







文章目录
前言
网站分析
图片获取
合成pdf
前言
辛辛苦苦地找到了自己需要的答案,但却无法下载,便打算分析一下网站将内容爬取出来,自己简单实现了自己的需求,现在把代码拿出来分享分享。
网站分析
好不容易在360doc中找到了完整版的答案,更值得高兴的是,它的结构很简单,图片没有百度文库那样反爬措施;这也是为什么我用java来爬取的原因之一。
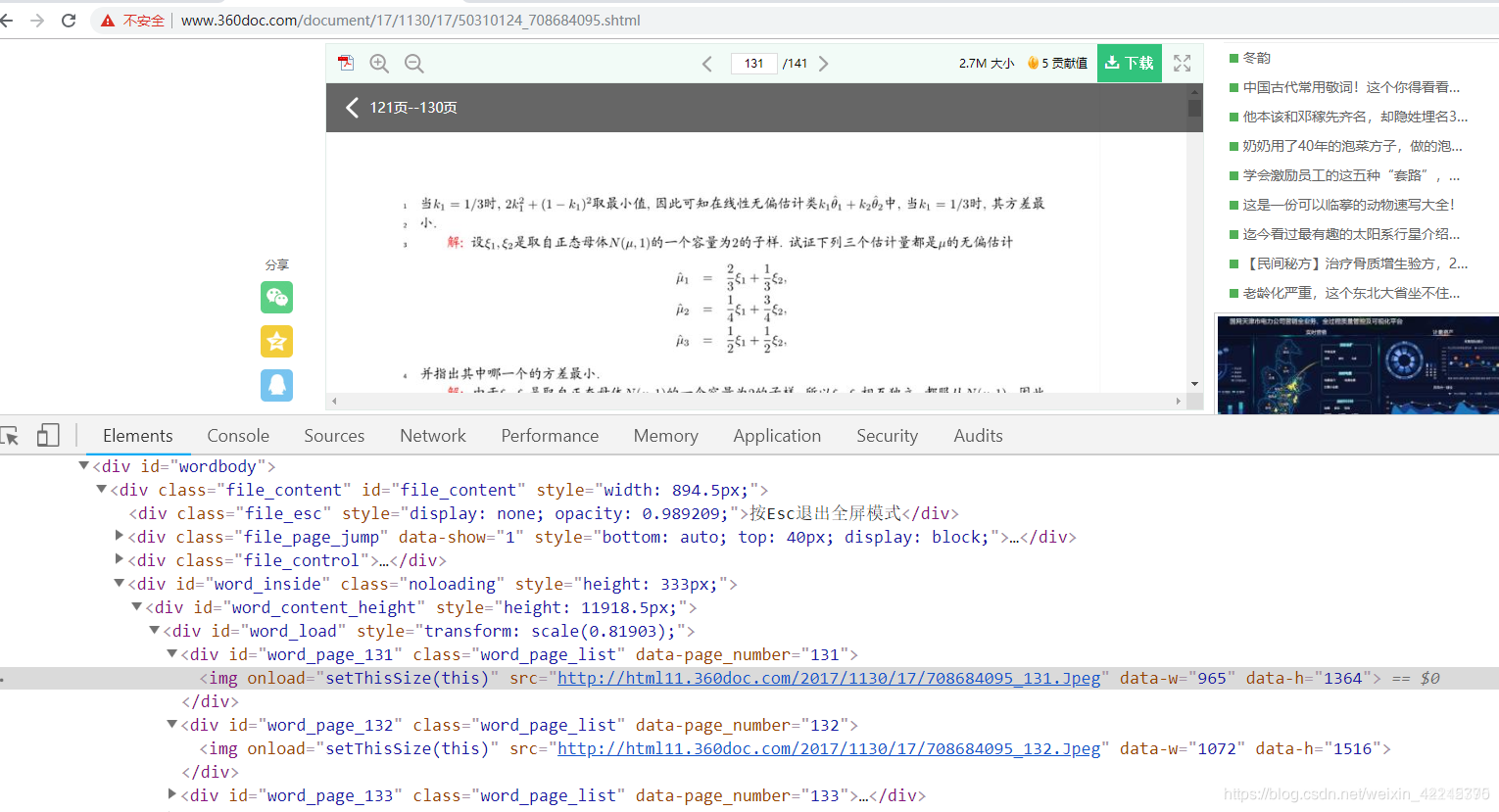
从上图不难看出,src指向的就是需要的图片,而文件名与页码对应,循环起来很方便。
图片获取
将url取出,循环结合文件名即可
public static void main(String[] args) {
try {
for(int i=1;i<=141;i++){
URL url = new URL("http://html11.360doc.com/2017/1130/17/708684095_"+i+".Jpeg");
File file = new File("F:/概率论与数理统计/"+i+".jpeg");
download(url,file);
}
} catch (MalformedURLException e) {
e.printStackTrace();
}
}
其中封装的一个文件下载方法
private static void download(URL url,File file){
FileOutputStream fos = null;
InputStream is = null;
try {
URLConnection conn = url.openConnection();
conn.connect();
is = conn.getInputStream();
byte[] bytes = new byte[10240];
fos = new FileOutputStream(file);
int temp = 0;
while( (temp = is.read(bytes)) != -1){
fos.write(bytes,0,temp);
}
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally{
try {
if(is != null)
is.close();
if(fos != null)
fos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
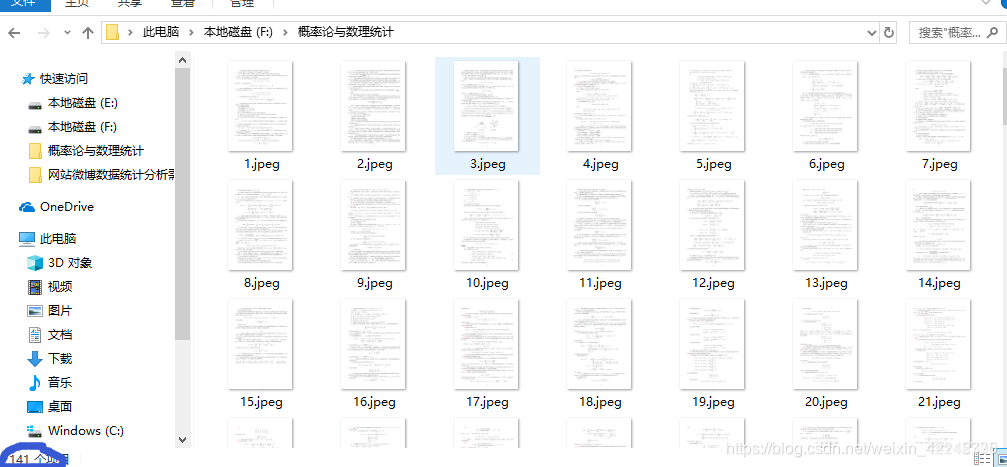
这样轻轻松松就获得了所有的图片
合成pdf
这里借鉴了一下网友们图片合并pdf的方法,通过Meaven使用的jar包
<dependency>
<groupId>com.lowagie</groupId>
<artifactId>itext</artifactId>
<version>2.1.7</version>
</dependency>
另准备一个类用于合并,main方法也很简单,提供关键的路径即可
public static void main(String[] args) {
long time1 = System.currentTimeMillis();
toPdf("F:/概率论与数理统计/", "F:/概率论与数理统计答案.pdf");
long time2 = System.currentTimeMillis();
int time = (int) ((time2 - time1)/1000);
System.out.println("执行了:"+time+"秒!");
}
其中的toPdf方法将文件夹下的所有图片合并到一个pdf当中
public static void toPdf(String imageFolderPath, String pdfPath) {
// 创建文档
Document doc = new Document(null, 0, 0, 0, 0);
// 输入流
FileOutputStream fos = null;
try {
// 图片地址
String imagePath = null;
fos = new FileOutputStream(pdfPath);
