函数),它将问题进一步解耦。这种解耦使得代码不仅泛化(generalization),而且将代码的执行过程分成两阶段,在时序上和接口上也进行了解耦。于是,你可以在上下文 A 中调用extract,在上下文 B 中调用 process,产生真正的结果。上下文 A 和上下文 B 可以毫不相干,A 的上下文只需提供 filterFn 和 mapFn(比如说,系统初始化),B 的上下文只需提供具体的数据集col(比如说 web request 到达时)。这种时序上的解耦使得代码的威力大大增强。接口上的解耦,就像旅游中用的万国插座一样,让你的函数能够一头对接上下文 A 中的系统,另一头对接上下文 B 中的系统。
讲到这里我们大致已经能看出函数式编程的一些特点:
- 提倡组合(composition),组合是王道。
- 每个函数尽可能完成单一的功能。
- 屏蔽细节,告诉计算机我要做什么,而不是怎么做。我们看 filter / map,它们并未暴露自身的细节。一个 filter 函数的实现,在单核 CPU 上可能是一个循环,在多核 CPU 上可能是一个 dispatcher 和 aggregator,但我们可以暂时忽略它的实现细节,只需了解它的功能即可。
- 尽可能不引入或者少引入状态。
这些特点运用得当的话,能够为软件带来:
- 更好的设计和实现。
- 更加清晰可读的代码。由于状态被大大减少,代码更容易维护,也带来更强的稳定性。
- 在分布式系统下有更好的性能。函数式编程一般都在一个较高的层次进行抽象,map / filter / reduce 就是其基础指令,如果这些指令为分布式而优化,那么系统无需做任何改动,就可以提高性能。
- 使得惰性运算成为可能。在命令式编程中,由于你明确告诉了 CPU 一步步该怎么操作,CPU 只能俯首听命,优化的空间已经被挤压;而在函数式编程里,每个函数只是封装了运算,一组数据从输入经历一系列运算到输出,如果没有人处理这些输出,则运算不会被真正执行。
优雅的敲 JS 代码的几个原则示例
一、条件语句
1,使用 Array.includes 来处理多重 || 条件
// ----- 一般 ------
if (fruit == 'apple' || fruit == 'strawberry' || fruit == 'banana' ) {
console.log('red');
}
//------- 优雅 ------
// 把条件提取到数组中
const redFruits = ['apple', 'strawberry', 'banana', 'cranberries'];
if (redFruits.includes(fruit)) {
console.log('red');
}2,少写嵌套,无效条件尽早返回
/_ 当发现无效条件时尽早返回 _/
function test(fruit, quantity) {
const redFruits = ['apple', 'strawberry', 'cherry', 'cranberries'];
if (!fruit) thrownewError('No fruit!'); // 条件 1:尽早抛出错误
if (!redFruits.includes(fruit)) return; // 条件 2:当 fruit 不是红色的时候,直接返回
console.log('red');
// 条件 3:必须是大量存在
if (quantity > 10) {
console.log('big quantity');
}
}3,使用函数默认参数和解构
// ------- 默认参数 一般 -------
function test(fruit, quantity) {
if (!fruit) return;
const q = quantity || 1; // 如果没有提供 quantity,默认为 1
console.log(`We have ${q}${fruit}!`);
}
// ------- 默认参数 优雅 -------
function test(fruit, quantity = 1) { // 如果没有提供 quantity,默认为 1
if (!fruit) return;
console.log(`We have ${quantity}${fruit}!`);
}
// ------- 解构 一般 -------
function test(fruit) {
// 如果有值,则打印出来
if (fruit && fruit.name) {
console.log (fruit.name);
} else {
console.log('unknown');
}
}
// ------- 解构 优雅 -------
// 解构 —— 只得到 name 属性
// 默认参数为空对象 {}
function test({name} = {}) {
console.log (name || 'unknown');
}4,相较于 switch,Map / Object 也许是更好的选择
//------ switch 一般 ---------
function test(color) {
// 使用 switch case 来找到对应颜色的水果
switch (color) {
case 'red':
return ['apple', 'strawberry'];
case 'yellow':
return ['banana', 'pineapple'];
case 'purple':
return ['grape', 'plum'];
default:
return [];
}
}
// ----- Object 优雅 -----
// 使用对象字面量来找到对应颜色的水果
const fruitColor = {
red: ['apple', 'strawberry'],
