






一.背景
cache改造,部分业务已从squid迁移至varnish,北京网通用户出现503错误。
二.改造后的varnish架构图
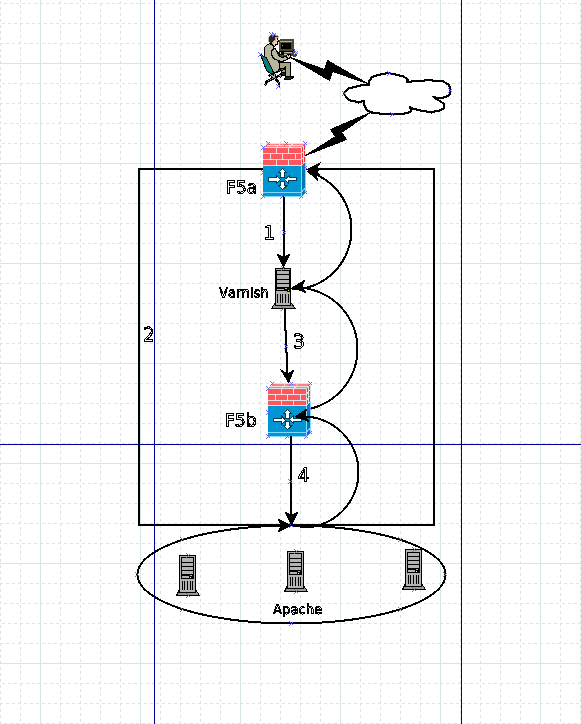
三.发现问题
access.log
查看varnish的access.log发现有503错误,这里为说明问题只摘抄了部分内容(当然还有其他域名)
xxx.com.cn:80 66.55.92.32 0.700661982 - [31/Oct/2012:02:39:25 +0800] "GET /forum-2-1.html HTTP/1.0" 200 26471 "http://xxx.com.cn" - miss "Mozilla/5.0 (compatible; YoudaoBot/1.0; http://www.xxx.com/help/webmaster/spider/; )"
xxx.com.cn:80 221.179.9.69 0.6990022888 - [31/Oct/2012:08:10:50 +0800] "GET /script/javascript/jquery.form.js HTTP/1.1" 200 6878 "http://xxx.com.cn/viewthread.php?tid=550653" - hit "dopodT8388/1.0 WindowsMobile/6.5 CEOS/5.2 release/5.0 IE/6.0 WAP2.0 Profile/MIDP2.0 Configuration/CLDC1.1 4.0 (compatible; MSIE 6.0; Windows CE; IEMobile 8.12; MSIEMobile 6.0)"
xxx.com.cn:80 221.179.9.69 0.700023127 - [31/Oct/2012:08:10:50 +0800] "GET /javascript/viewthread.js HTTP/1.1" 200 3493 "http://xxx.com.cn/viewthread.php?tid=550653" - hit "dopodT8388/1.0 WindowsMobile/6.5 CEOS/5.2 release/5.0 IE/6.0 WAP2.0 Profile/MIDP2.0 Configuration/CLDC1.1 4.0 (compatible; MSIE 6.0; Windows CE; IEMobile 8.12; MSIEMobile 6.0)"
xxx.com.cn:80 221.179.9.69 0.700152962 - [31/Oct/2012:08:10:50 +0800] "GET /javascript/menu.js HTTP/1.1" 200 2034 "http://xxx.com.cn/viewthread.php?tid=550653" - miss "dopodT8388/1.0 WindowsMobile/6.5 CEOS/5.2 release/5.0 IE/6.0 WAP2.0 Profile/MIDP2.0 Configuration/CLDC1.1 4.0 (compatible; MSIE 6.0; Windows CE; IEMobile 8.12; MSIEMobile 6.0)"
当时的第一反应就是后端服务器有问题了,于是赶紧curl后端的相关路径发现返回的都是200,而且多次测试结果都是一样的,然后又检查其他节点的varnish日志,发现其他节点也有相关的503错误,只是抛出的503量不一样,而且发现503错误的项目也不一样,这样就排除后端apache的问题;
在F5a上当时的抓包
这里只摘了出问题的部分
901 24.142157 61.135.153.11 10.68.6.36 TCP 104 36601>ospf-lite [SYN]Seq=0Win=4380Len=0MSS=1460WS=1TSval=2015975236TSecr=0SACK_PERM=1
902 24.150656 10.68.6.36 61.135.153.11 TCP 92 ospf-lite >36601 [SYN, ACK]Seq=0Ack=1Win=5840Len=0MSS=1460SACK_PERM=1WS=128
903 24.150665 61.135.153.11 10.68.6.36 TCP 80 36601 >ospf-lite [ACK]Seq=1Ack=1Win=4380Len=0
904 24.150672 61.135.153.11 10.68.6.36 TCP 300 36601 >ospf-lite [PSH, ACK]Seq=1Ack=1Win=4380Len=2203548494
905 24.159712 10.68.6.36 61.135.153.11 TCP 86 ospf-lite >36601 [ACK]Seq=1Ack=221Win=6912Len=0
907 24.851282 10.68.6.36 61.135.153.11 TCP 792 ospf-lite >36601 [PSH, ACK]Seq=1Ack=221Win=6912Len=712
