






socket操作函数read/write和recv/send用法基本相同,后者比前者多了一个flag参数。详见套接字I/O函数。如果是阻塞socket,执行读操作时,如果socket接收缓存区没有数据会阻塞等待数据;执行写操作时,如果socket发送缓存区没有足够的空间存放此次写入的数据,则会阻塞等待缓存区释放。读/写数据到缓存区成功后会立即返回,但写入socket缓存区并不代表数据会成功发送到对端,例如接收到TCP RST报文会导致TCP断链并清空缓存区数据。如果是非阻塞socket,在执行读操作时,如果socket接收缓存区没有数据,则直接返回EWOULDBLOCK错误;在执行写操作时,如果socket发送缓冲区中有足够空间或者是不足以拷贝所有待发送数据的空间的话,则拷贝前面N个能够容纳的数据,返回实际拷贝的字节数,socket发送缓存区没有空间时会返回EWOULDBLOCK错误。可以使用fcntl函数为文件描述符设置O_NONBLOCK标记来实现非阻塞socket。
阻塞/非阻塞socket是相对一条连接来说的。使用非阻塞可以防止读写线程阻塞,一般用于服务端。golang的read/write是阻塞的,但底层是非阻塞的,可以使用多协程实现非阻塞。
参考:
IO复用主要是服务端通过select(),poll(),epoll()等方式,可以监视多个描述符,一旦某个描述符就绪(一般是读就绪或者写就绪,就是这个文件描述符进行读写操作之前),能够通知程序进行相应的读写操作。但它们本质上还是同步IO。
参考:
零拷贝主要是减少用户空间到内核空间的拷贝次数。零拷贝通常使用mmap,sendfile,FileChannel,DMA等技术实现。使用sendfile时用户无法对文件进行修改,但使用mmap时可以修改文件。从Linux 2.4版本开始,操作系统底层提供了scatter/gather这种DMA的方式来从内核空间缓冲区中将数据直接读取到协议引擎中,而无需将内核空间缓冲区中的数据再拷贝一份到内核空间socket相关联的缓冲区中,此时只有外设缓存区满时写操作才会阻塞。
参考:
TCP
TCP的TIME_WAIT有两个作用:
防止前一个TCP连接的残留数据(在序列号恰好正确的情况下)进入后续的TCP连接中
防止TCP挥手过程发出去的最后一个ACK报文丢弃,此时需要重传该ACK报文
Linux网络队列:IP栈的报文提交会直接到QDisc队列,QDisc可以使用一定的策略来管控流量
BQL通过自动调节到driver queue的数据长度,来防止driver queue中的数据过大造成Bufferbloat而产生延迟。TSO, GSO, UFO和GRO可能会导致驱动队列中数据的增加,因此为了提高吞吐量的延迟,可以关闭这些功能。
QDisc(Queuing Disciplines)位于IP栈和driver queue之间,实现了流量分类,优先级划分和速率管控等。可以使用tc命令配置。QDisc有三个关键概念:QDiscs,classes和filter
QDisc用于流量队列。Linux实现了大量QDisc来满足各个QDisc对应的的报文队列和行为。该接口允许QDisc可以在没有IP栈和NIC驱动修改的前提下实现队列管理。默认情况下,每个网卡都会分配一个pfifo_fast类型的QDisc 。
第二个是与QDisc紧密相关的class。独立的QDisc 可能会实现class来处理其不同的流量。
Filters用于按照QDisc 或class来区分流量。

