







1. 微信搜狗 大神的代码
import requests, re, pymongo, time
from fake_useragent import UserAgent
from urllib.parse import urlencode
from pyquery import PyQuery
from requests.exceptions import ConnectionError
client = pymongo.MongoClient('localhost')
db = client['weixin1']
key_word = 'python开发'
connection_count = 0 # 连接列表页失败的次数
connection_detail_count = 0# 连接列表页失败的次数
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:60.0) Gecko/20100101 Firefox/60.0',
'Cookie': 'CXID=161A70BF2483DEF017E035BBBACD2A81; ad=Hkllllllll2b4PxFlllllV7W9VGlllll$ZMXqZllll9llllljCxlw@@@@@@@@@@@; SUID=57A70FAB5D68860A5B1E1053000BC731; IPLOC=CN4101; SUV=1528705320668261; pgv_pvi=5303946240; ABTEST=5|1528705329|v1; SNUID=EF1FB713B7B2D9EE6E2A6351B8B3F072; weixinIndexVisited=1; sct=2; SUIR=F607AE0BA0A5CFF9D287956DA129A225; pgv_si=s260076544; JSESSIONID=aaaILWONRn9wK_OiUhlnw; PHPSESSID=1i38a2ium8e5th2ukhnufua6r1; ppinf=5|1528783576|1529993176|dHJ1c3Q6MToxfGNsaWVudGlkOjQ6MjAxN3x1bmlxbmFtZToxODolRTklQUQlOTQlRTklOTUlOUN8Y3J0OjEwOjE1Mjg3ODM1NzZ8cmVmbmljazoxODolRTklQUQlOTQlRTklOTUlOUN8dXNlcmlkOjQ0Om85dDJsdUtPQzE0d05mQkJFeUI2d1VJVkhZUE1Ad2VpeGluLnNvaHUuY29tfA; pprdig=ENOZrtvLfoIOct75SgASWxBJb8HJQztLgFbyhRHBfeqrzcirg5WQkKZU2GDCFZ5wLI93Wej3P0hCr_rST0AlvGpF6MY9h24P267oHdqJvgP2DmCHDr2-nYvkLqKs8bjA7PLM1IEHNaH4zK-q2Shcz2A8V5IDw0qEcEuasGxIZQk; sgid=23-35378887-AVsfYtgBzV8cQricMOyk9icd0; ppmdig=15287871390000007b5820bd451c2057a94d31d05d2afff0',
}
def get_proxy():
try:
response = requests.get("http://127.0.0.1:5010/get/")
if response.status_code == 200:
return response.text
return None
except Exception as e:
print('获取代理异常:',e)
return None
def get_page_list(url):
global connection_count
proxies = get_proxy()
print('列表页代理:', proxies)
# 请求url,获取源码
if proxies != None:
proxies = {
'http':'http://'+proxies
}
try:
response = requests.get(url, allow_redirects=False, headers=headers, proxies=proxies)
if response.status_code == 200:
print('列表页{}请求成功',url)
return response.text
print('状态码:',response.status_code)
if response.status_code == 302:
# 切换代理,递归调用当前函数。
get_page_list(url)
except ConnectionError as e:
print('连接对方主机{}失败: {}',url,e)
connection_count += 1
if connection_count == 3:
return None
# 增加连接次数的判断
get_page_list(url)
def parse_page_list(html):
obj = PyQuery(html)
all_a = obj('.txt-box > h3 > a').items()
for a in all_a:
href = a.attr('href')
yield href
def get_page_detail(url):
global connection_detail_count
"""
请求详情页
:param url: 详情页的url
:return:
"""
proxies = get_proxy()
print('详情页代理:',proxies)
# 请求url,获取源码
if proxies != None:
proxies = {
'http': 'http://' + proxies
}
try:
# 注意:将重定向allow_redirects=False删除。详情页是https: verify=False,
# 注意:将重定向allow_redirects=False删除。详情页是https: verify=False,
# 注意:将重定向allow_redirects=False删除。详情页是https: verify=False,
# 注意:将重定向allow_redirects=False删除。详情页是https: verify=False,
response = requests.get(url, headers=headers, verify=False, proxies=proxies)
if response.status_code == 200:
print('详情页{}请求成功', url)
return response.text
else:
print('状态码:', response.status_code,url)
# 切换代理,递归调用当前函数。
get_page_detail(url)
except ConnectionError as e:
print('连接对方主机{}失败: {}', url, e)
connection_detail_count += 1
