







#########后面想到了更好的方式,见下篇:天眼查新方式信息爬取##########
#难点:
-
1.数据接口很难找到,反爬措施很强,所以用的seleium模拟抓取
-
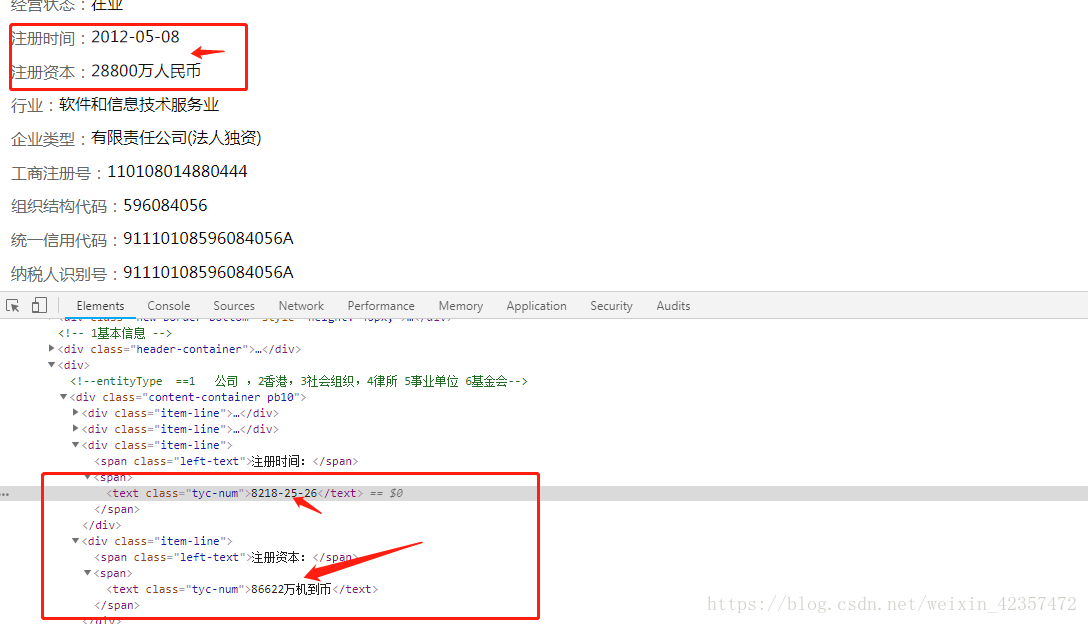
2.页面数据字体进行了异常,需要进行反向破解
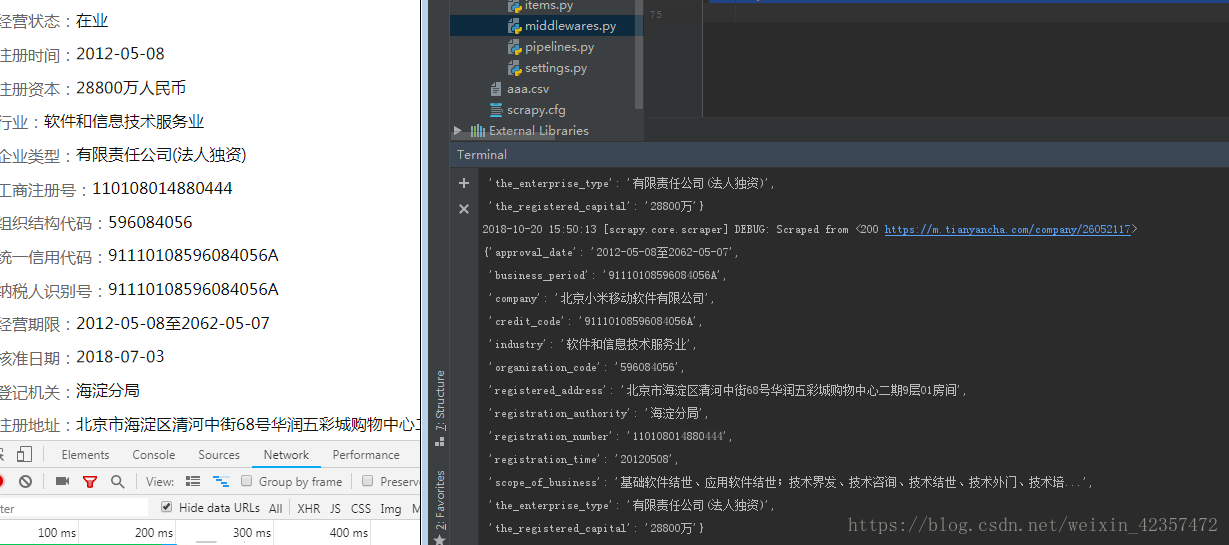
###本文用的是天眼查移动端 m.tianyancha.com 进行抓取,输入公司名可以抓取前面5条具体信息展示
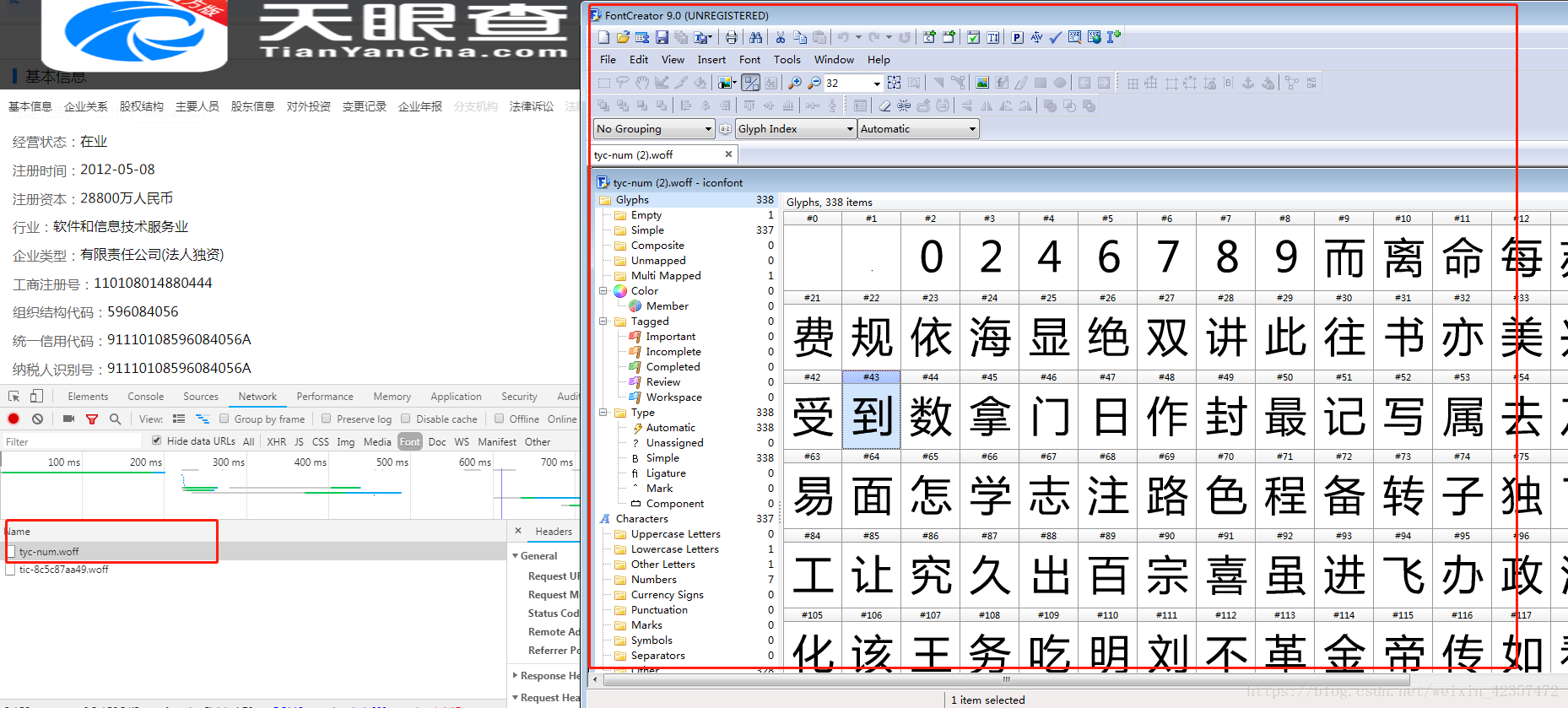
###还有网站字体异常反爬每天都会更新,所以需要后面使用的需要排除去除,用fontcreator软件
###代码抓取也有些注意点,用的google无头headless浏览器
**#Spider文件
# -*- coding: utf-8 -*-
import scrapy
from tianyancha.items import TianyanchaItem
import re
from fontTools.ttLib import TTFont
#aa需要更新维护反爬
aa = {
2: 0,
8: 2,
0: 4,
7: 6,
9: 7,
6: 8,
4: 9,
1: 1,
5: 5,
3:3
}
class ChaSpider(scrapy.Spider):
name = 'cha'
allowed_domains = ['m.tianyancha.com']
# start_urls = ['http://m.tianyancha.com/']
def start_requests(self):
meta={"nihao":"dawang"}
a=input("请输入要查询的企业名:")
url="https://m.tianyancha.com/search?key=%s"%a
yield scrapy.Request(url=url,callback=self.parse,meta=meta)
def parse(self, response):
meta = {"nihao": "dawang"}
url_lists=response.xpath('//div[contains(@class,"col-xs-10")]/a/@href').extract()
for url_list in url_lists:
yield scrapy.Request(url=url_list, callback=self.new_parse, meta=meta)
def new_parse(self, response):
item=TianyanchaItem()
item["company"]=response.xpath('//div[@class="over-hide"]/div/text()').extract()[0]
# item["boss"]=response.xpath('/html/body/div[3]/div[1]/div[7]/div/div[1]/span[2]/a/text()').extract()[0]
a=response.xpath('/html/body/div[3]/div[1]/div[7]/div/div[3]/span[2]/text/text()').extract()