yellow: ['banana', 'pineapple'],
purple: ['grape', 'plum']
};
function test(color) {
return fruitColor[color] || [];
}
// ----- Map 优雅 -----
// 使用 Map 来找到对应颜色的水果
const fruitColor = newMap()
.set('red', ['apple', 'strawberry'])
.set('yellow', ['banana', 'pineapple'])
.set('purple', ['grape', 'plum']);
function test(color) {
return fruitColor.get(color) || [];
}
// ----- filter 优雅 -----
const fruits = [
{ name: 'apple', color: 'red' },
{ name: 'strawberry', color: 'red' },
{ name: 'banana', color: 'yellow' },
{ name: 'pineapple', color: 'yellow' },
{ name: 'grape', color: 'purple' },
{ name: 'plum', color: 'purple' }
];
function test(color) {
// 使用 Array filter 来找到对应颜色的水果
return fruits.filter(f => f.color == color);
}5,使用 Array.every 和 Array.some 来处理全部/部分满足条件
// ------- 直接优雅 --------
const fruits = [
{ name: 'apple', color: 'red' },
{ name: 'banana', color: 'yellow' },
{ name: 'grape', color: 'purple' }
];
function test() {
// 条件:(简短形式)所有的水果都必须是红色
const isAllRed = fruits.every(f => f.color == 'red');
// 条件:至少一个水果是红色的
const isAnyRed = fruits.some(f => f.color == 'red');
console.log(isAllRed); // false
}函数式编程简介
什么是函数式编程?它有什么优点?
在谈到函数式编程及其有什么优点之前,我们先看我们常见的编程方式,imperative programming(命令式编程)有什么缺点。
function getData(col) {
var results = [];
for (var i=0; i < col.length; i++) {
if (col[i] && col[i].data) {
results.push(col[i].data);
}
}
return results;
}这段代码很简单,它过滤一个传入的数组,取出里面每个元素的 data 域,然后插入新的数组返回。相信很多人都会撰写类似的代码。它有很多问题:
-
我们在告诉计算机怎么样一步步完成一件事情。我们引入了循环,使用一个无关紧要的局部变量 i 控制循环(或者迭代器)。事实上我根本不需要关心这个变量怎么开始,怎么结束,怎么增长,这和我要解决的问题无关。
-
我们引入了一个状态 results,并不断变更这个状态。在每次循环的时候,它的值都会发生改变。
-
当我们的问题稍微改变的时候,比如我要添加一个函数,返回有关
data长度的一个数组,那么我们需要仔细研读已有的代码,搞清楚整个逻辑,然后新写一个函数(多数情况下,工程师会启用「复制-粘贴-修改」大法。 -
这样的代码撰写正确并不容易。
-
这样的代码可读性很差,一旦内部状态超过 10 个,且互相依赖,要读懂它的逻辑并不容易。
-
这样的代码无法轻易复用。
如果是函数式编程,你大概会这么写:
function getData(col) {
return col
.filter(item => item && item.data)
.map(item => item.data);
}我先对要处理的数组进行 filter,然后 map,得到结果。这段代码简洁,明了,如果你了解 filter / map,几乎很难写错。
而且你很容易重构,使其变得更加通用:
function extract(filterFn, mapFn, col) {
return col => col.filter(filterFn).map(mapFn);
}
const validData = item => item && item.data;
const getData = extract.bind(this, validData, item => item.data);
const getDataLength = extract.bind(this, validData, item => item.data.length);相比之前的代码,结构更清晰,更容易扩充,更符合 open-close 原则。
讲到这里我们大致已经能看出函数式编程的一些特点:
-
提倡组合(composition)
-
每个函数尽可能完成单一的功能
-
屏蔽细节,告诉计算机我要做什么,而不是怎么做。我们看 filter / map,它们并未暴露自身的细节。一个 filter 函数的实现,在单核 CPU 上可能是一个循环,在多核 CPU 上可能是一个 dispatcher 和 aggregator,但我们可以暂时忽略它的实现细节,只需了解它的功能即可。
-
尽可能不引入或者少引入状态。
这些特点运用得当的话,能够为软件带来:
-
更好的设计和实现