if connection_detail_count == 3:
return None
# 增加连接次数的判断
get_page_detail(url)
def parse_page_detail(html):
obj = PyQuery(html)
# title = obj('#activity-name').text()
info = obj('.profile_inner').text()
weixin = obj('.xmteditor').text()
print('info')
return {
'info':info,
'weixin':weixin
}
def save_to_mongodb(data):
# insert_one: 覆盖式的
db['article'].insert_one(data)
# 更新的方法:
# 参数1:指定根据什么字段去数据库中进行查询,字段的值。
# 参数2:如果经过参数1的查询,查询到这条数据,执行更新的操作;反之,执行插入的操作;$set是一个固定的写法。
# 参数3:是否允许更新
db['article'].update_one({'info': data['info']}, {'$set': data}, True)
time.sleep(1)
def main():
for x in range(1, 101):
url = 'http://weixin.sogou.com/weixin?query={}&type=2&page={}'.format(key_word, 1)
html = get_page_list(url)
if html != None:
# 详情页的url
urls = parse_page_list(html)
for url in urls:
detail_html = get_page_detail(url)
if detail_html != None:
data = parse_page_detail(detail_html)
if data != None:
save_to_mongodb(data)
if __name__ == '__main__':
main()
2.刘晓军的代码
import re, pymongo, requests,time
from urllib.parse import urlencode
from pyquery import PyQuery
# fake_useragent: 实现啦User-Agent的动态维护,利用他每次随机后去一个User-Agent的值
from fake_useragent import UserAgent
client = pymongo.MongoClient('localhost')
db = client['wx']
key_word = 'python教程'
connection_count = 0
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:60.0) Gecko/20100101 Firefox/60.0',
'Cookie': 'SNUID=74852C8923264D45D6B96E0A2369AE27; IPLOC=CN4101; SUID=29139F756119940A000000005B090D0D; ld=Okllllllll2bjy12lllllV7JRy1lllllNBDF3yllll9lllllpklll5@@@@@@@@@@; SUV=003F178A759F13295B090D0E7F8CA938; UM_distinctid=163a9f5b4cc161-0f1b3689353b65-46514133-1fa400-163a9f5b4d0176; GOTO=; SMYUV=1527823120301610; pgv_pvi=6897384448; ABTEST=0|1528708438|v1; weixinIndexVisited=1; ppinf=5|1528708459|1529918059|dHJ1c3Q6MToxfGNsaWVudGlkOjQ6MjAxN3x1bmlxbmFtZTozNTpzbWFsbGp1biVFRiVCQyU4MSVFRiVCQyU4MSVFRiVCQyU4MXxjcnQ6MTA6MTUyODcwODQ1OXxyZWZuaWNrOjM1OnNtYWxsanVuJUVGJUJDJTgxJUVGJUJDJTgxJUVGJUJDJTgxfHVzZXJpZDo0NDpvOXQybHVQWWk5LVJkU1JJRHBHemsxWUx0Q01RQHdlaXhpbi5zb2h1LmNvbXw; pprdig=XRQQE_qExWhRS1AiOrwSCaNfWYtcUCrCVODql2R_gSIvCyFpG23pefn3RHO1EOH0L5TJRNEkpYgztrXfE1NvNtpe-1QR2PXH1frohkOL8RKEwJCVfRYhz1fOXSuZf0NQxC4Y9oSCfLimSVaodrUihdiLHmLqf1erzxZkEzFHhG4; sgid=17-35471325-AVsePWtlGzxQU9rKkedgl7k; sct=7; SUIR=18E941E54F4B2115642260494FE28B36; ppmdig=1528802332000000b239e8ac3d4723d0ecc7f25b5f16b073; JSESSIONID=aaaIry_FagLEc59Thglnw'
}
def get_proxy():
try:
response = requests.get('http://127.0.0.1:5010/get/')
if response.status_code == 200:
return response.text
return None
except Exception as e:
print('获取代理异常', e)
return None
def get_page_list(url):
global connection_count
proxies = get_proxy()
print('列表页代理', proxies)
if proxies != None:
proxies = {
'http': 'http://' + proxies
}
try:
response = requests.get(url, headers=headers, allow_redirects=False, proxies=proxies)
if response.status_code == 200:
return response.text
if response.status_code == 302:
get_page_list(url)
except ConnectionError as e:
connection_count += 1
if connection_count == 3:
return None
get_page_list(url)
def parse_page_list(html):
obj = PyQuery(html)
all_a = obj('.txt-box > h3 > a').items()