// 写入PDF文档
PdfWriter.getInstance(doc, fos);
// 实例化图片
Image image = null;
// 读取图片流
BufferedImage bi = null;
// 获取图片文件夹对象并对文件列表按整数排序
File dir = new File(imageFolderPath);
ArrayList<File> files = new ArrayList<File>(Arrays.asList(dir.listFiles()));
files.sort(new FileIntComparator());
// 循环获取图片文件夹内的图片
for (File file : files) {
if (file.getName().endsWith(".png")
|| file.getName().endsWith(".jpg")
|| file.getName().endsWith(".gif")
|| file.getName().endsWith(".jpeg")
|| file.getName().endsWith(".tif")) {
//图片路径
imagePath = imageFolderPath + file.getName();
// 读取图片流
bi = ImageIO.read(new File(imagePath));
// 根据图片大小设置文档大小
doc.setPageSize(new Rectangle(bi.getWidth(), bi
.getHeight()));
// 实例化图片
image = Image.getInstance(imagePath);
// 添加图片到文档
doc.open();
doc.add(image);
}
}
} catch (IOException e) {
e.printStackTrace();
} catch (BadElementException e) {
e.printStackTrace();
} catch (DocumentException e) {
e.printStackTrace();
} finally {
try {
if(doc != null)
doc.close();
if(fos != null)
fos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
原本的合并成pdf是按字典序,但我命名的时候是按整数命名,所以这里合并也得按整数大小排序,就单独写了个比较器用于排序
public class FileIntComparator implements Comparator<File>{
@Override
public int compare(File o1, File o2) {
int i1 = Integer.parseInt(o1.getName().substring(0,o1.getName().lastIndexOf('.')));
int i2 = Integer.parseInt(o2.getName().substring(0, o2.getName().lastIndexOf('.')));
return i1 - i2;
}
public static void main(String[] args) {
File dir = new File("F:/概率论与数理统计");
ArrayList<File> files = new ArrayList<File>(Arrays.asList(dir.listFiles()));
files.sort(new FileIntComparator());
for(File file:files){
System.out.println(file.getName().substring(0,file.getName().lastIndexOf('.')));
}
}
}
最终得到顺序的pdf















 203
203











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