-
更加清晰可读的代码。由于状态被大大减少,代码更容易维护,也带来更强的稳定性。
-
在分布式系统下有更好的性能。函数式编程一般都在一个较高的层次进行抽象,map / filter / reduce 就是其基础指令,如果这些指令为分布式而优化,那么系统无需做任何改动,就可以提高性能。
-
使得惰性运算成为可能。在命令式编程中,由于你明确告诉了 CPU 一步步该怎么操作,CPU 只能俯首听命,优化的空间已经被挤压;而在函数式编程里,每个函数只是封装了运算,一组数据从输入经历一系列运算到输出,如果没有人处理这些输出,则运算不会被真正执行。
我们看一个例子:
lazy(bigCollection)
.filter(validItem)
.map(processItem)
.skip(2)
.take(3)对于上述的代码,无论 bigCollection 有多大,循环都只会执行有限的次数。
我们再看一个例子:
const Stream = Rx.Observable;
Stream.from(urls)
.flatMap(url =>
new Stream.create(stream => {
request(url, (error, response, body) => {
if (error) return stream.onError(error);
stream.onNext({ url, body });
});
})
.retry(3)
.catch(error => Stream.Just({ url, body: null }))
)这段代码用到了 Observable,Observable 的概念我们先放在一边,感兴趣的同学可以去看 FRP(functional reactive programming),这里我们认为 Observable 就是一个 stream。我们有一个 url 列表,需要获取每个 url 对应的 response body。每个 request 都至多 retry 3 次,如果 3 次还失败,就返回空。
同样的代码如果你用传统的方式去撰写,逻辑和脉络不会如此清晰。
有了以上的这些例子,相比大家对函数式编程有了一个初步的认识。现在我们回归本源,讲讲什么是函数(function)。
在我们初高中学函数的时候,我们知道函数有作用域和值域。对于一个函数 f(x) = x * x,如果其作用域是一切整数,那么函数的值域就是一切正整数。这里,整数和正整数就是这个函数输入和输出的类型。
我们这里讲的函数和数学里的函数几乎等价,都是将一个域的值(定义域)经过变换(transformation)映射到另一个域的值(值域)。数学函数最大的特点是如果一个函数 f(x) 的值域是另一个函数 g(x) 的定义域,那么这两个函数可以组合:
g(f(x)) = (g f)(x)
h(j(k(x, y, ...)))
= h((j k)(x, y, ...))
= (h j k)(x, y, ...)
= (h j) (k(x, y, ...))函数式编程也吸收了组合(composition)的特点。组合这个词大家听起来耳熟是不是,对滴,在面向对象编程中,最佳实践之一就是:多组合,少继承。这是多么奇怪的最佳实践啊,继承是面向对象的核心功能,但我们却要费尽心思尽可能少用这个核心功能?这是应为继承在不断降低代码的复用程度,如果要 DRY(Don't Repeat Yourself),要么使用 Mixin 做功能上的集成,要么把重复的代码移到基类,但这又会有问题,你也许并不能改写基类,或者即使你能改写基类,为了一个上层的功能改写基类又违反 Open-close principle,真是左右为难。所以我们提倡组合。
组合是一个很有威力的工具。上述的 h,j,k 是三个基本的函数,通过组合,我们能够衍生出一系列新的函数:(j k),(h j),(h j k),就像搭建乐高积木一样,大大扩展了功能。
很多函数式编程语言都提供专门的语法,如 compose(clojure),<<<(haskell 等。
上面的例子我们已经用到了组合,我们再看一个例子:
const getComponentPath = (name, basePath) => path.join(basePath, name);
const getModelPath = getComponentPath.bind(null, 'models');
const getConfigPath = getComponentPath.bind(null, 'config');
const getConfigFile = (p, name) => path.join(getConfigPath(p), name);
const readTemplate = filename => fs.readFileAsync(filename, ENCODING);
const processTemplate = params =>
promise => promise.then(content => mustache.render(content, params));
const writeFile = filename =>
promise => promise.then(
content => fs.writeFileAsync(filename, content, ENCODING)
);
const processConfigTemplate = R.pipe(
getConfigFile,
readTemplate,
processTemplate(PARAMS),
writeFile(getConfigFile(topDir, 'config.yml'))
);
processConfigTemplate(topDir, 'config.mustache')
.then(() => console.log('done!'))
