



Spark-core笔记
Spark框架简介
spark 配置
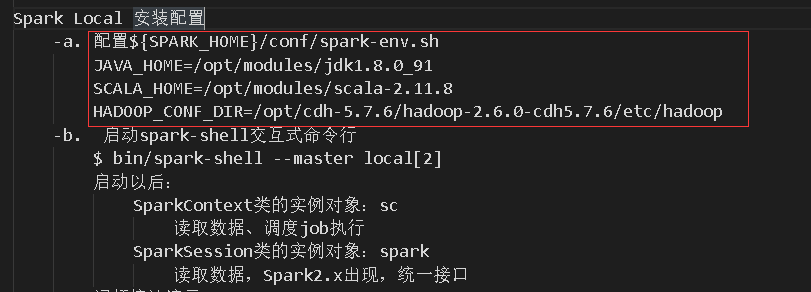
shell启动


local[2] 启动模式
spark分类
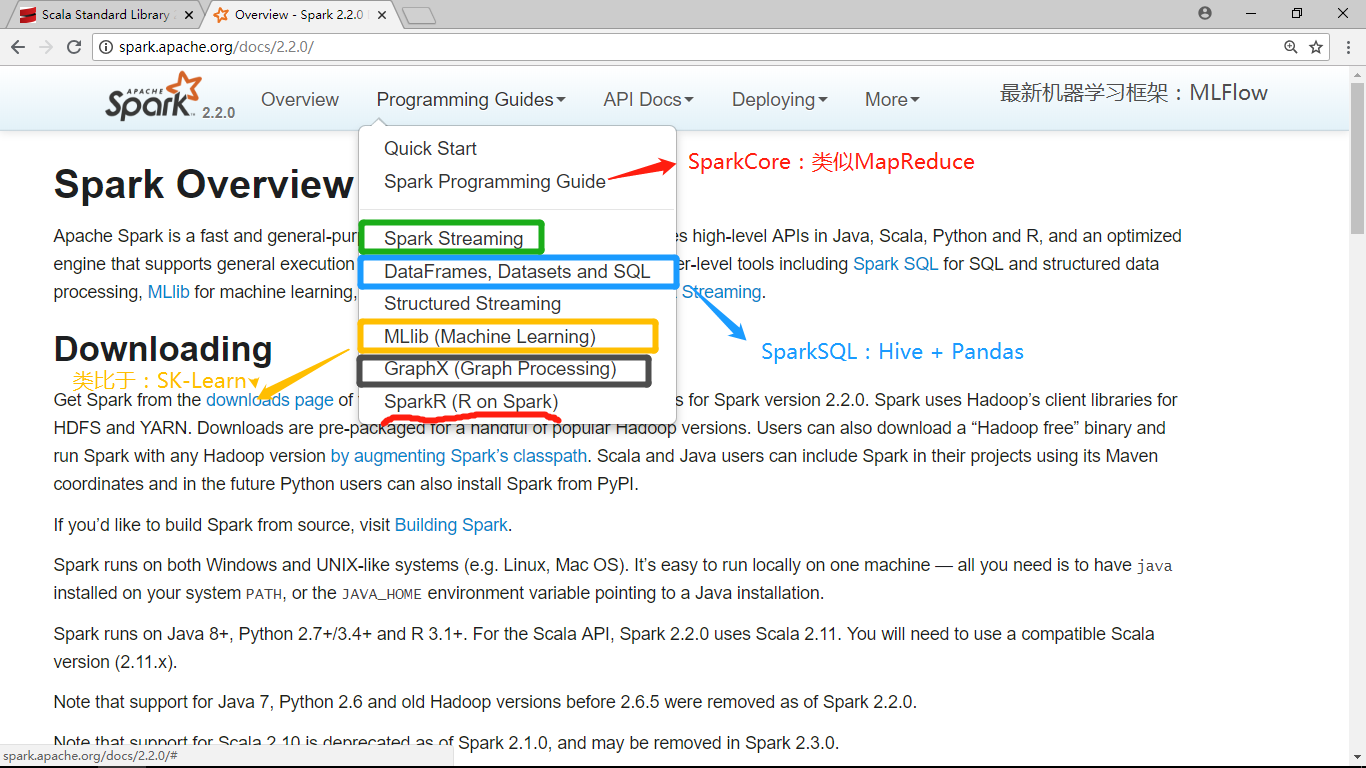
简介

spark运行模式

spark shell
