









一、指定数组大小与变长数组
在 C99 标准之前,声明数组时只能在方括号中使用 整形常量表达式。
所谓整形常量表达式,是由整形常量构成的表达式。其中,
- sizeof 表达式被认为是整形常量。
- const 修饰的变量不能认为是常量,在 C99 之前不能用于数组定义中。
- 表达式的值必须大于0。
/* 示例 */
float a1[5]; // 可以
float a2[5*2+1]; // 可以
float a3[sizeof(int)+1]; // 可以
float a4[-4] // 不可以
float a5[0] // 不可以
float a6[2.5] // 不可以
float a7[(int)2.5] // 可以
ISO C90 中,’
//’ 注释代码的特性未加入到 C90 标准中,因此编译会报错。
从 C99 标准之后,允许声明一种 变长数组(variable-length array) 或简称为 VLA ,即数组方括号内可以使用变量。(C11 放弃了这一创新的举措,把 VLA 设定为可选,而不是语言必备的特性)
变长数组中需要注意的:
- 变长数组必须是自动存储类别,即在函数外面定义数组是编译不通过的 !
- 允许使用
const变量。 - 使用
VLA不能在定义的时候对数组进行初始化。 - 一旦创建了变长数组,它的大小则保持不变。
/* 示例 */
void func(void){
int n;
scanf("%d", &n);
char array[n];
//char array[n] = {0}; // 不可行
array[0] = 1; // 可行,如何防止越界?
}
C90标准中,数组的长度必须在编译时期就知道。
C99支持 VLA 后,数组的长度可以推迟到运行时知道。
变长数组(VLA)和动态内存分配(调用 malloc() )在功能上有些重合,两者都可以在运行时确定数组大小。不同的是,
- 变长数组是自动存储类型,因此,程序在离开变长数组定义所在块时(某个函数),变长数组占用的内存空间会被自动释放,不必使用
free()函数。 - 用
malloc()创建的数组不必局限在一个函数内访问。
[1]: C Primer Plus 第六版
[2]: C:错误: C++ style comments are not allowed in ISO C90 🚀
[3]: C-C++到底支不支持VLA以及两种语言中const的区别 🚀
二、函数与数组
2.1、一维数组
/* 示例 */
int func(int a[])
{
int array[2];
//array++; // 不允许作为左值
a++; // 可以作为左值
}
在形参列表中:
- 数组方括号内大小没有意义,调用该函数时不会分配相应大小的空间,因为最后编译器会将它认为是一个指针(如上述的指向 int 类型的指针)。
- 对于正常定义的数组,数组名是地址常量,因此不能作为左值使用。而这里数组 a 被认为是指针,所以可以作为左值使用。
2.2、二维数组
/* 示例 */
#define COLS 1
int func(int rows, int a[][COLS])
{...}
int main(int argc, const char *argv[])
{
int array[1][COLS];
func(1, array);
return 0;
}
C99 标准之前,在形参列表中,对于二维数组,必须指定列数!(其维数为常量) 函数的行数可以不用指定,编译器将它处理成一个一维数组指针。
我们知道一维数组名是一个指向列元素的地址,二维数组名是一个指向行元素的地址(一维数组指针),因此,在传参的时候必须是列数相同的二维指针,不然实参与形参的参数类型不匹配,编译无法通过,适用性具有一定的局限。
在 C99 标准中新增变长数组( VLA ) 解决了这个问题。
int func(int rows, int cols, int ar[rows][cols])