for a in all_a:
href = a.attr('href')
yield href
def get_page_detail(url):
global connection_detail_count
proxies = get_proxy()
print('列表页代理', proxies)
if proxies != None:
proxies = {
'http': 'http://' + proxies
}
try:
response = requests.get(url, headers=headers, verify=False, proxies=proxies)
if response.status_code == 200:
return response.text
if response.status_code == 302:
get_page_list(url)
except ConnectionError as e:
connection_detail_count += 1
if connection_count == 3:
return None
get_page_list(url)
def parse_page_detail(html):
obj = PyQuery(html)
info = obj('#img-content > h2').text()
weixinID = re.findall(re.compile(r'<div.*?class="profile_container.*?">.*?<span.*?>(.*?)</span>', re.S),html)
return {
'info': info,
'weixinID': weixinID
}
def save_to_mongodb(data):
db['article'].update_one({'info': data['info']}, {'$set': data}, True)
time.sleep(1)
def main():
for x in range(1, 101):
url = 'http://weixin.sogou.com/weixin?query={}&type=2&page={}'.format(key_word, 1)
html = get_page_list(url)
if html != None:
urls = parse_page_list(html)
for url in urls:
detail_html = get_page_detail(url)
if detail_html != None:
data = parse_page_detail(detail_html)
if data != None:
save_to_mongodb(data)
if __name__ == '__main__':
main()
3.xpath
# xpath:跟re, bs4, pyquery一样,都是页面数据提取方法。根据元素的路径来查找页面元素。
# pip install lxml
# element tree: 文档树对象
from lxml.html import etree
html = """
<div id='content'>
<ul class='list'>
<li class='one'>One</li>
<li class='two'>Two</li>
<li class='three'>Three</li>
<li class='four four1 four2 four3'>Four</li>
<div id='inner'>
<a href='http://www.baidu.com'>百度一下</a>
<p>第一段</p>
<p>第2段</p>
<p>第3段</p>
<p>
第4段
<span>法大师傅大师傅</span>
</p>
<p>第5段</p>
<p>第6段</p>
</div>
</ul>
</div>
"""
obj = etree.HTML(html)
# HTML 用于 HTML
# fromstring 用于 XML
# 将一个Html文件解析成为对象。
# obj = etree.parse('index.html')
print(type(obj))
# //ul: 从obj中查找ul,不考虑ul所在的位置。
# /li: 找到ul下边的直接子元素li,不包含后代元素。
# [@class="one"]: 给标签设置属性,用于过滤和筛选
# xpath()返回的是一个列表
one_li = obj.xpath('//ul/li[@class="one"]')[0]
# 获取one_li的文本内容
print(one_li.xpath('text()')[0])
# 上述写法的合写方式
print(obj.xpath('//ul/li[@class="one"]/text()')[0])
# 获取所有li的文本内容:all_li = obj.xpath('//ul/li/text()')
# 获取包含某些属性的标签元素
print(obj.xpath('//ul/li[contains(@class,"four3")]'))
# 获取同时包含id和class两个属性元素的写法为
//div[@class='abc'][@id='123']
xpath组合查询: . 表示文本
# @class, @id
# . 表示文本内容
detail_url = weibo.xpath('.//a[contains(., "原文评论[")]/@href').extract_first('')
# 获取谁的属性就直接@谁,例如想要获取a标签中href属性的值: /a/@href
# 获取所有li的文本内容以及class属性的值
all_li = obj.xpath('//ul/li')for li in all_li: class_value = li.xpath('@class')[0]
text_value = li.xpath('text()')[0]
print(class_value, text_value)
# 获取div标签内部的所有文本
# //text():获取所有后代元素的文本内容
# /text():获取直接子元素的文本,不包含后代元素print(obj.xpath('//div[@id="inner"]//text()'))
# 获取ul中第一个li [1]: 位置print(obj.xpath('//ul/li[1]/text()'))此时的位置 1 不是从0 开始的,更不是索引值
# 查找类名中包含four的li的文本内容print(obj.xpath('//ul/li[contains(@class, "four")]/text()'))
# 作业:
# 利用xpath爬取百度贴吧内容 https://tieba.baidu.com/p/3164192117
# 利用xpath爬取猫眼电影Top100的内容 http://maoyan.com/board/4# mongodb, mysql, xlwt, csv(获取的数据是正常的,存入csv时乱码)# {'content': '最后巴西捧杯。4年后我会回来!