a = a[0].replace("-", "")
a = list(a)
bb = []
for i in range(len(a)):
aaa = a[i] # aaa出来是str
bbb = aa[int(aaa)]
bb.append(bbb)
item["registration_time"] = "".join("%s" % id for id in bb) #将列表里元素按方式拼接成字符串
# item["registration_time"]="".join("%s"%id for id in list(k)) #将列表里元素按方式拼接成字符串
b=response.xpath('/html/body/div[3]/div[1]/div[7]/div/div[4]/span[2]/text/text()').extract()[0]
b=re.findall(r"\d+",b)
b = list(b[0])
kk = []
for i in range(len(b)):
mmm = b[i] # aaa出来是str
kkk = aa[int(mmm)]
kk.append(kkk)
item["the_registered_capital"] = "".join("%s" % im for im in kk)+"万"
# item["the_registered_capital"] = "".join("%s" % id for id in list(kk))
item["industry"] = response.xpath('/html/body/div[3]/div[1]/div[7]/div/div[5]/span[2]/text()').extract()[0]
item["the_enterprise_type"] = response.xpath('/html/body/div[3]/div[1]/div[7]/div/div[6]/span[2]/text()').extract()[0]
item["registration_number"] = response.xpath('/html/body/div[3]/div[1]/div[7]/div/div[7]/span[2]/text()').extract()[0]
item["organization_code"] = response.xpath('/html/body/div[3]/div[1]/div[7]/div/div[8]/span[2]/text()').extract()[0]
item["credit_code"] = response.xpath('/html/body/div[3]/div[1]/div[7]/div/div[9]/span[2]/text()').extract()[0]
item["business_period"] = response.xpath('/html/body/div[3]/div[1]/div[7]/div/div[10]/span[2]/text()').extract()[0]
