






【前言】
本文和大家分享:linux系统下常见得性能异常,怎样定位到进程级别。说简单点,就是:linux性能出问题了,我们需要确定哪些进程影响了linux的性能。
本文主要涉及的linux的常见的性能维度:cpu,内存,io,网络
【涉及工具】
top:综合,偏cpu,内存
dstat:综合、磁盘
iostat:磁盘io,全局
iotop:磁盘io,精确到进程,(类似工具还有pidstat)
iftop:网络、实时刷新(类似工具还有nload,ifstat)
nethogs:进程级别的流量
ss:网络、快、消耗资源低(替代netstat)
pidstat:综合的
free:额,内存。。。
【cpu】
cpu主要关注性能指标:
(1)cpu使用率:用户,系统等
(2)cpu累计使用时长
(3)中断,上下文切换等(使用不多)
就cpu性能指标的观察而言,其实有很多工具,这里主要介绍top和dstat
1、top
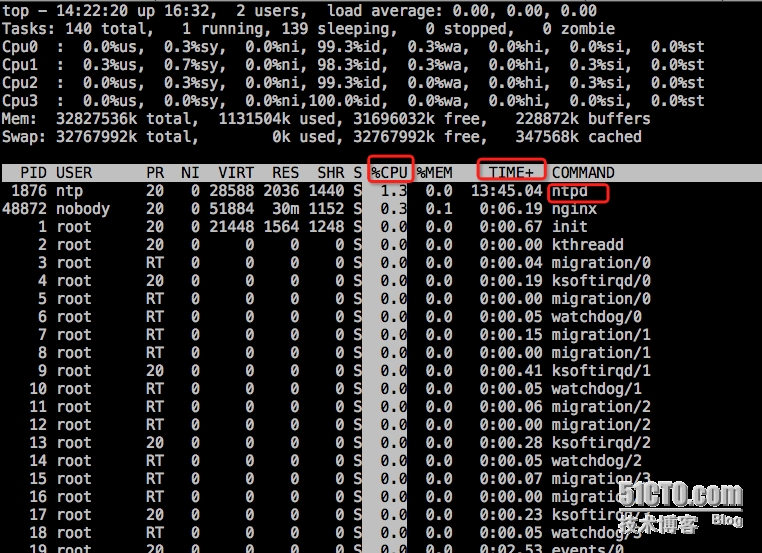
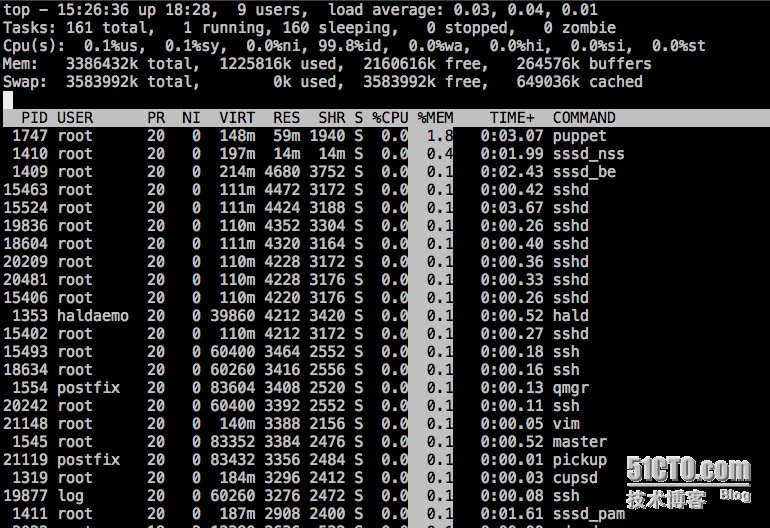
top各行结果我就不详细介绍了,是用起来也比较简单。对于排查cpu是用率过高,比较关键的指令是P和T。
输入了P(冒号P)之后:按照cpu排序
输入T(冒号T):根据时间、累计时间排序,可查看哪些进程消耗历史消耗多
这样我们就能找到哪个进程占用cpu过高了。
下例:就发现ntpd脚本占用的cpu时间是最多的,当前的ntpd占用cpu使用率也较大(其实只有1.3%)