', 'sub_content': ['xxx', 'xxx', 'xxxx']}

4.pyquery
# pyquery :仿照jquery语法,封装一个包,和bs4有点类似
from pyquery import PyQuery
html = """
<div id='content'>
<ul class='list'>
<li class='one'>One</li>
<li class='two'>Two</li>
<li class='three'>Three</li>
<li class='four'>Four</li>
<div id='inner'>
<a href='http://www.baidu.com'>百度一下</a>
</div>
</ul>
</div>
"""
# 利用Pyquery类,对html这个文档进行序列化,结果是一个文档对象
doc_obj = PyQuery(html)
print(type(doc_obj))
# 查找元素的方法
ul = doc_obj('.list') # 从doc_obj这个对象中根据类名匹配元素
# print(ul) # ul 是一个对象
# print(type(ul))
# 从ul 中查找a
print(ul('a'))
# 当前元素对象.find(): 在当前对象中查找后代元素
# 当前元素对象.chrildren(): 在当前对象中查找直接子元素
print(ul.find('a'), '后代元素')
# 父元素的查找
# parent(): 直接父元素
# parents(): 所有的父元素
a = ul('a')
print(a.parent('#inner'), '直接父元素')
print(a.parents(), '所有父元素')
# 兄弟元素的查找,不包含自己,和自己同一级的兄弟标签
li = doc_obj('.one')
print(li.siblings(),'所有siblings')
print(li.siblings('.two'), '我是siblings')
# 遍历元素
ul = doc_obj('.list')
# generator object
res = ul('li').items()
print(res,'我是res')
for li in res:
print(li,'哈哈哈')
# 获取标签对象的文本内容
print(li.text(), '文本内容')
# 获取标签属性
print(li.attr('class'), '属性')等同于
或 print(li.attr.class)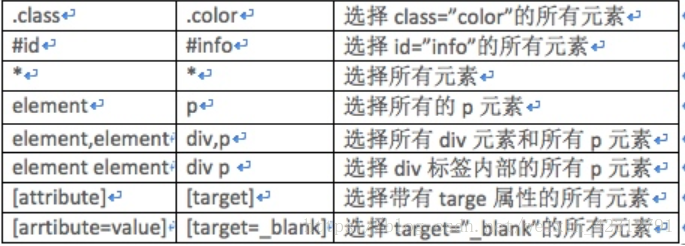
使用CSS选择特定的标签
#使用CSS3 特定的伪类选择器,选择特定的标签
#用例: 伪类选择器
html = ‘‘‘
<div class="wrap">
<div id="container">
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
</div>
‘‘‘
from pyquery import PyQuery as pq
doc = pq(html)
li = doc(‘li:first-child‘) #选择第1个 li 标签,注意 : 号写法
print(li)
li = doc(‘li:last-child‘) #选择最后1个 li 标签
print(li)
li = doc(‘li:nth-child(2)‘) #选择指定的,第2个li标签 ,child() 序号从1开始
print(li)
li = doc(‘li:gt(2)‘) #选择序号比3大的,也就是第3个 li 标签之后的 li 标签 (序号从0开始)
print(li)
li = doc(‘li:nth-child(2n)‘) #选择序号为偶数索引的 li 标签
print(li)
li = doc(‘li:contains(second)‘) #选择文本部分包含 second 的 li 标签
print(li)
5.csselect
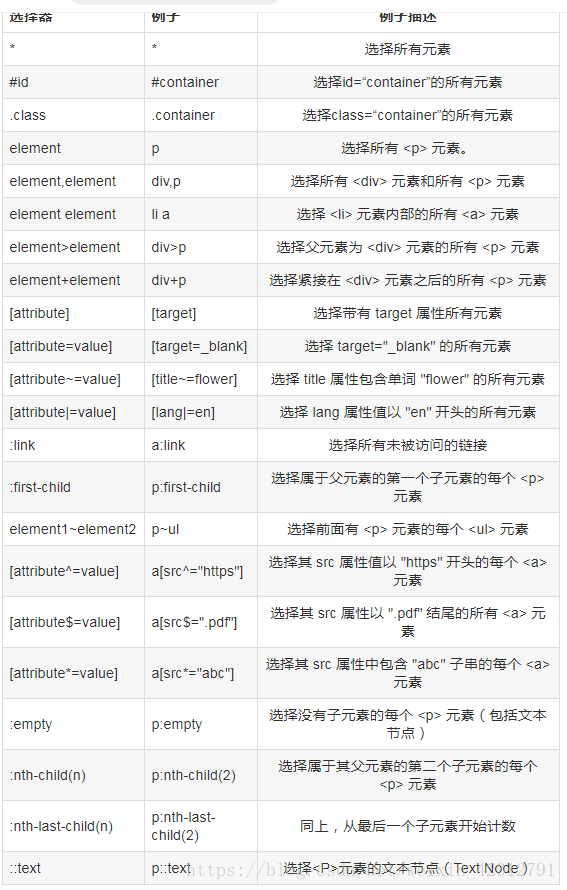
# cssselector:和xpath是使用比较多的两种数据提取方式。
# scrapy爬虫框架:支持xpath/css
# pyspider爬虫框架:支持PyQuery,也是通过css样式选择器实现的
# pip install cssselector
import cssselect
from lxml.html import etree
html = """
<div id='content'>
<ul class='list'>
<li class='one'>哈哈</li>
<li class='two'>Two</li>
<li class='three'>Three</li>
<li class='four four1 four2 four3'>Four</li>
<div id='inner'>
<a href='http://www.baidu.com'>百度一下</a>
<p>第一段</p>
<p>第2段</p>
<p>第3段</p>
<p>
第4段
<span id="first">法大师傅大师傅</span>
</p>
<p>第5段</p>
<p>第6段</p>
</div>
</ul>
</div>
"""
html_obj = etree.HTML(html)
span = html_obj.cssselect('.list > .four')[0]
print(span.text) # 获取文本内容