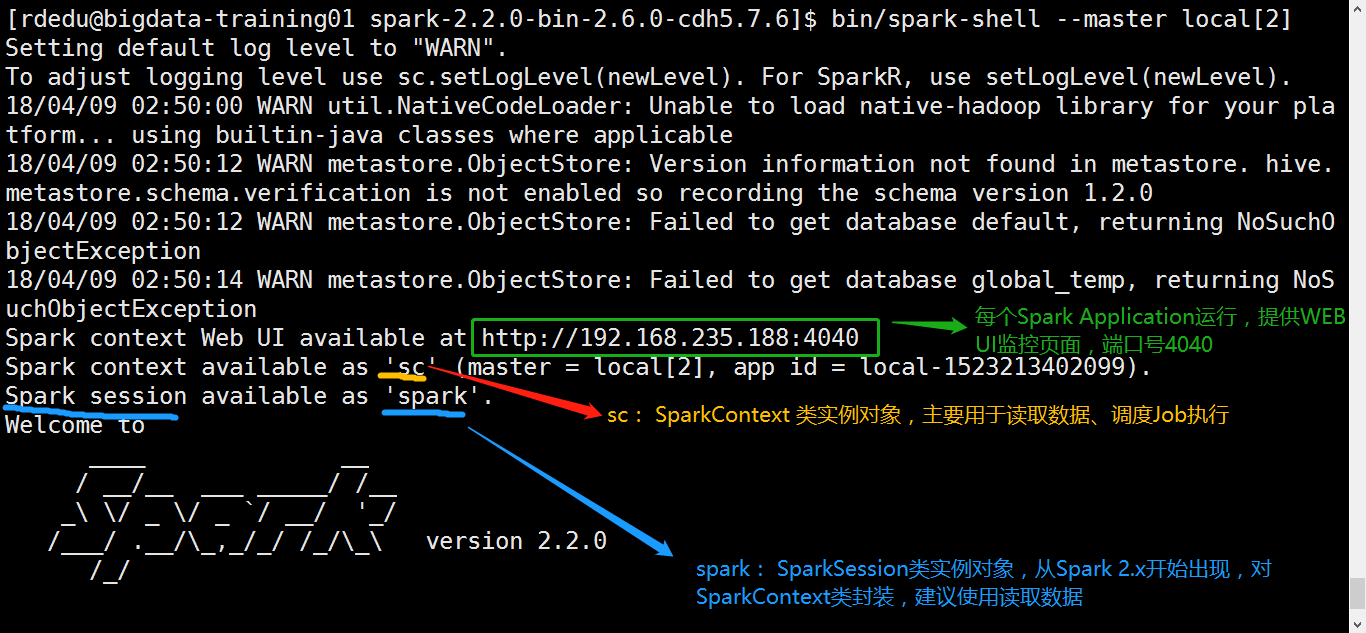
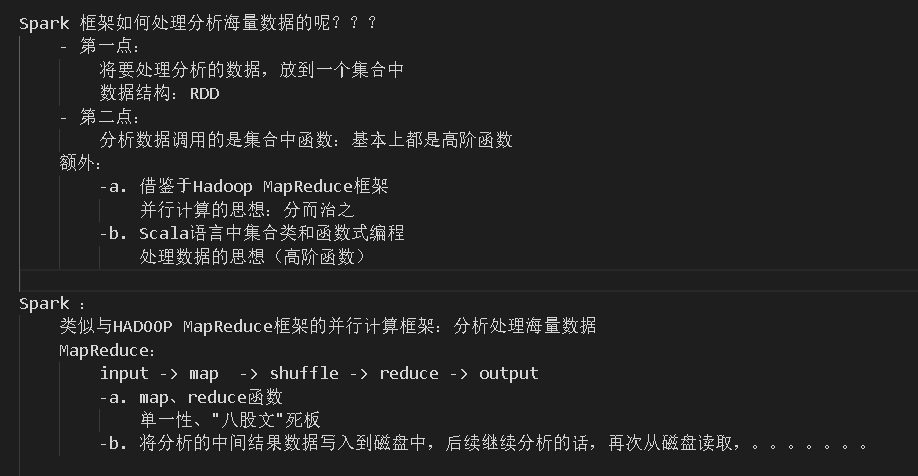
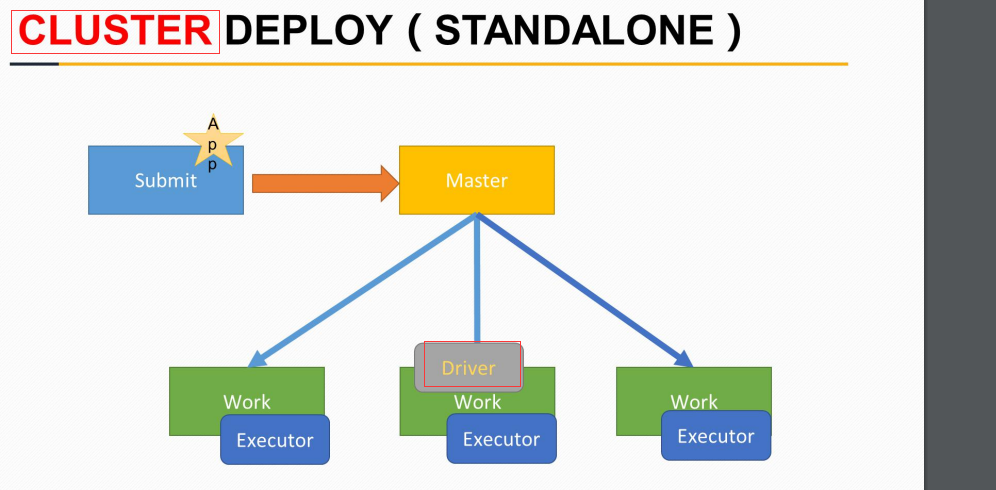
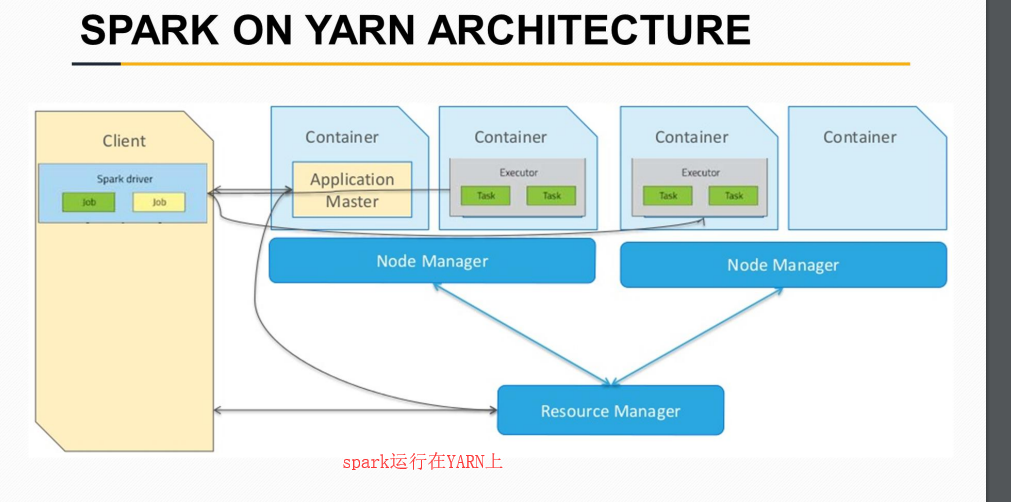
结构图、运行模式解析