{...}
int main(int argc, const char *argv[])
{
int junk[6][6];
int morejunk[3][3];
func(6,6,junk);
func(3,3,morejunk);
}
注意: 前两个形参(rows 和 cols)用作第 3 个形参二维数组(ar)的两个维度。因为 ar 的声明要使用 rows 和 cols,所以在形参列表中必须在声明 ar 之前先声明这两个形参。
int func(int ar[rows][cols], int rows, int cols) // 错误:无效的顺序
{...}
C99/C11 标准规定,可以省略原型中的形参名,但是在这种情况下,必须用星号来代替省略的维度。
int func(int, int, int ar[*][*]);
关于变成数组的另一种用法:https://blog.csdn.net/houzijushi/article/details/80245894 🚀
三、GCC 对 C 的扩展
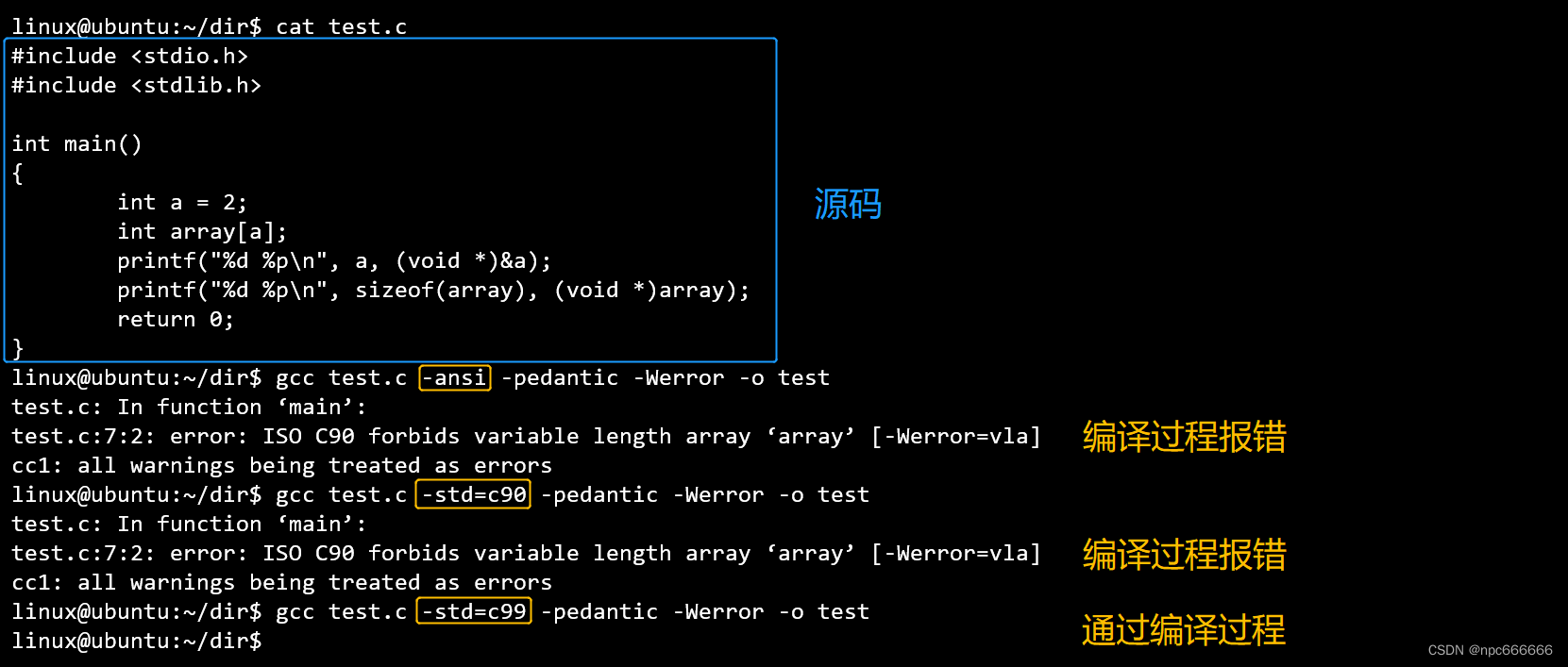
根据前面所述,变长数组是在 C99 标准之后新增的,但是通过 GCC 编译的时候居然能通过编译而不会报错。
/* test.c */
#include <stdio.h>
int main(int argc, const char *argv[])
{
int a = 2;
int array[a];
printf("%d %p\n", a, (void *)&a);
printf("%d %p\n", sizeof(array), (void *)array);
return 0;
}
编译:gcc -std=c90 test.c -o test
结果:编译通过
出现这种情况的原因在于:GCC 在 C90 模式下对 C 语言进行了扩展,接收了 ISO C99 中允许使用的可变数组。【6.20 Arrays of Variable Length 🚀】
GCC 编译选项
- -ansi:支持符合ANSI标准的C程序。这样就会关闭GNU C中某些不兼容ANSI C的特性,但是有些功能没关,比如变长数组。
- -std=c89:指明使用标准 ISO C90 (也称为ANSI C)作为标准来编译程序。
- -std=c99:指明使用标准 ISO C99 作为标准来编译程序。
- -pedantic:当gcc在编译不符合ANSI/ISO C 语言标准的源代码时,将产生相应的警告信息。
- -Werror:将所有的警告当成错误进行处理。
【嵌套函数(nested function):不知道是不是 GCC 做的扩展,但是 -ansi/-std=c90/-std=c99 都报错】
#include <stdio.h>
int main(int argc, const char *argv[])
{
int main(int parm)
{
printf("%d\n", parm);
return 0;
}
main(6);
return 0;
}
[1]: How to disable GNU C extensions? 🚀
[2]: C89(C90)、C99、C11——C语言的三套标准 🚀
[3]: GCC编译选项 🚀
四、变长数组的实现原理
编译器:gcc version 4.6.3
运行环境:Ubuntu 12.04.02 LTS (32位系统)
/* a.c */
#inlcude <stdio.h>
void func(int a, int b, int c, int c)
{
printf("hi\n");
}
int main(int argc, const char *argv[])
{
int n;
scanf("%d", &n);
int array[n];
array[6] = 6; // 方便在汇编代码中定位,当然这是一个危险操作❗