抓包发现客户端与varnish已经建立了3次握手后,经过一段时间后varnish主动的返回了503
怀疑1:varnish自身的问题
考虑到此前用的squid时未发现用户反 应503的情况,经查询发现各IDC的squid上也有不少504和502的错误,只是数量上没varnish上的多,于是就去google了一下,发现 varnish 503的问题还是不少的,其中发现了一个重要的配置参数,参数内容如下:
connect_timeout
Units: s
Default: 0.7
Default connection timeout for backend connections. We only try to connect to the backend for this many seconds before giving up. VCL can override this default value for each backend and backend request.
然 后计算了一下F5的抓包数据,正好是0.7s,于是赶紧调整了此参数,在/usr/local/sinasrv2/etc/varnish /default.vcl 中添加了“.connect_timeout = 2s;”重启varnish,发现503的错误明显减少了(刚开始还一直不出),怀疑还有其他参数配置不合理导致的,于是又发现了以下2个参数:
http_resp_hdr_len
Units: bytes
Default: 8192
Maximum length of any HTTP backend response header we will allow. The limit is inclusive its continuation lines.
http_req_hdr_len
Units: bytes
Default: 8192
Maximum length of any HTTP client request header we will allow. The limit is inclusive its continuation lines.
以 上两参数是对HTTP的请求头和相应头包字节数的限制,我发现出错的页面所返回的字节数是超过这一限制的,于是调高了两参数的值,继续观察日志,发现仍然 有503,于是又调高connect_timeout至20s,与apahce超时时间一致,再继续观察日志,发现日志出现了微妙的变化,日志如下:
xxx.com.cn:80 221.179.19.6 4.600013949 - [31/Oct/2012:20:10:06 +0800] "GET //secure-cn.imrworldwide.com/v52.js HTTP/1.1" 404 199 "http://xxx.com.cn/thread-551292-1-1.html" - miss "MOT-MT810_TD/1.0 OMS/2.0 (Linux; Android) Release/5.30.2010 Browser/WAP 2.0 (AppleWebKit 528+) Profile/MIDP-2.0 Configuration/CLDC-1.1"
xxx.com.cn:80 221.179.9.69 4.599908085 - [31/Oct/2012:20:10:08 +0800] "GET /javascript/ajax.js HTTP/1.1" 200 4440 "http://xxx.com.cn/thread-551292-1-1.html" - miss "MOT-MT810_TD/1.0 OMS/2.0 (Linux; Android) Release/5.30.2010 Browser/WAP 2.0 (AppleWebKit 528+) Profile/MIDP-2.0 Configuration/CLDC-1.1"
xxx.com.cn:80 221.179.9.69 4.6000373812 - [31/Oct/2012:20:10:08 +0800] "GET /app/admin/javascript/jquery-ui-1.7.2.custom.min.js HTTP/1.1" 200 10059 "http://xxx.com.cn/thread-551292-1-1.html" - miss "MOT-MT810_TD/1.0 OMS/2.0 (Linux; Android) Release/5.30.2010 Browser/WAP 2.0 (AppleWebKit 528+) Profile/MIDP-2.0 Configuration/CLDC-1.1"
处理时间变成了4.6s,很奇怪的时间,想了想问题可能不好定位,考虑到可能会影响到业务,将受影响较大的项目迁出;保存了相关日志,想从4.6s的时间入手(99%的503都是4.6s的处理时间)查了很多资料时间总是对不上,于是我想还是先排除网络的问题(在这里走了些弯路,现在想想当时抓包看还是最有效的);
怀疑2:可能是网络上有丢包
那好吧,进行测试!