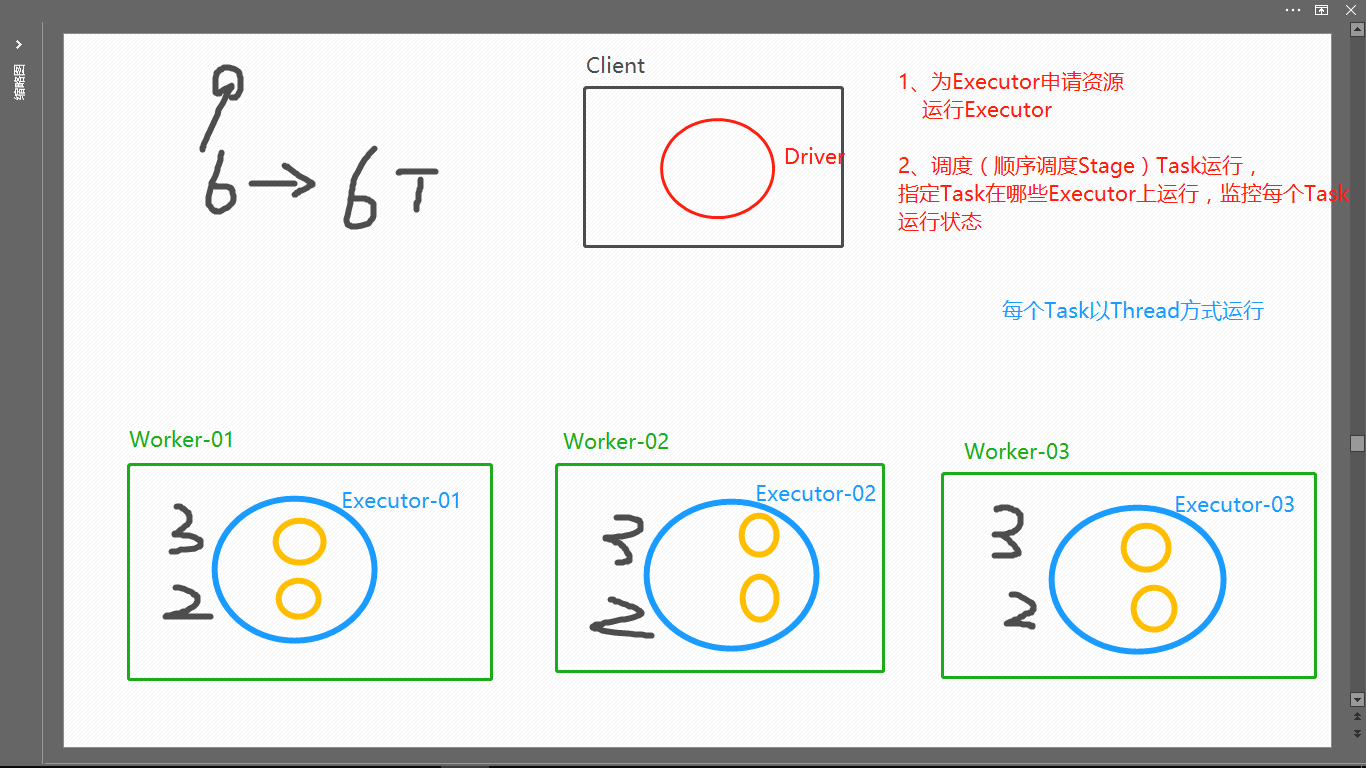
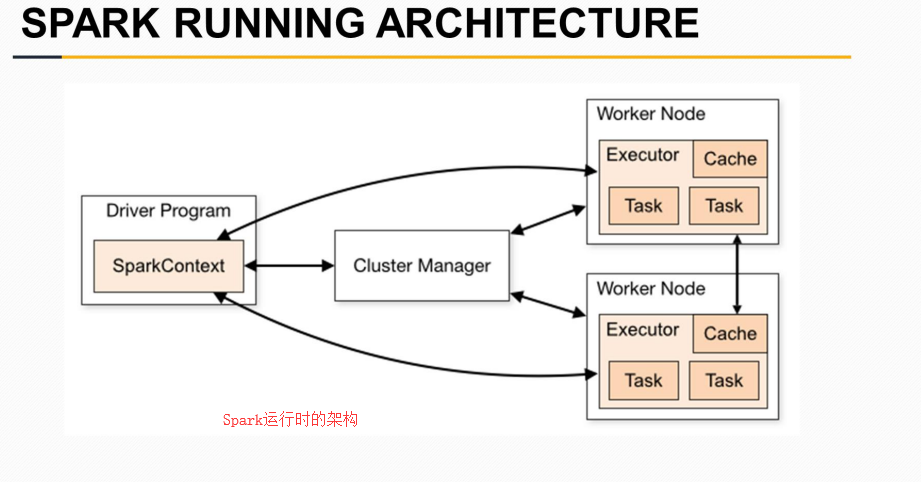
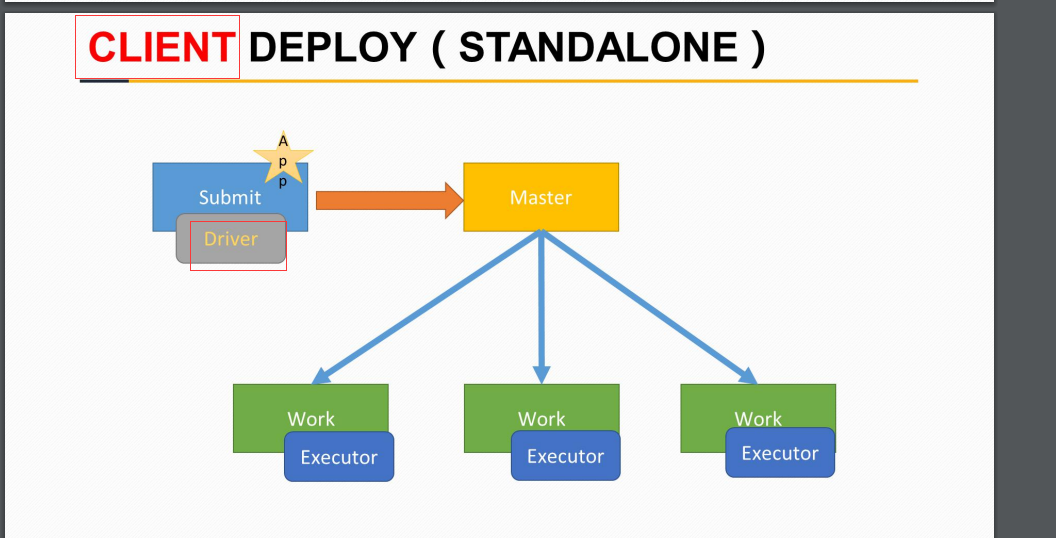
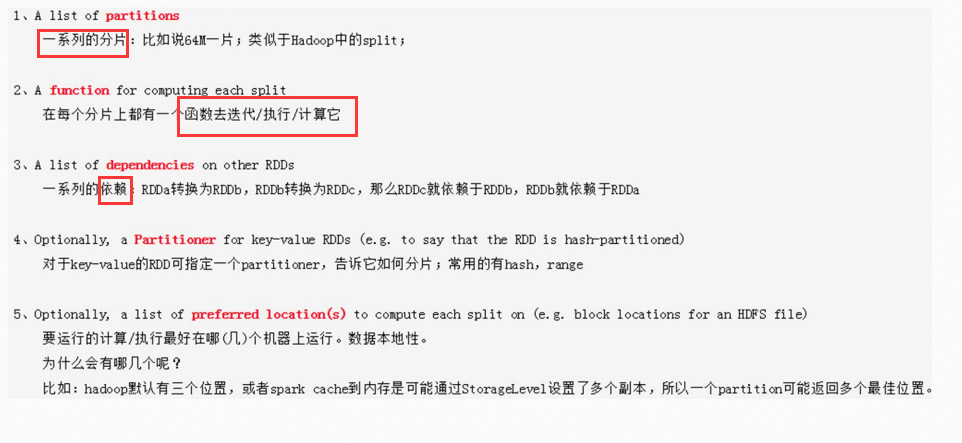
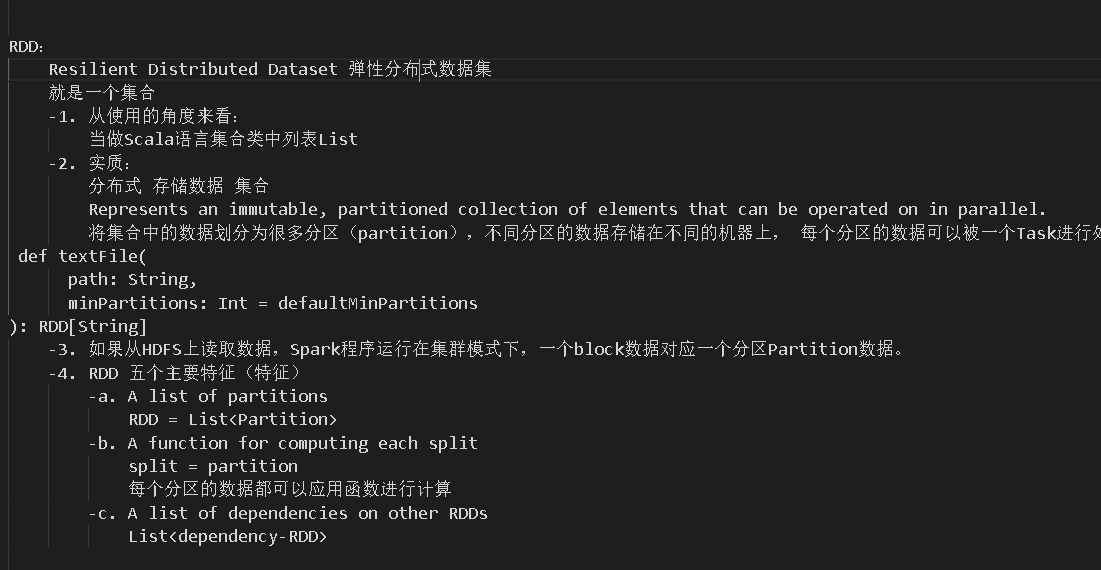