TCP拥塞避免算法,目前主流Linux的默认拥塞避免算法为cubic,可以使用ss -i命令查看。tcp有滑动窗口,拥塞窗口,滑动窗口为接收端可接收的数据大小,等于window_size*(2^tcp_window_scaling),可接收数据的缓存大小通过ACK报文通知对端;拥塞窗口可以通过ss -i的cwnd字段获得,发送端发送的数据不能超过cwnd和接收方通告窗口的大小。
滑动窗口本质上是描述接受方的TCP数据报缓冲区大小的数据,发送方根据这个数据来计算自己最多能发送多长的数据。如果发送方收到接受方的窗口大小为0的TCP数据报,那么发送方将停止发送数据,等到接受方发送窗口大小不为0的数据报的到来。
关于滑动窗口协议,还有三个术语,分别是:
窗口合拢:当窗口从左边向右边靠近的时候,这种现象发生在数据被发送和确认的时候。
窗口张开:当窗口的右边沿向右边移动的时候,这种现象发生在接受端处理了数据以后。
窗口收缩:当窗口的右边沿向左边移动的时候,这种现象不常发生。
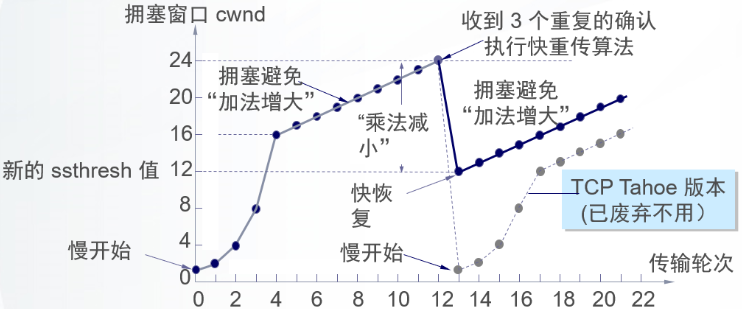
下面看下tahoe算法,reno算法(快速重传和快速恢复)和cubic算法的拥塞图,这三个算法在慢启动阶段相同,基于超时或重复确认来确认是否切换到拥塞避免阶段。不同点在拥塞避免阶段。tahos算法的描为(来自TCP-IP详解-卷1):
1) 对一个给定的连接,初始化cwnd为1个报文段, ssthresh为65535个字节。2) TCP输出例程的输出不能超过cwnd和接收方通告窗口的大小。拥塞避免是发送方使用的流量控制,而通告窗口则是接收方进行的流量控制。前者是发送方感受到的网络拥塞的估计,而后者则与接收方在该连接上的可用缓存大小有关。3) 当拥塞发生时(超时或收到重复确认),ssthresh被设置为当前窗口大小的一半(cwnd和接收方通告窗口大小的最小值,但最少为2个报文段)。此外,如果是超时引起了拥塞,则cwnd被设置为1个报文段(这就是慢启动)。4) 当新的数据被对方确认时,就增加cwnd,但增加的方法依赖于我们是否正在进行慢启动或拥塞避免。如果cwnd小于或等于ssthresh,则正在进行慢启动,否则正在进行拥塞避免。慢启动一直持续到我们回到当拥塞发生时所处位置的半时候才停止(因为我们记录了在步骤2中给我们制造麻烦的窗口大小的一半),然后转为执行拥塞避免。慢启动算法初始设置cwnd为1个报文段,此后每收到一个确认就加1。这会使窗口按指数方式增长:发送1个报文段,然后是2个,接着是4个⋯⋯。拥塞避免算法要求每次收到一个确认时将cwnd增加1 /cwnd。与慢启动的指数增加比起来,这是一种加性增长(additive increase)。我们希望在一个往返时间内最多为cwnd增加1个报文段(不管在这个RTT中收到了多少个ACK),然而慢启动将根据这个往返时间中所收到的确认的个数增加cwnd。
下图来自CSDN,可以看到tahoe算法在产生拥塞时会将cwnd设置为1,大大降低了传输效率
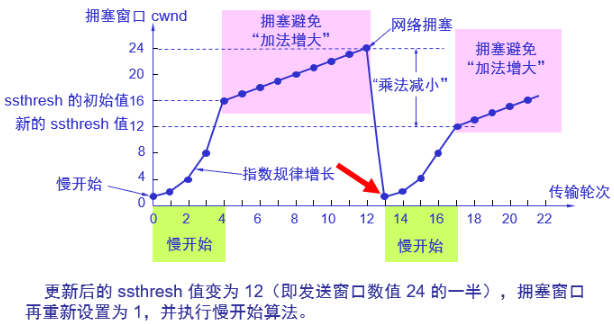
reno使用快速重传和快速恢复改进了tahoe算法:
快重传
快重传算法首先要求接收方每收到一个失序的报文段后就立即发出重复确认(为的是使发送方及早知道有报文段没有到达对方)而不要等到自己发送数据时才进行捎带确认。
接收方收到了M1和M2后都分别发出了确认。现在假定接收方没有收到M3但接着收到了M4。显然,接收方不能确认M4,因为M4是收到的失序报文段。根据可靠传输原理,接收方可以什么都不做,也可以在适当时机发送一次对M2的确认。但按照快重传算法的规定,接收方应及时发送对M2的重复确认,这样做可以让发送方及早知道报文段M3没有到达接收方。发送方接着发送了M5和M6。接收方收到这两个报文后,也还要再次发出对M2的重复确认。这样,发送方共收到了接收方的四个对M2的确认,其中后三个都是重复确认。快重传算法还规定,发送方只要一连收到三个重复确认就应当立即重传对方尚未收到的报文段M3,而不必继续等待M3设置的重传计时器到期。由于发送方尽早重传未被确认的报文段,因此采用快重传后可以使整个网络吞吐量提高约20%。
快恢复
与快重传配合使用的还有快恢复算法,其过程有以下两个要点:
当发送方连续收到三个重复确认,就执行“乘法减小”算法,把慢开始门限ssthresh减半。这是为了预防网络发生拥塞。请注意:接下去不执行慢开始算法。
由于发送方现在认为网络很可能没有发生拥塞,因此与慢开始不同之处是现在不执行慢开始算法(即拥塞窗口cwnd现在不设置为1),而是把cwnd值设置为慢开始门限ssthresh减半后的数值,然后开始执行拥塞避免算法(“加法增大”),使拥塞窗口缓慢地线性增大。
可以看到reno算法在发生拥塞避免时不会将cwnd变为1,这样提高了传输效率,快速重传和快速恢复机制也有利于更快探测到拥塞。
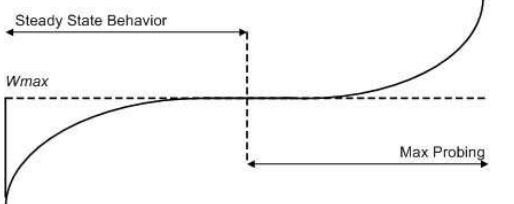
reno算法在拥塞避免阶段仍然是线性递增的,而cubic源于BIC算法,在拥塞避免阶段采用二分法查找最佳拥塞窗口,相比线性增加又增加了速率。下图来自该paper
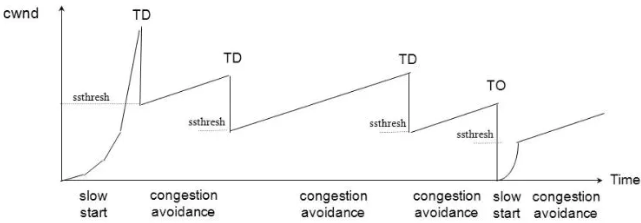
下面2张图,第一张为reno算法下的拥塞避免,第二张为cubic算法下的拥塞避免,可以看到cubic的拥塞窗口逼近速度更快