.catch(err => console.log(err));这段代码的功能非常简单,读取项目里的 config 目录下的 config.mustache 文件,生成 config.yml。很多人上手写这个功能时肯定是将其写成一个函数,而在这里我却写下了九个函数,与其直接相关的有六个函数。主体功能 processConfigTemplate 是若干的函数的直接组合。这里没有使用 compose,而是使用了另一个概念 pipe。它也用于组合函数,只不过它组合的方向和 compose 正好相反,比较方便书写。你可以这里理解 pipe,一组输入先后经过 pipe 中的每个函数,上一个函数的输入作为下一个函数的输出,这样不断执行下去,最后得到一个输出。
这样的代码可读性非常强,几乎不用注释,一个刚接手代码的javascript程序员就能看懂;而且它的复用性很强,里面的任何一个部分都可以用在其他地方,而且如果需求发生改变,比如我们不用 mustache 模板,改用 handlebar,整个逻辑里面,我们只需要替换,或者新加一个 processTemplate 函数。由于功能单一,每个函数的可测性非常强,很容易写 test case。如果让你维护这样的代码,那真是世界上最幸福的事情。
有同学可能会说,这样的代码怎么调试?我们回过头来看这个代码,自己想一想,这样的代码需要调试么?只要编译(抱歉,javascript 没有编译阶段)通过,你就几乎可以保证,这个代码是可以工作的。我是边写这篇手稿边写的代码,为简洁起见,没有提供一些库加载的语句,但我相信这个代码写下来,没有什么大问题。很多初入行的工程师非常依赖 IDE 的单步跟踪功能,我可以负责任地告诉你,随着你的成长,一定要减少直到消除对单步跟踪的依赖,未来的程序是单步跟踪无法调试的。如果你的系统运行在一个分布式的环境,上百台机器,上千个 core,你怎么 step in / step out?不现实。我觉得:
优秀的工程师脑袋里(或者在纸上)构思出代码的脉络,一气呵成,一行行将代码写出来;而蹩脚的工程师则需要依赖 IDE 提供的单步跟踪功能一行行把代码调出来。一个是写,一个是调,高下立现。
你之所以需要单步跟踪来调程序,是因为程序中出现来太多的中间状态,你无法追踪这些中间状态的值,所以需要借助 IDE 的力量。但函数式编程能够有效地帮助你控制甚至消灭中间状态,像上面的例子,你都没有中间状态了,还跟踪什么?
我们再看这段程序里面为了方便函数间组合出现的一些概念:
-
curry
-
closure
库里的照片
先看 curry。话说现在 curry 的手感火热得要死,各种无理由要人命的三分…抱歉,我跑题了,此处要将的 curry 不是勇士的 curry,而是函数式编程里的柯里化,在 wikipeida 里,是这么介绍 currying 的:
In mathematics and computer science, currying is the technique of translating the evaluation of a function that takes multiple arguments (or a tuple of arguments) into evaluating a sequence of functions, each with a single argument.