RDD
五大特点


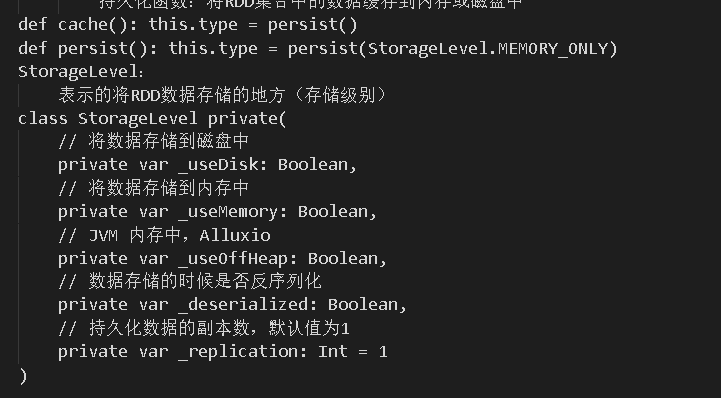


运行模式与配置
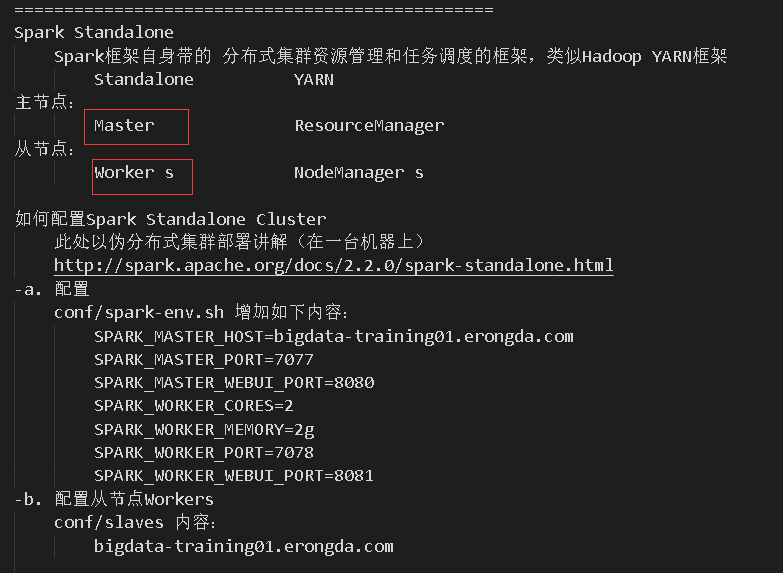
Spark程序
提交程序

自定义目录和 运行模式

运行在yarn上 并设置内存 线程