# print(help(span))# 查找方法
# print(span.attrib['id']) # 获取属性:是一个字
# csv:
xpath和cssselector之间的差别
在scrapy中这样用 其他按照正常的来


a.属性名 来表明a的
6.正则
import re
# re: 用于提取字符串内容的模块。
# 1> 创建正则对象;2> 匹配查找;3> 提取数据保存;
string = """
<html>
<div><a href='www.baidu.com'></a></div></div></div>
</div><title>正则</title></div>
<html><div><a href='www.baidu1.com'></a></div>
</div></div></div><title>正则1</title></div>
<html><div><a href='www.baidu2.com'></a>
</div></div></div></div><title>正则2</title></div>
<html><div><a href='www.baidu3.com'>
</a></div></div></div></div><title>正则3</title></div>"""
# ()是提取的一组数据 \b \b
# re.S 可以将正则的搜索域不再是一行,而是整个html字符串。
pattern = re.compile(r"<a href='(.*?)'>.*?<title>(.*?)</title>", re.S)
# .*? 非贪婪匹配
# .* 贪婪匹配
# \d+
# \w+
# [a-z0-9]
# \d{4}
# findall() 返回是列表
res = re.findall(pattern, string)
print(res)
string = "a1234booooobccccccb"
# a.*?b a1234b
# a.*b a1234booooobccccccb
# 查找单个数据:search(): 不考虑数据的位置。 match(): 必须保证数据在目标字符串的起始位置。
string = '2a3'
print(re.match(re.compile('(\d)'), string))
代理--进程池--保存到exel表格中
import requests, re
from fake_useragent import UserAgent
# from urllib.request import urlretrieve
import xlwt
from multiprocessing import Pool
class QiShu(object):
sheet = None
workbook = None
row = 1
def __init__(self):
self.url = 'https://www.qisuu.la/'
@classmethod
def get_proxy(cls):
return requests.get('http://localhost:5010/get/').text
@classmethod
def get_headers(cls):
ua = UserAgent()
headers = {
'User-Agent': ua.random
}
return headers
def get_index_page(self):
proxies = {
'http': 'http://' + self.get_proxy()
}
print(proxies)
try:
response = requests.get(self.url, self.get_headers(), proxies=proxies)
if response.status_code == 200:
self.parse_index_page(response.text)
else:
print('首页状态码:', response.status_code)
return None
except Exception as e:
print('请求或解析首页异常:', e)
return None
@classmethod
def parse_index_page(cls, index_page):
index_pattern = re.compile(
r'<div class="nav">.*?<a.*?class="nav-cur".*?</a>.*?<a href="(.*?)".*?<a href="(.*?)".*?<a href="(.*?)".*?<a href="(.*?)".*?<a href="(.*?)".*?<a href="(.*?)".*?<a href="(.*?)".*?<a href="(.*?)".*?<a href="(.*?)".*?</a>.*?<a href="(.*?)".*?</a>',
re.S)
sort_types = re.findall(index_pattern, index_page)
# 提取分类的url
# print(sort_types)
pool = Pool(5)
for sort_url in sort_types[0]:
sort_url = 'https://www.qisuu.la' + sort_url
# cls.get_list_page(sort_url)
pool.apply_async(cls.get_list_page, args=(sort_url,), callback=cls.parse_list_page)
pool.close()