func(0, 1, 2, 3);
return 0;
}
编译:gcc a.c -g
反汇编:objdump -d a.out > a.dump
变长数组主要思考的问题:
- 变长数组是怎么完成栈空间申请?申请多少?
- 变长数组的起始地址是多少?
下面所示为反汇编后关键汇编代码:(就 3 行 C 代码,编译产生这么多汇编语句)
08049157 <main>:
...
8049152: 89 e5 mov %esp,%ebp ; %ebp = %esp
8049154: 53 push %ebx ; %ebx 入栈保存
8049155: 51 push %ecx ; %ecx 入栈保存
8049156: 83 ec 30 sub $0x30,%esp ; %esp = %esp - 0x30
8049159: 89 e0 mov %esp,%eax ; %eax = %esp
804915b: 89 c3 mov %eax,%ebx ; %ebx = %eax
804915d: b8 0b a0 04 08 mov $0x804a00b,%eax ; scanf 中字符串 "%d" 首地址为0x804a00b, 将其存入 %eax
8049162: 8d 55 ec lea -0x14(%ebp),%edx ; n 地址为 %ebp-0x14, 将其存入 %edx
8049165: 89 54 24 04 mov %edx,0x4(%esp) ; scanf 参数2(字符串) 入栈传参
8049169: 89 04 24 mov %eax,(%esp) ; scanf 参数1(变量 n 地址)入栈传参
804916c: e8 ef fe ff ff call 8049060 <__isoc99_scanf@plt> ; 将返回地址(0x8049171)入栈保存,然后调用 scanf 函数
8049171: 8b 45 ec mov -0x14(%ebp),%eax ; 取变量 n 值,保存到 %eax
8049174: 8d 50 ff lea -0x1(%eax),%edx ; %edx = %eax - 0x1
8049177: 89 55 f0 mov %edx,-0x10(%ebp) ; %edx 保存到 %ebp - 0x10 地址处
804917a: c1 e0 02 shl $0x2,%eax ; %eax = %eax << 0x2
804917d: 8d 50 0f lea 0xf(%eax),%edx ; %edx = %eax + 0xF
8049180: b8 10 00 00 00 mov $0x10,%eax ; %eax = 0x10
8049185: 83 e8 01 sub $0x1,%eax ; %eax = %eax - 0x1 = 0xF
8049188: 01 d0 add %edx,%eax ; %eax = %eax + %edx
804918a: c7 45 e4 10 00 00 00 movl $0x10,-0x1c(%ebp) ; (%ebp-0x1c) = 0x10
8049191: ba 00 00 00 00 mov $0x0,%edx ; %edx = 0x0
8049196: f7 75 e4 divl -0x1c(%ebp) ; %eax = (%edx:%eax)/(0x10), %edx = (%edx:%eax)mod(0x10)
8049199: 6b c0 10 imul $0x10,%eax,%eax ; %eax = %eax * 0x10
804919c: 29 c4 sub %eax,%esp ; %esp = %esp - %eax 为数组申请栈空间
804919e: 8d 44 24 10 lea 0x10(%esp),%eax ; %eax = %esp + 0x10, 为什么是0x10?