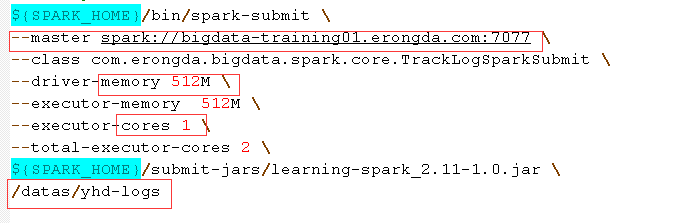
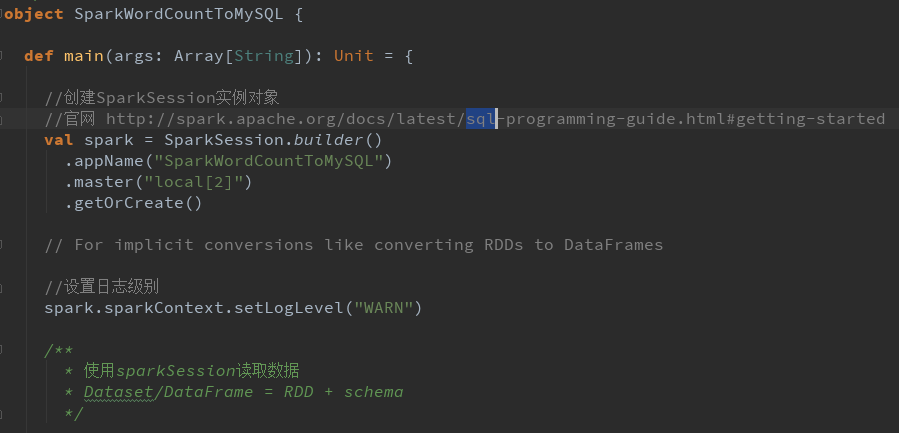
Spark开发模板
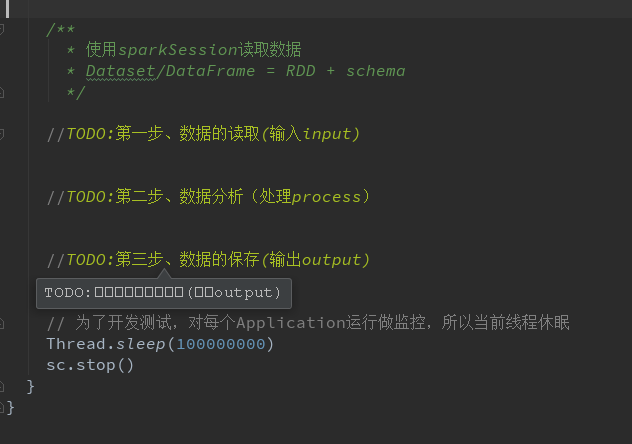
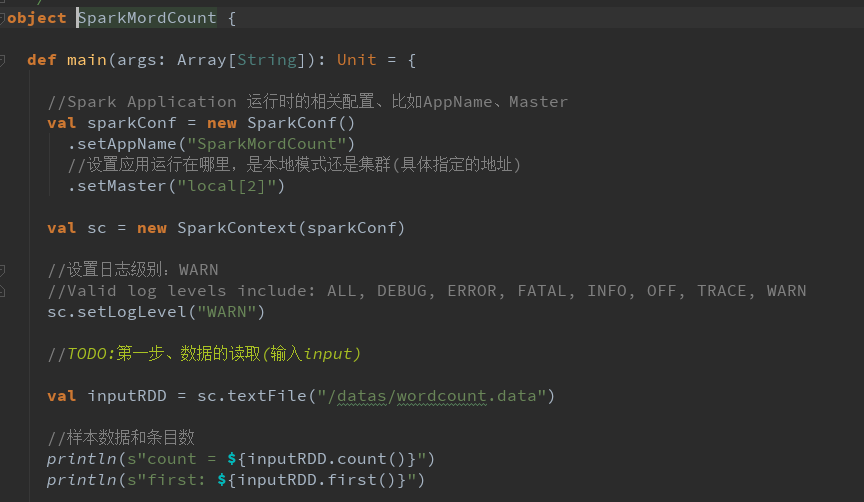
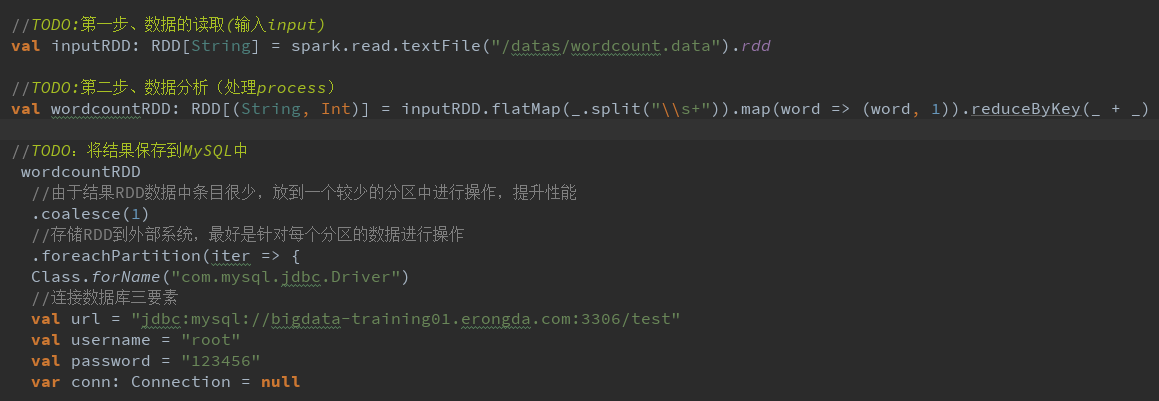
