






1.使用说明
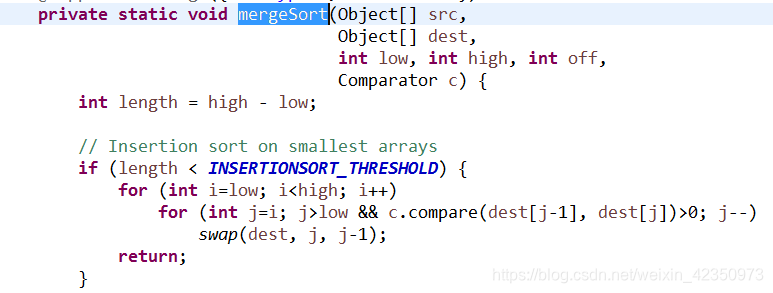
comparetor接口(外部排序接口):新建类Student以及实现接口的StudentComparator,重写compare方法,比较顺序是先按照age降序,然后id升序,对于compare写法与排序关系,详见附图,数据量比较少时为典型升序冒泡排序算法。
package com.hbtx;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Collections;
import java.util.Comparator;
import java.util.List;
public class LearnComparable {
public static void main(String[] args) {
Student s1=new Student(10, "张三", 10101, 100);
Student s2=new Student(12, "张四", 10110, 100);
Student s3=new Student(12, "张全", 10109, 100);
Student s4=new Student(15, "张鬼", 10111, 100);
Student s5=new Student(19, "张飞", 10111, 100);
Student s6=new Student(18, "张医德", 10177, 100);
List<Student>list=new ArrayList<>();
list.add(s1);
list.add(s2);
list.add(s3);
list.add(s4);
list.add(s5);
list.add(s6);
new String();
Collections.sort(list,new StudentComparator());
for(Student s:list){
System.out.println(s);
}
}
}
class StudentComparator implements Comparator<Student>{
@Override
public int compare(Student o1, Student o2) {
if(o1.age<o2.age){
return 1;
}else if(o1.age>o2.age){
return -1;
}else if(o1.id<o2.id){
return -1;
}else if(o1.id>o2.id){
return 1;
}else{
return 0;
}
}
}
class Student{
int age;
String name;
int id;
private int gre;
public Student(int age, String name, int id, int gre) {
super();
this.age = age;
this.name = name;
this.id = id;
this.gre = gre;
}
@Override
public String toString() {
return "Student [age=" + age + ", name=" + name + ", id=" + id + ", gre=" + gre + "]";
}
}
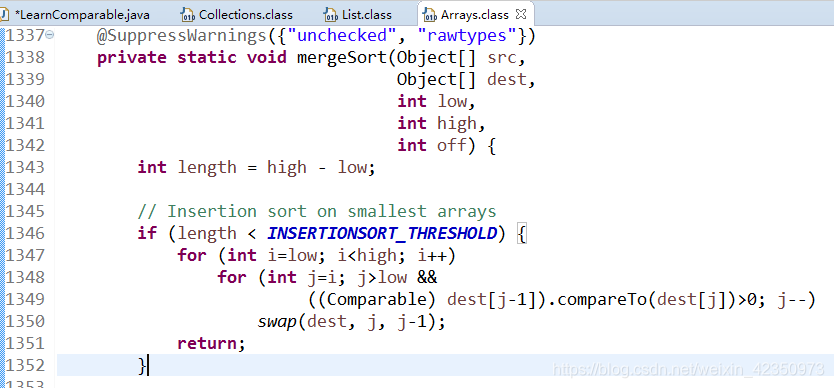
 comparable接口(内部排序接口):新建类Student实现comparable接口,重写compareTo方法,比较顺序是先按照age降序,然后id升序,对于compareTo写法与排序关系,详见附图,数据量比较少时为典型升序冒泡排序算法。
comparable接口(内部排序接口):新建类Student实现comparable接口,重写compareTo方法,比较顺序是先按照age降序,然后id升序,对于compareTo写法与排序关系,详见附图,数据量比较少时为典型升序冒泡排序算法。
 主要区别:comparator接口通过引入外部类,不需要改变待比较对象的类结构,实现排序;comparable则是改变待比较对象的类结构,实现排序;
主要区别:comparator接口通过引入外部类,不需要改变待比较对象的类结构,实现排序;comparable则是改变待比较对象的类结构,实现排序;
应用实例:
算法题1:
题目描述
输入一个正整数数组,把数组里所有数字拼接起来排成一个数,打印能拼接出的所有数字中最小的一个。例如输入数组{3,32,321},则打印出这三个数字能排成的最小数字为321323。
基于comparator的实现代码(不可能去改变Integer的类结构,所以comparable不合适)
import java.util.*;
public class Solution {
public String PrintMinNumber(int [] numbers) {
if(numbers==null||numbers.length<1)return new String();
ArrayList<Integer>list=new ArrayList<>();
for(int i=0;i<numbers.length;i++){
list.add(numbers[i]);
}
Collections.sort(list,new Comparator<Integer>(){
@Override
public int compare(Integer str1,Integer str2){
String str3=str1+""+str2;
String str4=str2+""+str1;
return str3.compareTo(str4);
}
});
StringBuilder sb=new StringBuilder();
while(list.size()>0){
sb.append(list.remove(0));
}
return sb.toString();
}
}
算法题二:
如何得到一个数据流中的中位数?如果从数据流中读出奇数个数值,那么中位数就是所有数值排序之后位于中间的数值。如果从数据流中读出偶数个数值,那么中位数就是所有数值排序之后中间两个数的平均值。我们使用Insert()方法读取数据流,使用GetMedian()方法获取当前读取数据的中位数。
选取comparator的理由同上
import java.util.*;
public class Solution {
//小顶堆
PriorityQueue<Integer> minQueue=new PriorityQueue<>();
//大顶堆
PriorityQueue<Integer> maxQueue=new PriorityQueue<>(10,new Comparator<Integer>(){
@Override
public int compare(Integer o1, Integer o2) {
return o2 - o1;
}
});
int count=0;
public void Insert(Integer num) {
if(count%2==0){
maxQueue.add(num);
minQueue.add(maxQueue.poll());
}else{
minQueue.add(num);
maxQueue.add(minQueue.poll());
}
count++;
}
public Double GetMedian() {
if(count%2==0)
return new Double(minQueue.peek()+maxQueue.peek())/2;
else
return new Double (minQueue.peek());
}
}
一句话:当待比较对象类结构比较复杂时,或者JDK内封装类时,选择comparator,其他情况两种接口都可,但是一般推荐comparator














 1355
1355











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