另外:还可以输入以下便捷指令
1:多核
m:是否显示内存信息
M:根据内存排序
H:shift+h,打开线程模式
x:列的高亮(先要按b)
shift+改变排序的行
2、dstat命令
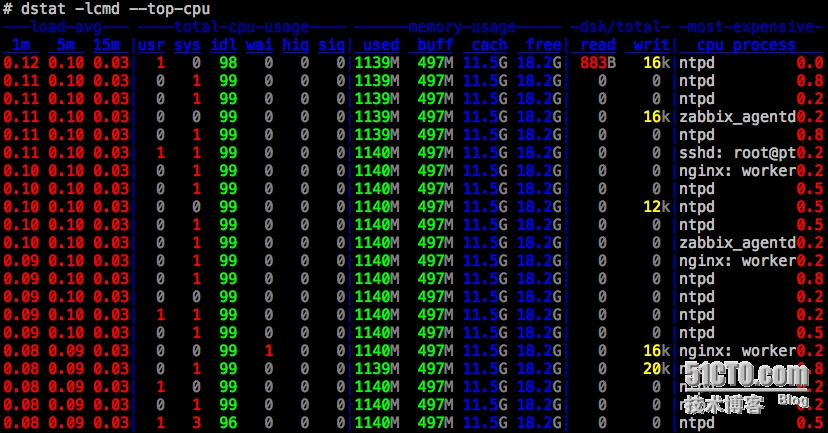
dstat也是一个比较综合的工具
这里用来找到cpu暂用率最高的参数如下
dstat -lcm --top-cpu
下图可以看到,ntpd(时间服务)和zabbix的agent消耗cpu多点(其实也不多,才0.x%)
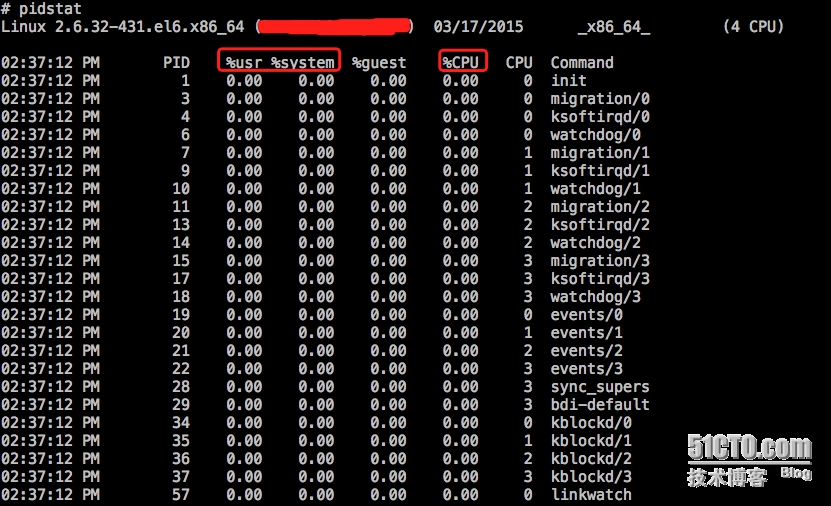
3、pidstat
直接输入pidstat(或者pidstat -l,会把命令的绝对路径输出)就可以看到进程使用cpu相关数据
【内存】
一般我们对内存关注几个指标:
(1)是否使用了大量的交换空间:如果使用了大量的交换空间,说明有问题了(内存不够?还是说有进程异常?)
(2)每个进程消耗了多少内存空间:
对于内存的查看,最简单就是free,还有dstat和top
1、free
通过free -m 我们看到,swap没有使用,内存充足

2、dstat
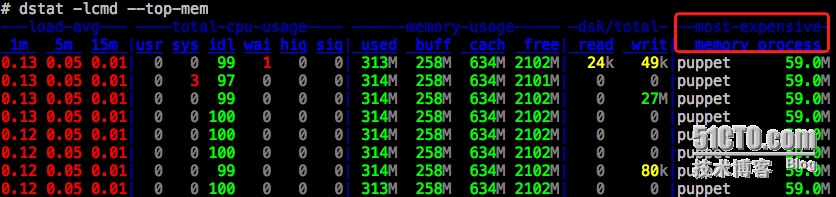
查看哪个进程消耗了最多的内存
输入dstat lcmd -top-mem
看到,就puppet消耗了最多的内存59m(正常)
3、top
输入top之后,输入b,再输入x,再输入shift+’>’或者shif+’
【磁盘】
一般我们对磁盘关注几个指标:
(1)读写的量/秒:dstat和iostat(全局),iotop或者pidstat(进程级别)
(2)每次读写磁盘的延迟时间:iostat(全局)
dstat,iostat用于查看全局的io情况,要精确到进程用iotop或者pidstat
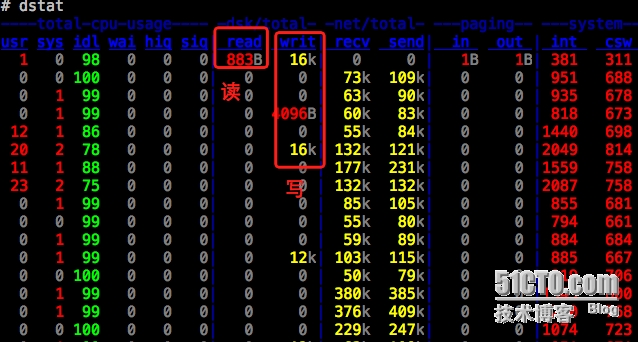
dstat:可以看到磁盘每秒的读、写取量(单位还整理过,所以一般我看磁盘的读写量都会用这个工具)
iostat就可以看到:磁盘的磁盘每秒的读、写取量并且还可以看到io的延迟效果(一般我看io的延迟会用这个工具)
1、dstat
dstat可以看到每秒读写多少B、K、M的数据
dstat其他参数和常用使用还有:
dstat -g -l -m -s --top-mem
dstat -c -y -l --proc-count --top-cpu
2、iostat
也可以看到类似的效果,而且更加丰富
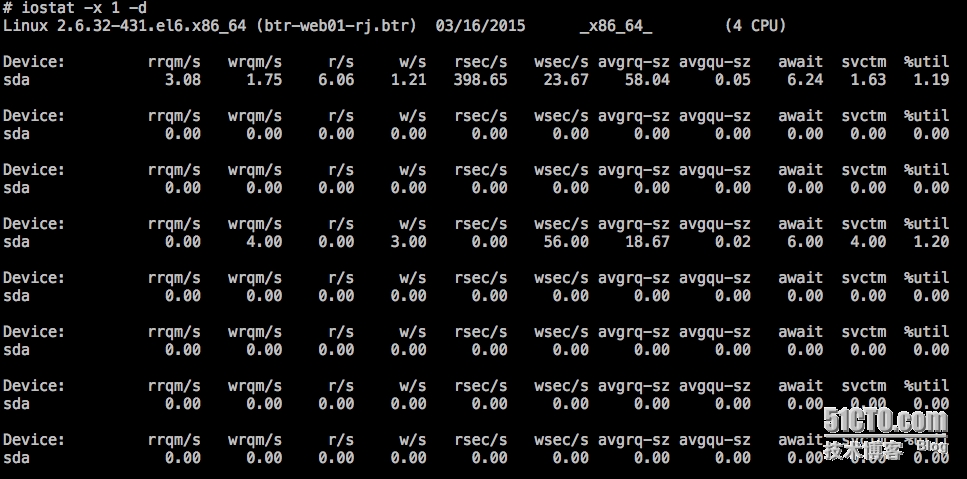
svctm < await (同时等待的请求的等待时间被重复计算),
如果 svctm 比较接近 await,说明I/O 几乎没有等待时间;
如果 await 远大于 svctm,说明 I/O 队列太长
await: 平均每次设备I/O操作的等待时间 (毫秒)。即 delta(ruse+wuse)/delta(rio+wio)
svctm: 平均每次设备I/O操作的服务时间 (毫秒):会将await也计算在内