通俗地说就是把有多个参数的函数转换成一系列只有一个参数的函数。在 javascript 里面,可以使用 bind 进行柯里化。
比如这句:
const getConfigPath = getComponentPath.bind(null, 'config');在进行函数式编程的时候,函数参数的位置很有讲究,需要精心安排,把辅助性的,可以柯里化的参数放在前面,以方便绑定。
另一种柯里化的方法,或者说,更正统的方法是通过高阶函数来完成。高阶函数是指一个函数可以接受另一个函数作为参数,或者返回一个函数作为结果。我们看这句:
const processTemplate = params =>
promise => promise.then(content => mustache.render(content, params));在 writeFile 这个函数里,我们接受 params 作为参数,返回一个接受 Promise 作为参数,并返回 Promise 的函数。高阶函数在函数式编程里面非常重要,事实上,如果你平日里使用 javascript 开发,尤其是 nodejs,几乎每天都会跟高阶函数打交道。
当一个函数返回另一个函数时,我们发现,返回的那个函数的函数体里面使用了 processTemplate 传进来的参数。这是函数式编程中又一个很重要的概念:闭包(closure)。闭包是指变量的作用域在整个 lexical scope 里始终有效,比如说函数A返回函数B,函数B可以在任何时候访问A的局部变量,包括参数,这就是闭包。闭包是函数式编程经常使用的模式,他能帮助你延迟计算,把计算推迟到需要的时候再进行。
什么是延迟计算呢?我们看一个例子:
const authMiddleware = config =>
(req, res, next) => {
if (config.auth.strategy === 'jwt') {
const token = getToken(req.headers);
jwt.verify(token, secret, ...);
}
}用过 expressjs 的人大概能看出来,这个函数用来生成一个 expressjs 的 middleware。正常你写 middleware 时,有全部的上下文,你会直接这么写:
// config is define in this module somewhere
app.use((req, res, next) => {
if (config.auth.strategy === 'jwt') {
...
}
});但如果你在写一个框架,在撰写这个 middleware 时,使用者还没有创建 app,也没有生成 config 对象,你唯一能做的就是,假定调用者会传给你一个合法的 config 对象,你为她返回一个 middleware 供其使用。这就是把计算延迟到需要的时刻。
清楚了柯里化和闭包后,我们再看它们对组合的贡献。在 processConfigTemplate 里面:
const processConfigTemplate = R.pipe(
getConfigFile,
readTemplate,
processTemplate(PARAMS),
writeFile(getConfigFile(topDir, 'config.yml'))
);我们要计算 config 的文件名,获取其内容,使用参数处理模板,写成新的文件,所有的中间过程,如果想要能够把它们组合起来,那就必须让彼此之间的输入输出适配(adapt),而要完美地适配,少不了柯里化 / 闭包这样的概念。这样,processTemplate,writeFile 这样的函数不失其通用性,在其它场合也能使用。有了这些基本函数,我可以轻易地提供 processJadeTemplate,processMustacheTemplate,writeDb 等等,组合出来各种各样的功能逻辑。
我们停下来想一想,如果是 OOP,你会怎么做?你怎么设计 interface,如何定义各种类,和类的行为,怎么抽象,用什么设计模式,adapter,chain of responsibility,等等。然后你会提醒自己,不要过度设计;之后需要扩展的时候,你又不得不破坏 open close principle,或抽象或重构。总之,为了达到同样的目的,OOP 就像宗教改革前的天主教,处处是繁文缛节,干点什么都像在举行仪式;而 FP 则像马丁路德的新教,简单,明了。
函数式编程有一些非常有趣的特性,比如说,如果你的函数的输入参数和输出参数有相同的类型,这是一种很特殊的函数,叫 monoid。比如说,javascript 里面的 Promise,它接受一个 Promise 并返回另一个 Promise,所以它是一个 monoid,而它又满足另外一些定律,它还是一个 Monad,或者更进一步,Either Monad。Promise 封装了一个值,在将来的某个时刻可以有成功(data)和失败(throw error)两种状态(有点薛定谔的猫的感觉)。这也是为什么正常你这样写代码:
fs.openFile(filename, encoding, (err1, data1) => {
if (err1) return console.log(err1);
processTemplate(data1, (err2, data2) => {
if (err2) return console.log(err2);
writeFile(filename, data2, encoding, (err3, data3) => {
if (err3) return console.log(err3);
console.log('Done!');
});
});
});而使用 Promise,代码的结构可以简化为:
fs.openFileAsync(filename, encoding)
.then(content => processTemplate(content))
.then(content => writeFile(filename, content, encoding))
.then(() => console.log('done!'))