我就在varnish的本机上去ping F5a和F5b的VIP
[root@xxx64 ~]# ping xxx -c 2000 -f
PING xxx 56(84) bytes of data.
......................................................
---xxx ping statistics ---
2000 packets transmitted, 1946 received, 2% packet loss, time 1272ms
rtt min/avg/max/mdev=0.091/0.241/2.739/0.162 ms, ipg/ewma 0.636/0.221 ms
[root@xxx64 ~]# ping xxx -c 2000 -f
PING xxx 56(84) bytes of data.
.................................................
--- xxx ping statistics ---
2000 packets transmitted, 1951 received, 2% packet loss, time 1249ms
rtt min/avg/max/mdev=0.091/0.229/3.850/0.169 ms, ipg/ewma 0.625/0.227 ms
发 现有丢包现象,于是就联系网络组的同事说明了丢包的情况,他们让我把测试的结果发给他,他看后说这样测不出来的,说F5自身有对ping包的自我防护机制,目前配 置连续500个包就会主动断开,他为我测试把这限制开到了1000,说要测试的话最好是小于500的进行测试;于是又进行了多次连续总数为200的ping测 试,未发现有丢包现象;忽然想起F5的自我保护策略会不会是对80端口也有相同的策略,经证实F5只对ICMP协议有这样的限制;
网络从目前看暂时可以先排除了,(无法排除因素:由于项目已经切走了),那么还得继续怀疑了。。。
怀疑3:回源的F5有问题
我想了想估计问题是处在回源至F5b时出了某种问题,也就是图中的3,要想证实的话还得抓包去看,由于现在的量已经切走了,问题不好复现了,自己就模拟去curl上次出现503的页面,
for ((i=1;i<1000;i++));do curl -I -s 'http://xxx/thread-551640-1-1.html' -H 'Host:xxx.com.cn';done | grep HTTP | awk '{if($2>200) print $0}'(在varnish上直接curl的)
可是503的错误迟迟不能出现,刚开始什么也没抓到,后来改变了策略使用多进程一起去压,收获如 下:
2012-10-25 10:00:04.494007 IP 10.54.22.64.52590>10.54.22.14.80: S 299236948:299236948(0) win 5840
0x0000: 4500 0034 c0d7 4000 4006 3933 0a36 1640 E..4..@.@.93.6.@
0x0010: 0a36 160e cd6e 0050 11d5 fe54 0000 0000 .6...n.P...T....
0x0020: 8002 16d0 399f 0000 0204 05b4 0101 0402 ....9...........
0x0030: 0103 0307 ....
2012-10-25 10:00:04.494145 IP 10.54.22.14.80 >10.54.22.64.52590: S 1946948394:1946948394(0) ack 299236949 win 4380
0x0000: 4500 0030 f3dc 4000 ff06 4731 0a36 160e E..0..@...G1.6..
0x0010: 0a36 1640 0050 cd6e 740c 132a 11d5 fe55 .6.@.P.nt..*...U
0x0020: 7012 111c cd19 0000 0204 05b4 0103 0300 p...............
2012-10-25 10:00:04.494151 IP 10.54.22.64.52590 >10.54.22.14.80: . ack 1 win 46
0x0000: 4500 0028 c0d8 4000 4006 393e 0a36 1640 E..(..@.@.9>.6.@
0x0010: 0a36 160e cd6e 0050 11d5 fe55 740c 132b .6...n.P...Ut..+
0x0020: 5010 002e 09cc 0000 P.......
