






前言
训练一个大模型是一件高投入低回报的事情,况且训练的事情是由大的巨头公司来做的事情;通常我们是在已有的大模型基础之上做微调或Agent等;大模型的能力是毋庸置疑的,但大模型在一些实时的问题上,或是某些专有领域的问题上,可能会显得有些力不从心。因此,我们需要一些工具来为大模型赋能,给大模型一个抓手,让大模型和现实世界发生的事情对齐颗粒度,这样我们就获得了一个更好的用的大模型。
1.构造Agent
这里就简单说一下Agent的结构,Agent的结构是一个React的结构,提供一个system_prompt,使得大模型知道自己可以调用那些工具,并以什么样的格式输出。每次用户的提问,如果需要调用工具的话,都会进行两次的大模型调用,第一次解析用户的提问,选择调用的工具和参数,第二次将工具返回的结果与用户的提问整合。这样就可以实现一个React的结构,具体如下图所示。
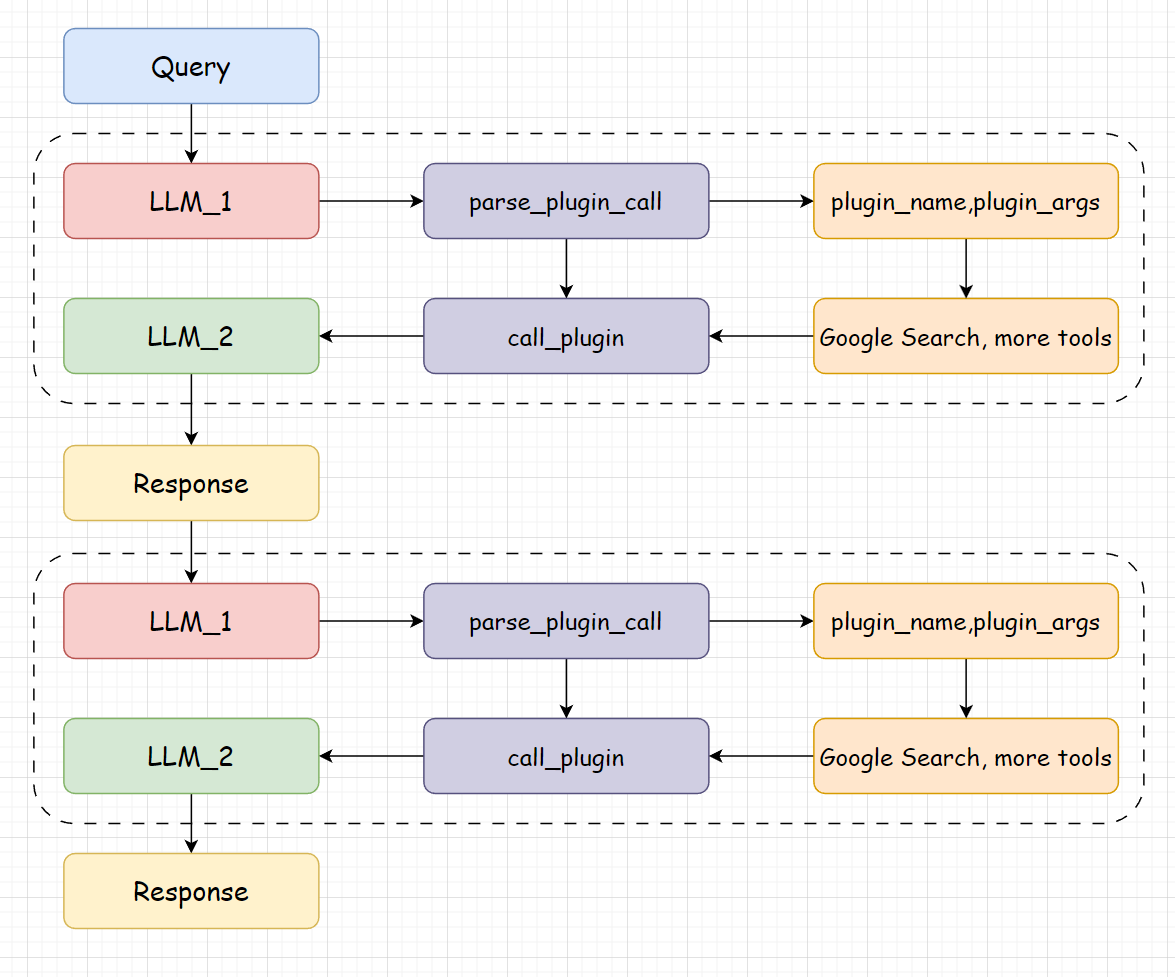
class Agent:
def __init__(self, path: str = '') -> None:
pass
def build_system_input(self):
# 构造上文中所说的系统提示词
pass
def parse_latest_plugin_call(self, text):
# 解析第一次大模型返回选择的工具和工具参数
pass
def call_plugin(self, plugin_name, plugin_args):
# 调用选择的工具
pass
def text_completion(self, text, history=[]):
# 整合两次调用
pass2.调用示例
使用了InternLM2-chat-7B模型,进行了问答测试:
3.总结
使用4060ti 16G显卡测试Agent,消耗显存15G,整体测试下来感觉 书生·浦语7b 的模型完成一些基本的问答任务没什么问题,但是联系上下文回答问题还是理解不到位;不够那么聪明。
原创作者: xinjieli 转载于: https://www.cnblogs.com/xinjieli/p/18436807















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