.catch(err => console.log(err));我这里想说的不仅仅 Promise 可以用来解决 callback hell 这样的问题,而是:Promise 把我们一直以来头疼的错误处理给统一了!你可以一气呵成地组合你的代码,然后在一个统一的位置进行错误处理。这就是是 Monad 的威力!如果不是函数式编程的强大能力,你无法享受如此简洁的代码(仔细对比一下两种代码)。平日工作中,类似的结构有很多,不光是 callback hell,还有 if-else hell 等等。
函数式编程有很多很多概念,如 Monad,monoid,functor,applicative,curry 等等,会把你绕得云里雾里的。但所有这些概念被引入的本质都是为了组合(composition),在函数式编程的世界了,组合是王道,是无处不在的。
抽象的能力
人类的智商从低幼逐渐走向成熟的标志之一就是认识和运用数字的能力。当我们三四岁的时候,数数虽然能够熟练地对一百以内的数字随心所欲地倒背如流,但数字对孩童时代的我们仅仅还是数字,即便刚数完了自己桌前有 12 粒葡萄,吃掉了一粒,我们还得费力地再数一遍才能确定是 11 粒(别问我为啥这都门清)。在这个年龄,数字离开了具体的事物,对我们而言便不再具有任何意义。
随着年龄地增长,大脑的发育,和小学阶段的不断训练,我们开始能够随心所欲地运用数字,于此同时,我们甚至无法感受到它是一种对现实生活中的抽象,一斤白菜八毛钱,一斤芹菜一块钱,各买两斤,再来一瓶两块四的酱油,我们都能熟练地掏出六块钱,开开心心离开菜市场。
到了初高中,抽象已经从数字开始像更高层次递进。平面几何和解析几何把我们从数字代入到图形,而代数(从j具体的数字到抽象的字母)则把我们引领到了函数的层面。小学时代的难题:「我爸爸的年龄是我的三倍,再过十年,他的年龄就是我的两倍,问我现在年芳几许?」在这个时候就成了方程式的入门题目。如果我的年龄是x,我爸爸的年龄是y,可以这么列方程:
y = 3x
y + 10 = 2(x + 10)
然而,这样的方程式千千万万,每列一个我们就需要计算一个解。接下来我们进一步把问题正规化和抽象化:
y = a1x + b1
y = a2x + b2
这样我们就有了一个关于 x 的解: (b2 - b1) / (a1 - a2)。它就像一台 machine 一样,对于任何类似的问题,我们只需要套用之,就可以生产出来一个解。这便是公式(或者定理)。公式(或者定理)和其求证过程贯穿着我们的中学时代。
到了大学,抽象的程度又上升了一个巨大的台阶,我们从数字开始抽象出关系。微积分研究和分析事物的变化和事物本身的关系;概率论研究随机事件发生的可能性;离散数学研究数理逻辑,集合,图论等等。这些都是对关系的研究。中学时期的疑难杂症,到了大学阶段,都是被秒杀没商量的小儿科。
...