WordCount 程序
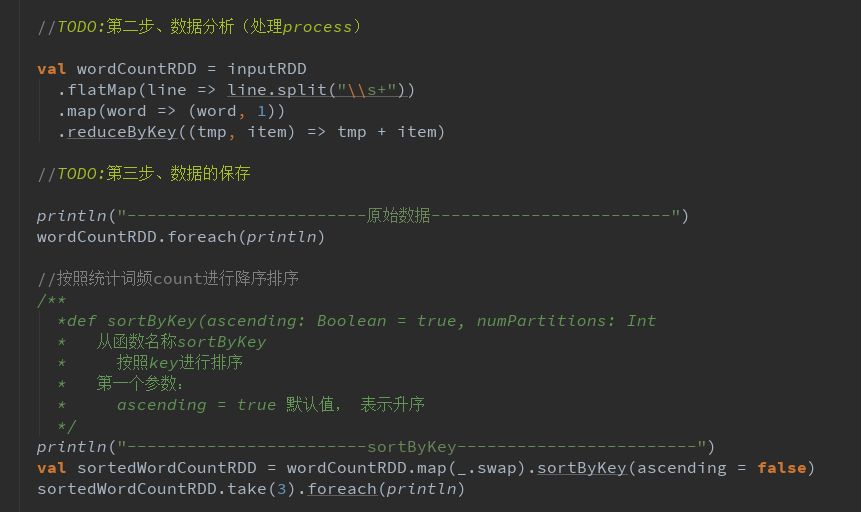

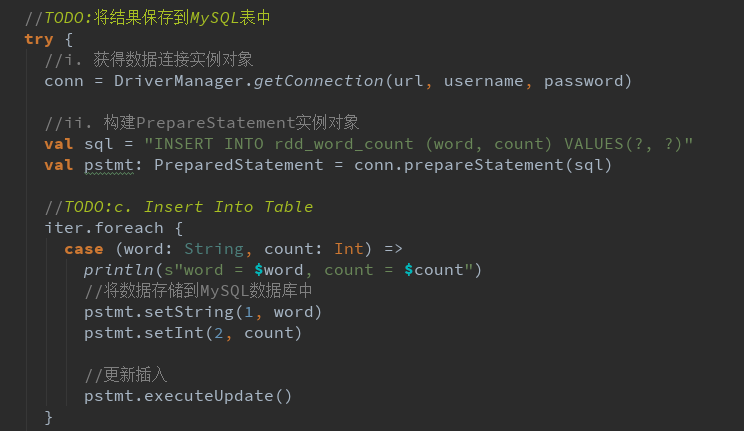
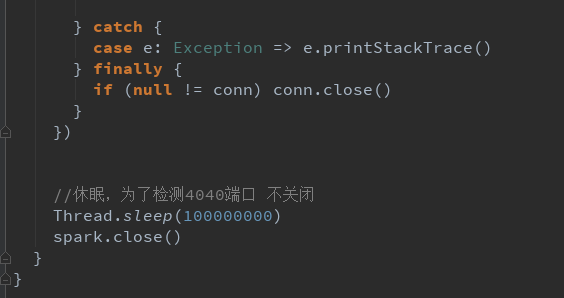
数据结果导入MySQL