pool.join()
@classmethod
def get_list_page(cls, list_url):
proxies = {
'http': 'http://' + cls.get_proxy()
}
try:
response = requests.get(list_url, headers=cls.get_headers(), proxies=proxies)
if response.status_code == 200:
# 解析列表页
# cls.parse_list_page(response.text)
print(list_url + '解析成功')
return response.text
else:
print('列表页状态吗:', response.status_code)
return None
except Exception as e:
print('请求或解析列表页异常:', e)
return None
@classmethod
def parse_list_page(cls, list_page):
list_pattern = re.compile(r'<div class="listBox">.*?<ul>(.*?)</ul>', re.S)
ul = re.search(list_pattern, list_page).groups()[0]
# print(ul)
list_data = re.findall(re.compile(r'<a href="(.*?)">.*?<img src="(.*?)" onerror=.*?">', re.S), ul)
pool = Pool(5)
for href, img in list_data:
# img_url = 'https://www.qisuu.la' + img
# urlretrieve(img_url, filename='')
detail_url = 'https://www.qisuu.la' + href
print(detail_url)
# 非多进程
# cls.get_detail_page(detail_url)
# 多进程
pool.apply_async(cls.get_detail_page, args=(detail_url,), callback=cls.parse_detail_page)
pool.close()
pool.join()
# 查找下一页
# next_page_url = re.search(re.compile(r'<div class="tspage">.*?<a href="(.*?)">下一页</a>', re.S), list_page)
# if next_page_url:
# next_page_url = next_page_url.groups()
# next_page_url = 'https://www.qisuu.la' + next_page_url
# self.get_list_page(next_page_url)
# else:
# print('已经是最后一页了')
@classmethod
def get_detail_page(cls, detail_url):
proxies = {
'http': 'http://' + cls.get_proxy()
}
try:
response = requests.get(detail_url, headers=cls.get_headers(), proxies=proxies)
if response.status_code == 200:
return response.content.decode('utf-8')# 利用返回值进行传参给
parse_detail_page()
else:
print('请求详情页状态吗:', response.status_code)
return None
except Exception as e:
print('请求或解析详情页异常:', detail_url, e)
return None
@classmethod
def parse_detail_page(cls, detail_page):
detail_pattern = re.compile(
r'<div class="detail_right">.*?<h1>(.*?)</h1>.*?<li class="small">(.*?)</li>.*?<li class="small">(.*?)</li>.*?<li class="small">(.*?)</li>.*?<li class="small">(.*?)</li>.*?<li class="small">(.*?)</li>.*?<li class="small">(.*?)</li>.*?<li >(.*?)</li>.*?<li class="small">(.*?)</li>',
re.S)
detail_data = re.findall(detail_pattern, detail_page)
title = click_num = file_size = novel_type = date_time = status = author = env = news_article = ''
for title, click_num, file_size, novel_type, date_time, status, author, env, new_article in detail_data:
click_num = click_num.split(':')[1]