2012-10-25 10:00:04.494219 IP 10.54.22.64.52590 >10.54.22.14.80: P 1:1287(1286) ack 1 win 46
0x0000: 4500 052e c0d9 4000 4006 3437 0a36 1640 E.....@.@.47.6.@
0x0010: 0a36 160e cd6e 0050 11d5 fe55 740c 132b .6...n.P...Ut..+
0x0020: 5018 002e 45da 0000 4745 5420 2f74 6872 P...E...GET./thr
0x0030: 6561 642d 3534 3833 3337 2d31 2d31 2e68 ead-548337-1-1.h
0x0040: 746d 6c20 4854 5450 2f31 2e31 0d0a 4163 tml.HTTP/1.1..Ac
2012-10-25 10:00:04.593995 IP 10.54.22.14.80 >10.54.22.64.52590: . ack 1287 win 5666
0x0000: 4500 0028 06d0 4000 ff06 3446 0a36 160e E..(..@...4F.6..
0x0010: 0a36 1640 0050 cd6e 740c 132b 11d6 035b .6.@.P.nt..+...[
0x0020: 5010 1622 eed1 0000 0000 0000 0000 P.."..........
2012-10-25 10:00:09.094261 IP 10.54.22.14.80 >10.54.22.64.52590: R 1:1(0) ack 1287 win 5666
0x0000: 4500 0028 3b17 4000 ff06 fffe 0a36 160e E..(;.@......6..
0x0010: 0a36 1640 0050 cd6e 740c 132b 11d6 035b .6.@.P.nt..+...[
0x0020: 5014 1622 eecd 0000 0000 0000 0000 P.."..........
从 在varnish上的抓包看varnish与F5建立完3次握手后,本该F5回送数据,却等待4.6s后,F5直接回RET了,这个与日志记录的503一 致,当时怀疑F5的某种策略导致的,首先怀疑的是F5的自身的健康检查机制,怀疑在负载情况下后端某台apache无相应数秒后F5认为他不可用主动回的 RET(当时此apache池承担着主要web业务),后经确认F5的健康检查是5s一次,连续检查3次后,才会判定不可用的,这与 varnish的503日志的时间对不上,因此也排除了;继续怀疑吧。。。
怀疑4:怀疑后端apache有异常
最开始是排查那一时间的apache日志是否异常,包括用户日志,结果很失望,日志都很正常,貌似http就不知道此事发生了。
没 办法还是得抓包看看到底503那时到底后端怎么了,由于此apache池比较大,抓起来不好统计,于是跟网络部协商又帮我私自新建了个VIP,下面挂了一台apache,然后又用CURL去压,发现是有503了,可503的时间与线上当时的不一致,大多是20s的时间,这是 apache处理时间的超时,估计是压狠了,呵呵,那好吧慢慢压,它又不出了。。。好吧,再让网络组加几台再压,可还是出现的503时间不对,没有4.6秒 的,继续加机器。。。继续压测。。。这样观察了好几天;
插曲:这里要特别说明一下:某业务在这期间访问量飙升
发现压测的VIP中出现了4.6s的503,在所有后端上抓包,在77上发现了如下的可疑包:
2012-11-05 18:04:50.886220 IP 202.106.182.229.38694>10.54.22.77.80: S 2908491723:2908491723(0) win 4380
0x0000: 4500 0030 dc5a 4000 ff06 fd99 ca6a b6e5 E..0.Z@......j..
0x0010: 0a36 164d 9726 0050 ad5c 0fcb 0000 0000 .6.M.&.P.\......
0x0020: 7002 111c 7c92 0000 0204 05b4 0103 0300 p...|...........
2012-11-05 18:04:51.885757 IP 202.106.182.229.38694 >10.54.22.77.80: S 2908491723:2908491723(0) win 4380
0x0000: 4500 0030 7950 4000 ff06 60a4 ca6a b6e5 E..0yP@...`..j..
0x0010: 0a36 164d 9726 0050 ad5c 0fcb 0000 0000 .6.M.&.P.\......
0x0020: 7002 111c 7c92 0000 0204 05b4 0103 0300 p...|...........
2012-11-05 18:04:53.085690 IP 202.106.182.229.38694 >10.54.22.77.80: S 2908491723:2908491723(0) win 4380
0x0000: 4500 0030 2e5f 4000 ff06 ab95 ca6a b6e5 E..0._@......j..