然而,并不是所有人都能适应这种抽象能力的升级。有时候你被困在某个层级(比如说,程序君的大学数学就没折腾利索,逃课毁一生啊)而无法突破。这时候,只能通过不断地练习去固化这种思维,然后在固化中找到其意义所在。这就像冰火岛上的张无忌被谢逊逼着背诵武功秘籍或者三岁的你在努力地来回熟悉每一个数字一样。它们在那个时刻没有意义,等到需要有意义的那一天来临,你会产生顿悟。
同样地,写代码需要抽象能力,无比需要。如果你不想一辈子都做一个初级码农,如果你想写出来一些自己也感觉到满意的代码,如果你想未来不被更高级的编码工具取代,你需要学会抽象。
抽象的第一重,是将具体问题抽象成一个函数(或者类)用程序解决。这个层次的抽象,相信每个自称软件工程师的程序员都能做到:一旦掌握了某个语言的语法,就能将问题映射成语法,写出合格的代码。这有些像小学生对数字的理解:可以随心所欲地应用而不会困惑。
抽象的第二重,是撰写出可以解决多个问题的函数,这好比前文中提到的二元一次方程的通解 (b2 - b1) / (a1 - a2) 一样,你创建出一个 machine,这个 machine 能处理其能解决的一切问题。就像这样的代码:
function getData(col) {
var results = [];
for (var i=0; i < col.length; i++) {
if (col[i] && col[i].data) {
results.push(col[i].data);
}
}
return results;
}
当我们将其独立看待时,它似乎已经很简洁,对具体要解决的问题的映射很精确。然而,当我将循环,循环中的过滤,过滤结果的处理抽象出来,就可以产生下面的代码:
function extract(filterFn, mapFn, col) {
return col.filter(filterFn).map(mapFn);
}
这就是一个通解,一台 machine。有了它,你可以解决任何数据集过滤和映射的问题。当然,你还可以这么抽象:
function extract(filterFn, mapFn) {
return function process(col) {
return col.filter(filterFn).map(mapFn);
}
}
注意,这两者虽然抽象出来的结果相似,但应用范围是不尽相同的。后者更像一台生产 machine 的 machine(函数返回函数),它将问题进一步解耦。这种解耦使得代码不仅泛化(generalization),而且将代码的执行过程分成两阶段,在时序上和接口上也进行了解耦。于是,你可以在上下文 A 中调用extract,在上下文 B 中调用 process,产生真正的结果。上下文 A 和上下文 B 可以毫不相干,A 的上下文只需提供 filterFn 和 mapFn(比如说,系统初始化),B 的上下文只需提供具体的数据集col(比如说,web request 到达时)。这种时序上的解耦使得代码的威力大大增强。接口上的解耦,就像旅游中用的万国插座一样,让你的函数能够一头对接上下文 A 中的系统,另一头对接上下文 B 中的系统。
(当然,对于支持 currying 的语言,两者其实是等价的,我只是从思维的角度去看待二者的不同)。
抽象的第二重也并不难掌握,OOP里面的各种 pattern,FP 里面的高阶函数,都是帮助我们进行第二重抽象的有力武器。
抽象的第三重,是基础模型的建立。如果说上一重抽象我们是在需要解决的问题中寻找共性,那么这一重抽象我们就是在解决方法上寻找共性和联系。比如说建立你的程序世界里的 contract。在软件开发中,最基本的 contract 就是类型系统。像 java,haskell 这样的强类型语言,语言本身就包含了这种 contract。那像 javascript 这样的弱类型语言怎么办?你可以自己构建这种 contract:
function array(a) {
if (a instanceof Array) return a;
throw new TypeError('Must be an array!');
}
function str(s) {
if (typeof(s) === 'string' || s instanceof String) return s;
throw new TypeError('Must be a string!');
}
function arrayOf(type) {
return function(a) {
return array(a).map(str);
}
}
const arrayOfStr = arrayOf(str);
// arrayOfStr([1,2]) TypeError: Must be a string!
// arrayOfStr(['1', '2']) [ '1', '2' ]
再举一个例子。在程序的世界里,no one's perfect。你从数据库里做一个查询,有两种可能(先忽略异常):结果包含一个值,或者为空。这种二元结果几乎是我们每天需要打交道的东西。如果你的程序每一步操作都产生一个二元结果,那么你的代码将会在 if...else 的结构上形成一个金字塔:
function process(x) {
const a = step1(x);
if (a) {
const b = step2(a);
if (b) {
const c = step3(b);
if (c) {
const d = step4(c):
if (d) {
...
} else {
...
}
} else {
...
}
} else {
...
}
} else {
...