80491a2: 83 c0 0f add $0xf,%eax ; %eax = %eax + 0xF
80491a5: c1 e8 04 shr $0x4,%eax ; %eax = %eax >> 0x4
80491a8: c1 e0 04 shl $0x4,%eax ; %eax = %eax << 0x4, 此时的 %eax 的值就是变长数组的首地址
80491ab: 89 45 f4 mov %eax,-0xc(%ebp) ; 将 %eax 入栈
80491ae: 8b 45 f4 mov -0xc(%ebp),%eax ; 出栈栈,保存到 %eax, 不太清楚为什么要这么做?
80491b1: c7 40 18 06 00 00 00 movl $0x6,0x18(%eax) ; array[6] = 6, 索引为6, 则为数组的第7个元素, 由于是 int 类型, 大小为 4 字节, 对应数值0x18
80491b8: c7 44 24 0c 03 00 00 movl $0x3,0xc(%esp) ; func 参数4 入栈传参
80491bf: 00
80491c0: c7 44 24 08 02 00 00 movl $0x2,0x8(%esp) ; func 参数3 入栈传参
80491c7: 00
80491c8: c7 44 24 04 01 00 00 movl $0x1,0x4(%esp) ; func 参数2 入栈传参
80491cf: 00
80491d0: c7 04 24 00 00 00 00 movl $0x0,(%esp) ; func 参数1 入栈传参
80491d7: e8 57 ff ff ff call 8049133 <func> ; 将返回地址(0x80491dc)入栈保存,然后调用 func 函数
80491dc: b8 00 00 00 00 mov $0x0,%eax ; %eax = 0x0
80491e1: 89 dc mov %ebx,%esp ; %esp = %ebx
80491e3: 8d 65 f8 lea -0x8(%ebp),%esp ; 同最前面入栈操作对应
...
由于栈空间的申请是通过移动 %esp 寄存器来实现的,所以这里重点关注 sub %eax, %esp,%eax 的值就是最后申请的空间大小,汇总上面的操作,则 %eax 的值由下面这条公式操作计算得到:
%eax = (%eax << 2 + 0xF + 0xF) / 0x10 * 0x10 = (%eax * 4 + 0xF + 0xF) / 0x10 * 0x10
式中,
- 右边第一个 %eax 为 scanf 输入的值;
- int 数据类型为 4 字节,所以这边左移 2 ,即乘以 4;
- 加上 0xF 的我觉得其中一个目的是变长数组后面可能存在调用函数,比如上述的 func 函数,由于调用参数需要有栈空间用于传递参数所以加上这段空间。但是这个值不会因为后面调用函数的参数变多而改变,而变长数组所在函数在一开始为该函数(上面的main函数)分配栈空间时会因为调用函数实参数量的增加而增加,因此单纯使用变长数组正常读写实现越界比较困难。
- 又加上了 0xF 的原因我猜测确保后面操作后,所申请的空间不会变小。除以 0x10,再乘以 0x10,效果就是将低 4 位置为 0,如果低 4 位上非 0,那么所申请空间就会变小,所以加上 0xF,完成进位,防止申请的空间变小。
- 为什么要进行除0x10后又进行乘0x10,可能是为了地址对齐。
为什么说【 array[6] = 6 】是危险的操作?
首先这个操作在程序上下文中是不合理,因为不知道变长数组长度,直接访问指定元素是不合理的,一般也不会出现。所指的危险是越界危险,如果申请的空间大小为 3,那么访问 array[6] 是越界了,存在改写其它栈帧数据的危险。
【 lea 0x10(%esp),%eax 】语句中为什么是 0x10 ?
因为申请的栈空间,其中包含有后续函数调用所需要的栈空间,所以在确定变长数组首地址的时候这里偏移了一定距离,由于 func 函数的参数数量为 4,数据类型为 4 字节,所以偏移 16,即 0x10。

Linux 默认栈空间大小 8MB 或 10MB。(查看命令:ulimit -s)
所以如果输入数组长度的时候,需要先判断一下是否会超出栈空间大小。
🔍 如理解有误,望不吝指正。














 289
289











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