0x0010: 0a36 164d 9726 0050 ad5c 0fcb 0000 0000 .6.M.&.P.\......
0x0020: 7002 111c 7c92 0000 0204 05b4 0103 0300 p...|...........
2012-11-05 18:04:53.786034 IP 202.106.182.229.38700 >10.54.22.77.80: S 3990287140:3990287140(0) win 4380
0x0000: 4500 0030 9de6 4000 ff06 3c0e ca6a b6e5 E..0..@...<..j..>
0x0010: 0a36 164d 972c 0050 edd6 f324 0000 0000 .6.M.,.P...$....
0x0020: 7002 111c 58b8 0000 0204 05b4 0103 0300 p...X...........
2012-11-05 18:04:54.285346 IP 202.106.182.229.38694 >10.54.22.77.80: S 2908491723:2908491723(0) win 4380
0x0000: 4500 002c ee4a 4000 ff06 ebad ca6a b6e5 E..,.J@......j..
0x0010: 0a36 164d 9726 0050 ad5c 0fcb 0000 0000 .6.M.&.P.\......
0x0020: 6002 111c 9099 0000 0204 05b4 0000 `.............
2012-11-05 18:04:54.785390 IP 202.106.182.229.38700 >10.54.22.77.80: S 3990287140:3990287140(0) win 4380
0x0000: 4500 0030 3d6c 4000 ff06 9c88 ca6a b6e5 E..0=l@......j..
0x0010: 0a36 164d 972c 0050 edd6 f324 0000 0000 .6.M.,.P...$....
0x0020: 7002 111c 58b8 0000 0204 05b4 0103 0300 p...X...........
2012-11-05 18:04:55.985399 IP 202.106.182.229.38700 >10.54.22.77.80: S 3990287140:3990287140(0) win 4380
0x0000: 4500 0030 f6db 4000 ff06 e318 ca6a b6e5 E..0..@......j..
0x0010: 0a36 164d 972c 0050 edd6 f324 0000 0000 .6.M.,.P...$....
0x0020: 7002 111c 58b8 0000 0204 05b4 0103 0300 p...X...........
2012-11-05 18:04:57.185603 IP 202.106.182.229.38700 >10.54.22.77.80: S 3990287140:3990287140(0) win 4380
0x0000: 4500 002c b125 4000 ff06 28d3 ca6a b6e5 E..,.%@...(..j..
0x0010: 0a36 164d 972c 0050 edd6 f324 0000 0000 .6.M.,.P...$....
0x0020: 6002 111c 6cbf 0000 0204 05b4 0000 `...l.........
2012-11-05 18:04:57.185611 IP 10.54.22.77.80 >202.106.182.229.38700: S 761174739:761174739(0) ack 3990287141 win 5840
0x0000: 4500 002c 0000 4000 4006 98f9 0a36 164d E..,..@.@....6.M
0x0010: ca6a b6e5 0050 972c 2d5e 9ad3 edd6 f325 .j...P.,-^.....%
0x0020: 6012 16d0 9ec8 0000 0204 05b4 `...........
2012-11-05 18:04:57.185968 IP 202.106.182.229.38700 >10.54.22.77.80: . ack 1 win 4380
0x0000: 4500 0028 b134 4000 ff06 28c8 ca6a b6e5 E..(.4@...(..j..
0x0010: 0a36 164d 972c 0050 edd6 f325 2d5e 9ad4 .6.M.,.P...%-^..
0x0020: 5010 111c bc39 0000 0000 0000 0000 P....9........