}
}
很难读,也很难写。这种二元结构的数据能不能抽象成一个数据结构呢,可以。你可以创建一个类型:Maybe,包含两种可能:Some 和 None,然后制定这样的 contracts:stepx() 可以接受 Maybe,也会返回 Maybe,如果接受的 Maybe 是一个 None,那么直接返回,否则才进行处理。新的代码逻辑如下:
function stepx(fn) {
return function(maybe) {
if (maybe isinstanceof None) return maybe;
return fn(maybe);
}
}
const step1x = stepx(step1);
const step2x = stepx(step2);
const step3x = stepx(step3);
const step4x = stepx(step4);
const process = R.pipe(step1, step2, step3, step4);
至于这个 Maybe 类型怎么撰写,就先不讨论了。
(注:Haskell 就有 Maybe 这种类型)
抽象的第四重,是制定规则,建立解决整个问题空间的一个世界,这就是元编程(metaprogramming)。谈到元编程,大家想到的首先是 lisp,clojure 等这样「程序即数据,数据即程序」的可以在运行时操作语法数的语言。其实不然。没有很强的抽象能力的 clojure 程序员并不见得比一个有很强抽象能力的 javascript 程序员能写出更好的元编程的程序。这就好比吕布的方天画戟放在你我手里只能用来自拍一样。
元编程的能力分成好多阶段,我们这里说说入门级的,不需要语言支持的能力:将实际的问题抽象成规则的能力,换句话说,在创立一家公司(解决问题)之前,你先创立公司法(建立问题空间的规则),然后按照公司法去创立公司(使用规则解决问题)。
比如说你需要写一个程序,解析各种各样,规格很不统一的 feed,将其处理成一种数据格式,存储在数据库里。源数据可能是 XML,可能是 json,它们的字段名称的定义很不统一,就算同样是 XML,同一个含义的数据,有的在 attribute 里,有的在 child node 里,我们该怎么处理呢?
当然我们可以为每种 feed 写一个处理函数(或者类),然后尽可能地复用其中的公共部分。然而,这意味着每新增一个 feed 的支持,你要新写一部分代码。
更好的方式是定义一种语言,它能够将源数据映射到目标数据。这样,一旦这个语言定义好了,你只需写一个 Parser,一劳永逸,以后再加 feed,只要写一个使用该语言的描述即可。下面是一个 json feed 的描述:
{
"video_name": "name",
"description": "longDescription",
"video_source_path": ["renditions.#max_renditions.url", "FLVURL"],
"thumbnail_source_path": "videoStillURL",
"duration": "length.#ms2s",
"video_language": "",
"video_type_id": "",
"published_date": "publishedDate",
"breaks": "",
"director": "",
"cast": "",
"height": "renditions.#max_renditions.frameHeight",
"width": "renditions.#max_renditions.frameWidth"
}
这是一个 XML feed 的描述:
{
"video_name": "title.0",
"description": "description.0",
"video_source_path": "media:group.0.media:content.0.$.url",
"thumbnail_source_path": "media:thumbnail.0.$.url",
"duration": "media:group.0.media:content.0.$.duration",
"video_language": "",
"video_type_id": "",
"published_date": "",
"breaks": "",
"director": "",
"cast": "",
"playlist": "mcp:program.0",
"height": "media:group.0.media:content.0.$.height",
"width": "media:group.0.media:content.0.$.width"
}
具体这个描述语言的细节我就不展开,但是通过定义语言,或者说定义规则,我们成功地把问题的性质改变了:从一个数据处理的程序,变成了一个 Parser;输入从一个个 feed,变成了一种描述语言的源文件。只要 Parser 写好,问题的解决是一劳永逸的。你甚至可以再为这个语言写个 UI,让团队里的非工程师也能很方便地支持新的 feed。
总结
软件工程已经发展了 50 多年,至今仍在不断前进。现在,把这些原则当作试金石并运用在团队实际开发中,尝试将他们作为团队代码质量考核的标准之一吧。
One more thing:这些准则不会让你立刻变成一个优秀的工程师,长期奉行他们也并不意味着你能够高枕无忧。千里之行,始于足下。我们需要时常和同行们进行代码评审,不断优化自己的代码,不要惧怕改善代码质量所需付出的努力。长此以往,你不仅会看得懂自己半年前写的代码,还将获得同行的赞许,你的程序之路会走的更远!















 778
778











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