file_size = file_size.split(':')[1]
novel_type = novel_type.split(':')[1]
date_time = date_time.split(':')[1]
status = status.split(':')[1]
author = author.split(':')[1]
env = env.split(':')[1]
new_article = new_article.split(':')[1]
pattern = re.compile('<a.*?>(.*?)</a>')
try:
news_article = re.search(pattern, new_article).groups()
except Exception as e:
news_article = ''
print('最新章节获取失败')
# 小说的介绍
info_pattern = re.compile(r'<div class="showInfo">.*?<p>(.*?)</p>', re.S)
info = re.search(info_pattern, detail_page).groups()
# 下载地址
down_pattern = re.compile(r"get_down_url(.*?);", re.S)
down_url = re.search(down_pattern, detail_page)
url = down_url.groups()[0].split(',')[1].strip("\\'")
# print(title, click_num, file_size, novel_type, date_time, status, author, env, news_article, info, url)
QiShu.sheet.write(QiShu.row, 0, title)
QiShu.sheet.write(QiShu.row, 1, click_num)
QiShu.sheet.write(QiShu.row, 2, file_size)
QiShu.sheet.write(QiShu.row, 3, novel_type)
QiShu.sheet.write(QiShu.row, 4, date_time)
QiShu.sheet.write(QiShu.row, 5, status)
QiShu.sheet.write(QiShu.row, 6, author)
QiShu.sheet.write(QiShu.row, 7, env)
QiShu.sheet.write(QiShu.row, 8, news_article)
QiShu.sheet.write(QiShu.row, 9, info)
QiShu.sheet.write(QiShu.row, 10, url)
QiShu.row += 1
@classmethod
def open_file(cls):
QiShu.workbook = xlwt.Workbook(encoding='utf-8')
QiShu.sheet = QiShu.workbook.add_sheet('奇书')
QiShu.sheet.write(0, 0, '标题')
QiShu.sheet.write(0, 1, '点击数')
QiShu.sheet.write(0, 2, '文件大小')
QiShu.sheet.write(0, 3, '小说类型')
QiShu.sheet.write(0, 4, '更新时间')
QiShu.sheet.write(0, 5, '连载状态')
QiShu.sheet.write(0, 6, '作者')
QiShu.sheet.write(0, 7, '运行环境')
QiShu.sheet.write(0, 8, '最新章节')
QiShu.sheet.write(0, 9, '小说简介')
QiShu.sheet.write(0, 10, '下载地址')
@classmethod
def close_file(cls):
QiShu.workbook.save('奇书.xls')
if __name__ == '__main__':
qishu = QiShu()
QiShu.open_file()
qishu.get_index_page()
QiShu.close_file() 进程池--代理---保存到mongodb中
7.bs4
# 爬虫网络请求方式:urllib(模块), requests(库), scrapy, pyspider(框架)
# 爬虫数据提取方式:正则表达式, bs4, lxml, xpath, css
from bs4 import BeautifulSoup
# 参数1:序列化的html源代码字符串,将其序列化成一个文档树对象。
# 参数2:将采用 lxml 这个解析库来序列化 html 源代码
html = BeautifulSoup(open('index.html', encoding='utf-8'), 'lxml')