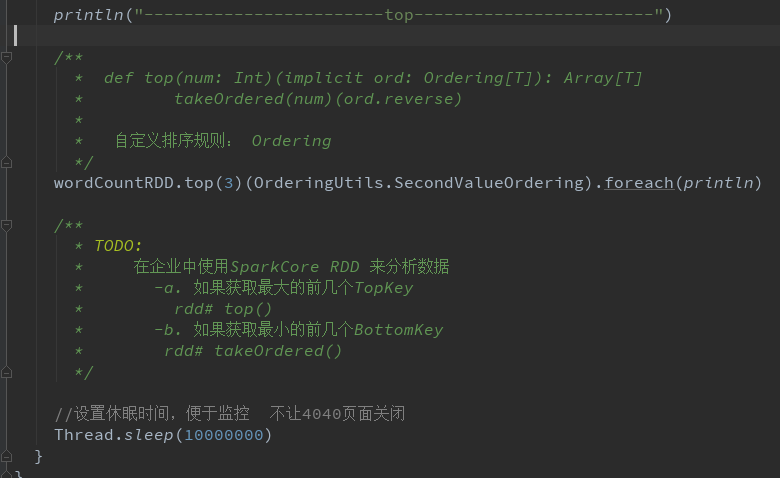
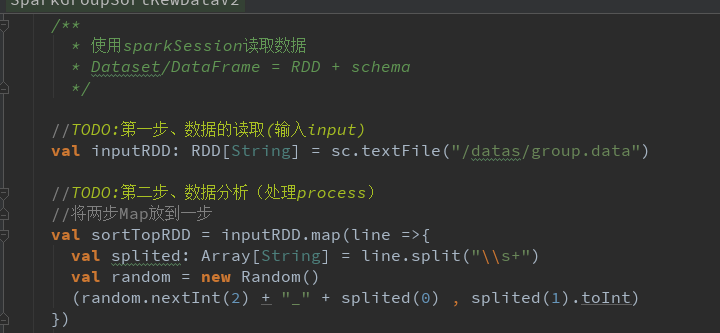
分组、排序和TopKey
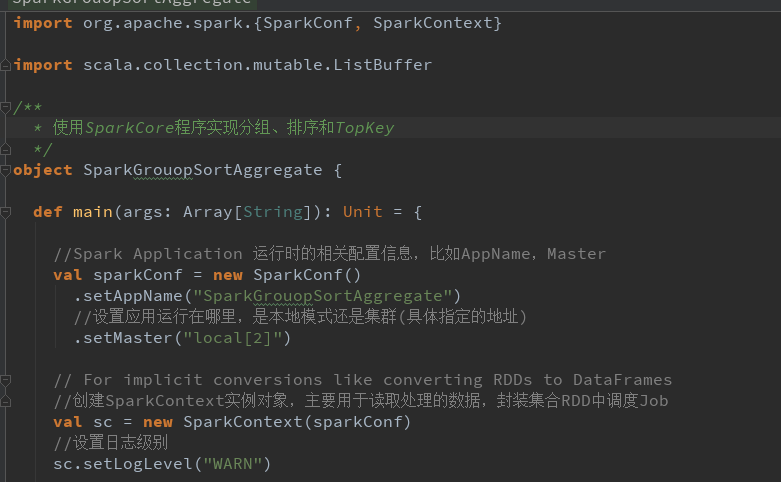
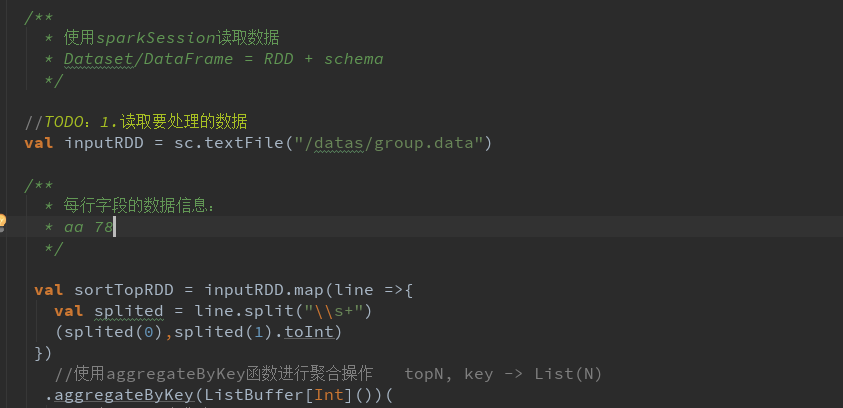
