






Hive是基于Hadoop平台的数仓工具,具有海量数据存储、水平可扩展、离线批量处理的优点,解决了传统关系型数仓不能支持海量数据存储、水平可扩展性差等问题,但是由于Hive数据存储和数据处理是依赖于HDFS和MapReduce,因此在Hive进行数据离线批量处理时,需将查询语言先转换成MR任务,由MR批量处理返回结果,所以Hive没法满足数据实时查询分析的需求。
Hive是由FaceBook研发并开源,当时FaceBook使用Oracle作为数仓,由于数据量越来越大,Oracle数仓性能越来越差,没法实现海量数据的离线批量分析,因此基于Hadoop研发Hive,并开源给Apacha。
由于Hive不能实现数据实时查询交互,Hbase可提供实时在线查询能力,因此Hive和Hbase形成了良性互补。Hbase因为其海量数据存储、水平扩展、批量数据处理等优点,也得到了广泛应用。
Pig与HIVE工具类似,都可以用类sql语言对数据进行处理。但是他们应用场景有区别,Pig用于数据仓库数据的ETL,HIVE用于数仓数据分析。
Hive的系统架构图如下图所示:
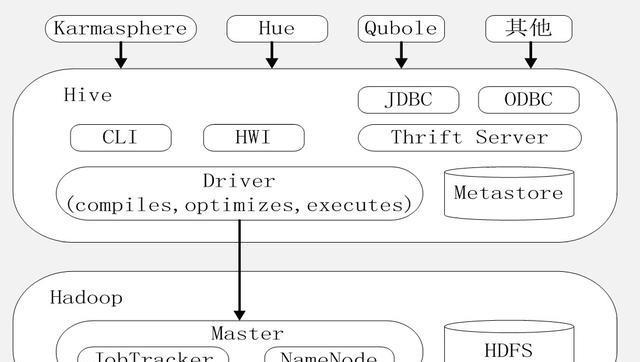
图 hive系统架构
从架构图当中,可看出Hive并没有完成数据的存储和处理,它是由HDFS完成数据存储,MR完成数据处理,其只是提供了用户查询语言的能力。Hive支持类sql语言,这种SQL称为Hivesql。用户可用Hivesql语言查询,其驱动可将Hivesql语言转换成MR任务,完成数据处理。
【Hive的访问接口】
CLI:是hive提供的命令行工具
HWI:是Hive的web访问接口
JDBC/ODBC:是两种的标准的应用程序编程访问接口
Thrift Server:提供异构语言,进行远程RPC调用Hive的能力。
因此Hiv具备丰富的访问接口能力,几乎能满足各种开发应用场景需求。
【Driver】
是HIVE比较核心的驱动模块,包含编译器、优化器、执行器,职责为把用户输入的Hivesql转换成MR数据处理任务。
【Metastore】
是HIVE的元数据存储模块,数据的访问和查找,必须要先访问元数据。Hive中的元数据一般使用单独的关系型数据库存储,常用的是Mysql,为了确保高可用,Mysql元数据库还需主备部署。
架构图上面Karmasphere、Hue、Qubole也是访问HIVE的工具,其中Qubole可远程访问HIVE,相当于HIVE作为一种公有云服务,用户可通过互联网访问Hive服务。
Hive在使用过程中出现了一些不稳定问题,由此发展出了Hive HA机制,其HA架构示意图如下图所示:
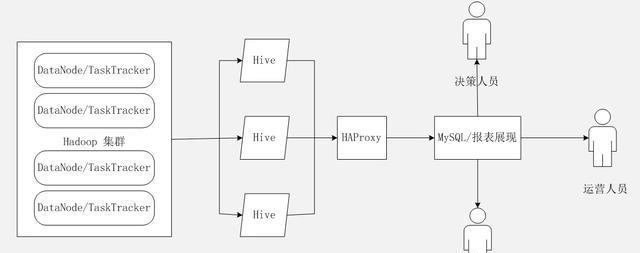
图 hive HA架构
Hive HA机制核心在于HAProxy,为了保证高可用,其后可对接多个HIVE实例,多个HIVE实例形成资源池。当用户访问HIVE时,先访问HAProxy,HAProxy会依次对HIVE实例进行逻辑可用性测试,如果发现某个实例不能使用,则将其列入黑名单。HAProxy维护了黑名单列表,并会对黑名单名单执行操作,例如重启,如果发现重启后,实例可正常访问,就将实例从黑名单中移出。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