# print(html.title)
# print(html.a)
#
# # 获取某一个标签的所有属性
# # {'href': '/', 'id': 'result_logo', 'onmousedown': "return c({'fm':'tab','tab':'logo'})"}
# print(html.a.attrs)
#
# # 获取其中一个属性
# print(html.a.get('id'))
# 获取多个标签,需要遍历文档树
# print(html.head.contents)
# print(html.head.children) # list_iterator object
# for ch in html.head.children:
# print(ch)
# descendants
# print(html.head.descendants)
# find_all
# find
# get_text: 标签内所有文本,包含子标签
# select
# string: 不能有其他标签。
print(html.select('.two')[0].get_text())
# print(help(html))
# find_all:根据标签名查找一组元素
# res = html.find_all('a')
# print(res,'aaa')
# select:支持所有的CSS选择器语法
res = html.select('.one')[0]
# print(res.get_text())
# print(res.get('class'),'凉凉')
res = html.select('.two')[0]
print(res)
print('----',res.next_sibling)
import os
os.mkdir('abc') # 在当前目录下6-7下,创建abc
os.chdir('abc') # 进入到abc
os.mkdir('123') # 在abc创建123目录
os.chdir(os.path.pardir) # 回到父级目录
os.mkdir('erf')创建和abc等级的文件夹erf
#获取标签名
tag.name
#对应的该变标签名为
tag.name = "你想要的标签"属性
#获取属性
#获取属性列表
tag.attrs
#输出为一个dict键为属性,值为属性值
#例如{"class":"abc", "id":"link1"}
#获取指定属性
tag['class']
#或
tag.get('class')
#多值属性
#对于HTML中定义的一些可以包含多个值的属性(class,rev等等)
#返回值为list类型
tag['class']
#例如['top', 'box']
#为属性赋值
tag['class'] = "class1"内容
这里用两种获取方式
.string 和 get_text()
.string 用来获取标签的内容
get_text() 用来获取标签中所有字符串包括子标签的。
#获取当前标签内容
tag.string
#返回结果的type为 <class 'bs4.element.NavigableString'>
#获取标签内所有的字符串
tag.get_text()
#返回结果的type为 <class 'str'>
#为标签内容赋值
tag.string = "str"注意!!
在取值时我们要注意一点就是在获取标签的时候获取的是单个标签还是标签列表。
也就是find()和find_all(),select()和select_one()的区别。
当使用
find()
select_one()时,获得的是一个标签
类型为
<class 'bs4.element.Tag'>所以可以使用tag['class']取值
当使用
find_all()
select()时,获得的是组标签(就算只有一个标签也是一组)
类型为
#find_all()的返回值类型
<class 'bs4.element.ResultSet'>
#select()的返回值类型
<class 'list'>这时,我们要取值就需要先定位是list(ResultSet)中的那个标签在取值
例如tag[0]['class']
from bs4 import BeautifulSoup
import bs4创建soup对象(读取file文件创建)
filepath = 'test.html'
soup = BeautifulSoup(open(filepath,encoding='utf-8'),'lxml')使用
根据标签查找(type:bs4_obj)
tag_p = soup.p获取属性
name = tag_p.name
title = tag_p.attrs.get('title')
title = tag_p.get('title')
title = tag_p['title']获取文本内容
string = tag_p.string
text = tag_p.get_text()
content = tag_p.contents
#过滤注释内容
if type(tag_p.string)==bs4.element.Comment:
print('这是注释内容')
else:
print('这不是注释')获取子孙节点(tpye:generator)
descendants = soup.p.descendants- 1
find&&find_all查找
soup.find('a')
soup.find('a',title='hhh')
soup.find('a',id='')
soup.find('a',class_='')
soup.find_all('a')
soup.find_all(['a','p'])
soup.find_all('a',limit=2)select选择(type:list)
soup.select('.main > ul > li > a')[0].string














 300
300











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