同主机进行TCP通信时,可能使用jumbo报文,导致MSS远大于一般的1460字节。为了方式这种情况下导致创建和传输大量符合MTU要求的报文,Linux实现了TSO,USO和GSO,参见下面描述
In order to avoid the overhead associated with a large number of packets on the transmit path, the Linux kernel implements several optimizations: TCP segmentation offload (TSO),
UDP fragmentation offload (UFO) and generic segmentation offload (GSO). All of these optimizations allow the IP stack to create packets which are larger than the MTU of the outgoing NIC.
For IPv4, packetsas large as the IPv4 maximum of 65,536bytes can be created and queued to the driver queue.
In thecase of TSO and UFO, the NIC hardware takes responsibility for breaking the single large packet into packets small enough to be transmitted on the physical interface. For NICs without hardware support,
GSO performs the same operationin software immediately before queueing to the driver queue.
Linux 命名空间:
mount命名空间:mount 命名空间通过隔离/proc/[pid]/mounts, /proc/[pid]/mountinfo, 和/proc/[pid]/mountstats文件,使得通过mount命令仅能查看到容器的挂载信息
Pid命名空间:通过挂载一个/proc命令使得在容器中使用ps -ef命令可以查看仅容器内部的进程
cgroup命名空间:容器所在的cgroup可以通过容器的进程查看/proc/$pid/cgroup,进而直到其对应的cgroup所在目录
network命名空间:如果两个进程属于不同的命名空间,则它们的/proc/$pid/net的信息相同;如果两个进程属于相同的命名空间,则它们的/proc/$pid/net的信息相同。除/proc/$pid/net目录外,网络命名空间还隔离了/sys/class/net,/proc/sys/net,socket等。














 3017
3017











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