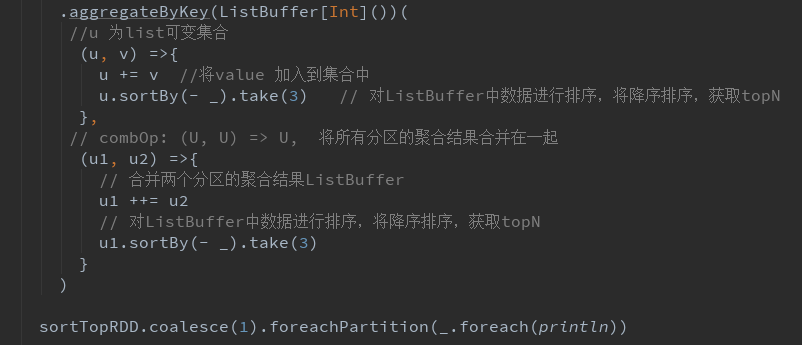

分组排序、TopKey 并且改进map和局部聚合
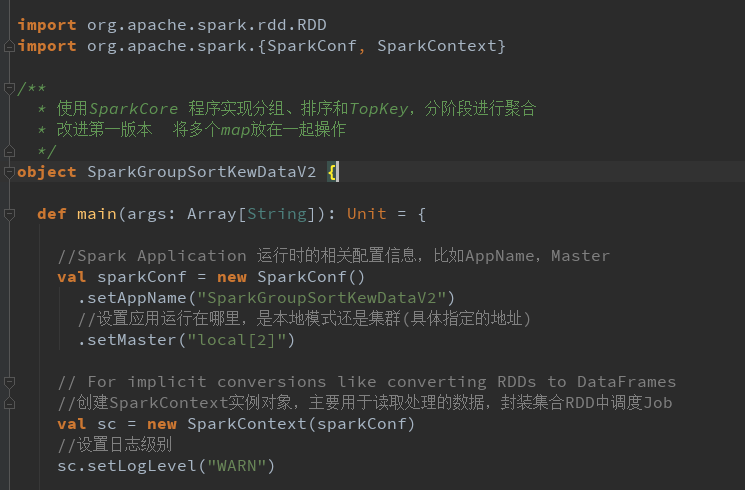


















 1304
1304

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