%util: 一秒中有百分之多少的时间用于 I/O 操作,或者说一秒中有多少时间 I/O 队列是非空的。即 delta(use)/s/1000 (因为use的单位为毫秒)
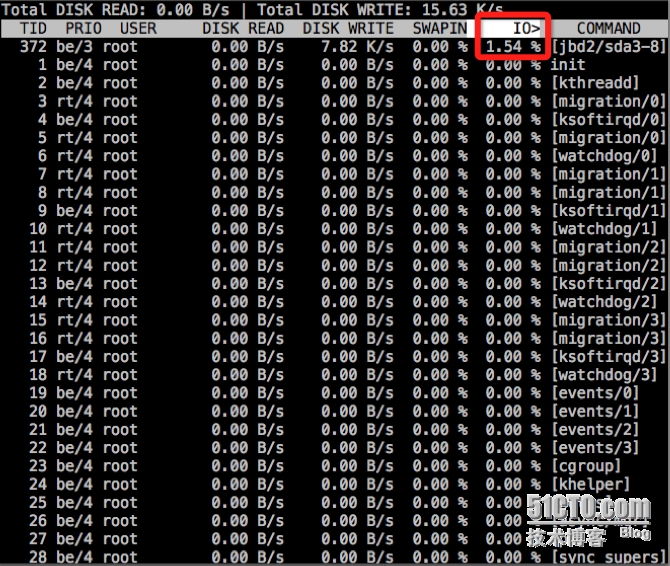
3、iotop
通过iotop直接看得到io占用最高的进程,直接输入iotop命令,效果如下
4、pidstat
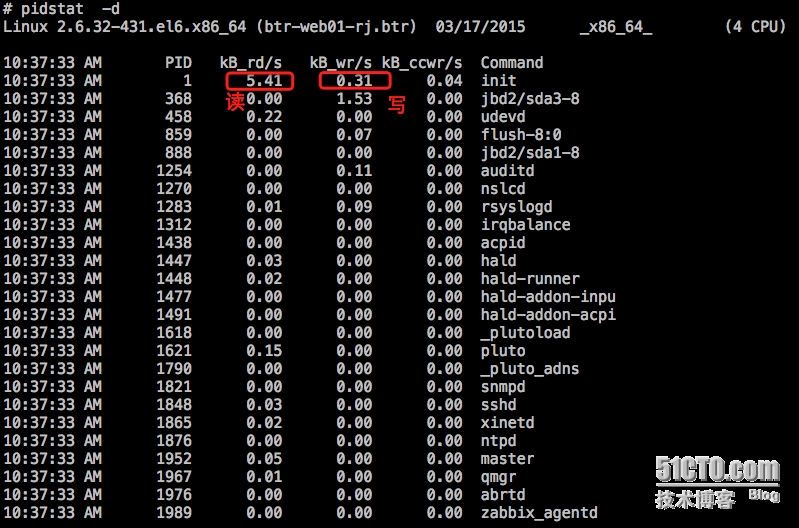
通过pidstat -d也可以看到读写磁盘数据多的进程,pidstat -d效果如下:
【网络】
一般网络主要关注性能指标:
(1)出入的流量
(2)连接状态:各个状态如established,timewait等
(3)本地监听,消耗的端口数量等
接下来介绍三个工具
1、ss
ss命令用于功能和netstat差不多,用于查看网络连接状态。
ss:消耗资源低;和netstat相比,比较快的原因在于:“ss快的秘诀在于,它利用到了TCP协议栈中tcp_diag。tcp_diag是一个用于分析统计的模块,可以获得Linux 内核中第一手的信息,这就确保了ss的快捷高效。当然,如果你的系统中没有tcp_diag,ss也可以正常运行,只是效率会变得稍慢”(zz)
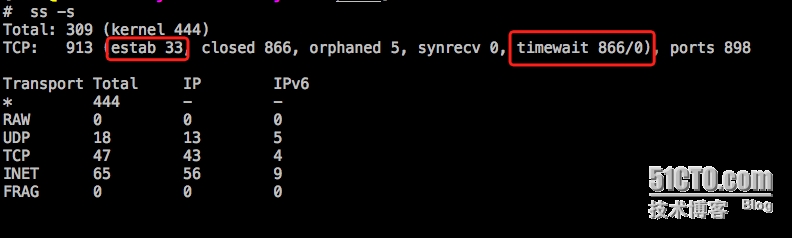
以下的实例说明当前已经建立了连接33个,timewaite有866个(可以考虑优化了)
以下的示例说明本地打开了哪些端口

2、iftop
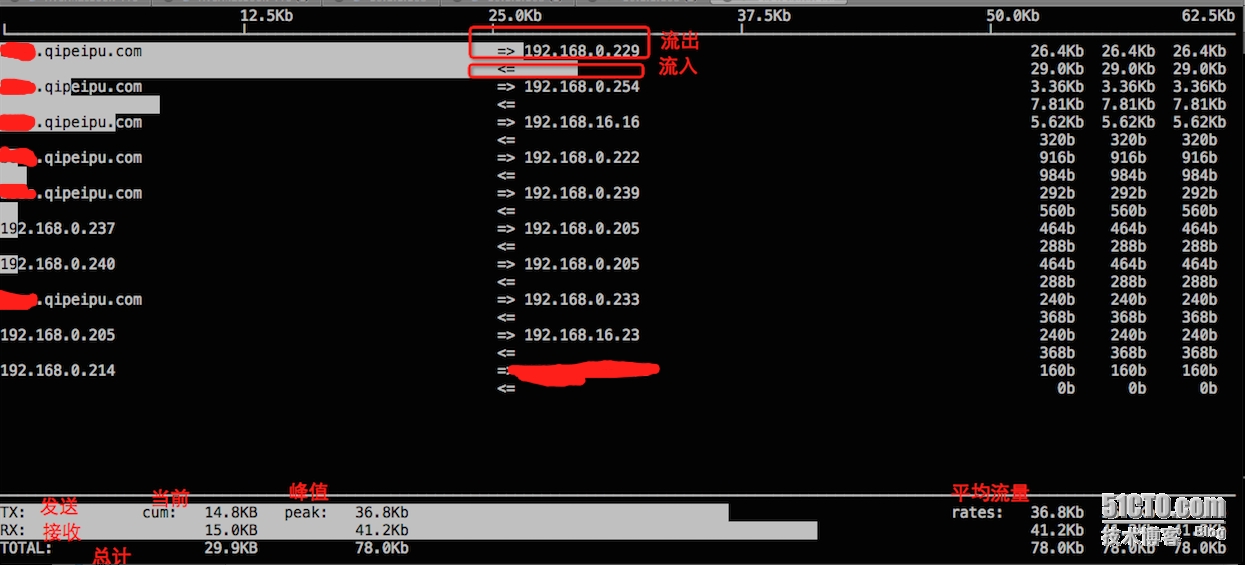
通过iftop可以看到本机和哪些ip域名之间的流量很大:
直接输入top既可以看到:
iftop命令相关参数介绍如下:
-i设定监测的网卡,如:# iftop -i eth1
-B 以bytes为单位显示流量(默认是bits),如:# iftop -B
-n使host信息默认直接都显示IP,如:# iftop -n
-N使端口信息默认直接都显示端口号,如: # iftop -N
-F显示特定网段的进出流量,如# iftop -F 10.10.1.0/24或# iftop -F 10.10.1.0/255.255.255.0
-h(display this message),帮助,显示参数信息
3、nethogs
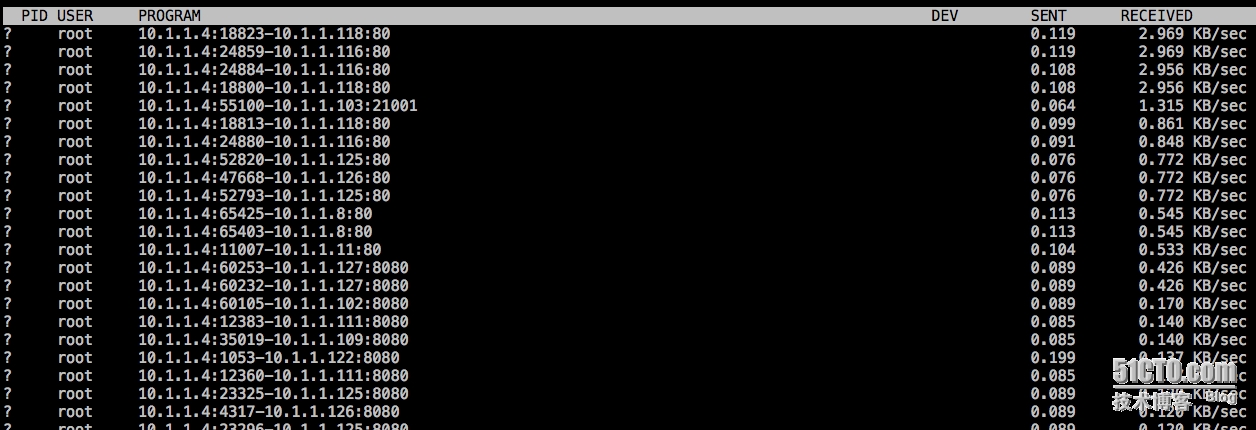
nethogs能直接就看到进程级别的流量
直接输入nethogs em2(网卡)就可以看到本地的哪些端口和对端的哪些端口之间的流量,从而就知道哪些进程消耗了很多网络流量了
【小结】
以上工具,从cpu、内存、磁盘,网络维度,能查到各个进程消耗相关性能(资源)的具体情况,对系统性能出异常时,定位至进程级别是十分有帮助了。
现在就进入下一个问题,当系统性能异常定位至进程时,怎样进一步跟进下去?甚至深入至代码级别(如果是代码有异常,而非硬件异常)?
nb的运维攻城狮是不会就此打住的,需要进一步去深入调查的^_^















 479
479











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