发现此次抓包中,F5在连续尝试发送4次SYN后就再无反应了(请注意38694端口的链接),在此阶段38700的链接也发生了重连,只不过是最后一次SYN后有了响应,下图是我画的个简单分析图,解释了4.6s的来历:
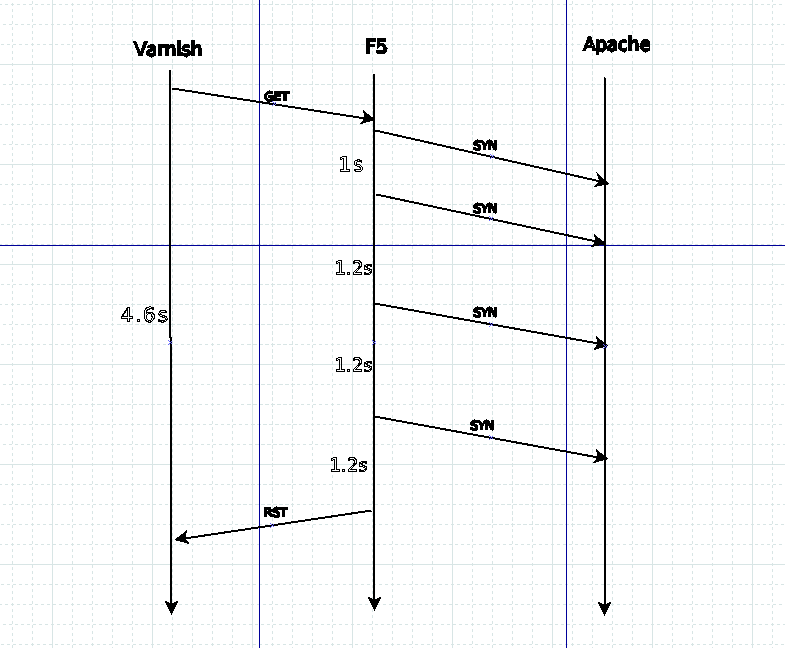
发现Apache为什么对SYN无相应呢,注意观察了一下对77的统计,发现在那个时间点77的负载很高,平均负载在100以上,内存基本耗尽,但为什么不接受第一次握手未找到合理的解释,刚开始怀疑是http://www.spinics.net/lists/linux-net/msg17195.html这 个的解释,部分win7系统中的注册表中有Tcp1323Opts这个选项,会导致其在发包时加入时间戳,经过nat之后,如果前面相同的端口被使用过, 且时间戳大于这个链接发出的syn中的时间戳,就会导致在服务器上忽略掉这个syn。表现为用户无法正常完成tcp3次握手,所提供的方法是 “sysctl -w net.ipv4.tcp_timestamps=0”, 发现此参数我们的机器默认就是关闭的, 之后又尝试把net.ipv4.tcp_window_scaling给关了试试,于是关闭后未发现 有所好转,分析后发现应该不是时间戳导致的,如果端口号重用的话,从抓包结果看在那一段时间内对另一端口也无响应,这种概率太低了,两个端口同时被重用,再说也不是NAT模式;
另一怀疑:
可能是网卡驱动导致的,之前有这样情况,在高负载下网卡间歇性无响应,于是检查了下池中机器的网卡版本,发现有3台是不一样的,只可惜不是那台出现问题的前端,看来驱动也可以排除了;
接着怀疑:
根 据之前排查所有的日志在那一时间内没有有任何异常的记录,包括message,error_log,发现问题应该还是内核导致的,于是就开始慢慢去看有关 TCP的内核参数,希望能找到一些突破口,呵呵,过程中试了不少改参数,可都没有起作用,经排查开启 net.ipv4.tcp_abort_on_overflow,此参数大体是这样解释的,当守护进程处于忙碌状态时就再也不接受新的请求了,而是主动的 给客户回RST,默认是关闭的,开启此选项你可以理解TCP的重传就失效了,此时再观察一下日志后发现503的错误增加了,而且处理时间都很短,和预期的 一致;
此现象说明apache所在的服务器在高负载下,连接池溢出的情况下是对新请求是无响应的,这也解释为什么在连续4次SYN后,apache不返回任何数据包现象的解释;
继续定位:
通过抓包的大小判断发现,F5b的负载不均,前半部分的包的数量要大于后半部分,这很可能是由于F5b的负载均衡策略导致的,经实上面添加了cookie,这会影响算法的平衡,关闭后发现4.6s 503 消失;
后续操作
1.将varnish的connect_timeout参数统一设置成20s;
2.将varnish的启动脚本中添加http_resp_hdr_len和http_req_hdr_len;
3.关闭net.ipv4.tcp_abort_on_overflow;
4.恢复之前的内核参数选项;
5.排查所有F5b的负载均衡策略,关闭cookie;















 181
181











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