item["approval_date"] = response.xpath('/html/body/div[3]/div[1]/div[7]/div/div[11]/span[2]/text()').extract()[0]
item["registration_authority"] = response.xpath('/html/body/div[3]/div[1]/div[7]/div/div[13]/span[2]/text()').extract()[0]
item["registered_address"] = response.xpath('/html/body/div[3]/div[1]/div[7]/div/div[14]/span[2]/text()').extract()[0]
item["scope_of_business"] = response.xpath('/html/body/div[3]/div[1]/div[7]/div/div[15]/span[2]/span/span[2]/div/text/text()').extract()[0]
# print(item["company"])
# print(item["registration_time"])
# print(item["the_registered_capital"])
print(item)
yield item
#middlewares文件
from selenium import webdriver
from scrapy.http import HtmlResponse
class TianyanchaDownloaderMiddleware(object):
# Not all methods need to be defined. If a method is not defined,
# scrapy acts as if the downloader middleware does not modify the
# passed objects.
def process_request(self, request, spider):
if request.meta["nihao"] =="dawang" :
option = webdriver.ChromeOptions()
option.add_argument('--headless')
option.add_argument('--disable-gpu')
driver = webdriver.Chrome(chrome_options=option)
# driver=webdriver.Chrome()
driver.get(request.url)
content=driver.page_source
driver.quit()
return HtmlResponse(request.url,encoding="utf-8",body=content,request=request)
#########但是这种方法速度非常慢,另外字体反爬经常更新也很烦,所以后面想到了更好的方式,见下篇:天眼查新方式信息爬取##########















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











