







大家平时上网或者开发过程中,一定遇到过乱码吧。有时候遇到乱码会让人十分抓狂,想解决又感觉毫无头绪。
那么为什么会有乱码呢,这里就不得不提码,编码,字符集这些内容
本次分享将从4个方面来讲编码的故事

第一节 为何要编码1946年,世界上第一台计算机诞生,其实计算机很笨的,他们只能处理数字,而且从最底层来说,他们只能处理二进制数字

我们知道,计算机中存储信息的最小单元是字节,一个字节有8位,我们可以把每一位想象成一个开关,1代表开,0代表关,这样排列组合一共有256种情况,从00000000到11111111,为什么一个字节是8位,我们知道,计算机是美国人发明的,人家用8位就能把他们所用的字母,数字,符号都表示出来,根本不需要更大的位数,所以这一点是美国人说了算。
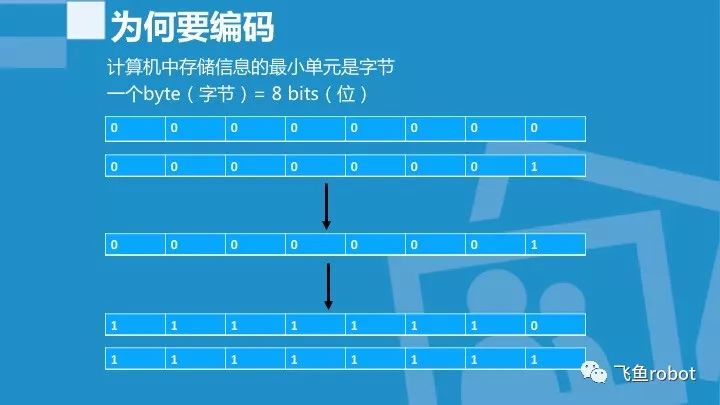
但是世界上除了美国用的英语,还有其他各种各样的语种,各种各样的符号,远远超出一个字节所能表示的符号范围,这个时候怎么办呢。我们需要一个新的数据类型去表示这些符号,但是计算机又只认识字节,这时候就必须有个转换的过程,也就是字符和字节之间的相互转换。
综上所述,我们之所以要编码主要有3个原因。
1 计算机中存储信息的最小单元是一个字节即 8 个 bit,所以能表示的字符个数最多是256个
2 人类世界的符号太多了,无法用一个字节来完全表示,必须用到更多的字节,比如双字节能存65536个数字。要解决这个矛盾必须需要一个新的数据类型char(字符),从char(字符)到byte(字节)必须编码
3 实际上编码的过程是char数组映射为byte数组(字符->字节),而解码的过程就是byte数组映射为char数组(字节->字符)
第二节 各种字符集和编码在进行接下去的内容之前,我们有几个概念需要强调一下。字符、字符集、字符编码、字符集和字符编码之间的关系。
字符:一个字符是一个单位的字形、类字形单位或符号的基 本信息。比如一个中文汉字、一个英文字母、一个阿拉伯数字、一个标点符号等。
字符集:多个字符的集合。例如GB2312是中国国家标准的简体中文字符集
字符编码:把字符集中的字符映射为特定字节或字节序列,是一种规则
字符集和字符编码关系:通常特定的字符集采用特定的编码方式,这里视为同义词
各种字符集和编码--ASCII
ASCII(发音: /ˈæski/ ass-kee,American Standard Code for Information Interchange,美国信息交换标准代码)是基于拉丁字母的一套计算机编码系统。它主要用于显示现代英语。最初发布于1963年。
首先是ascii码,这个大家应该都很熟悉,学计算机接触的第一种编码应该就是他。这个ascii码是从电报码发展来的,他的首次商业使用是作为一种7位的电报码。ascii码的前32个码被用作控制码,这种码是打印不出来的,是用来控制设备的,比如10(十进制)0A(十六进制)代表“LineFeed”,也就\n换行,这个码让打字机的纸前进一点,相当于换行了,第13个码0D代表“carriagereturn”,这个码可以让打印头回到一行的最前面,也就是我们熟悉的\r回车
后面的码就是可打印的字符,比如说字母,数字,标点符号等
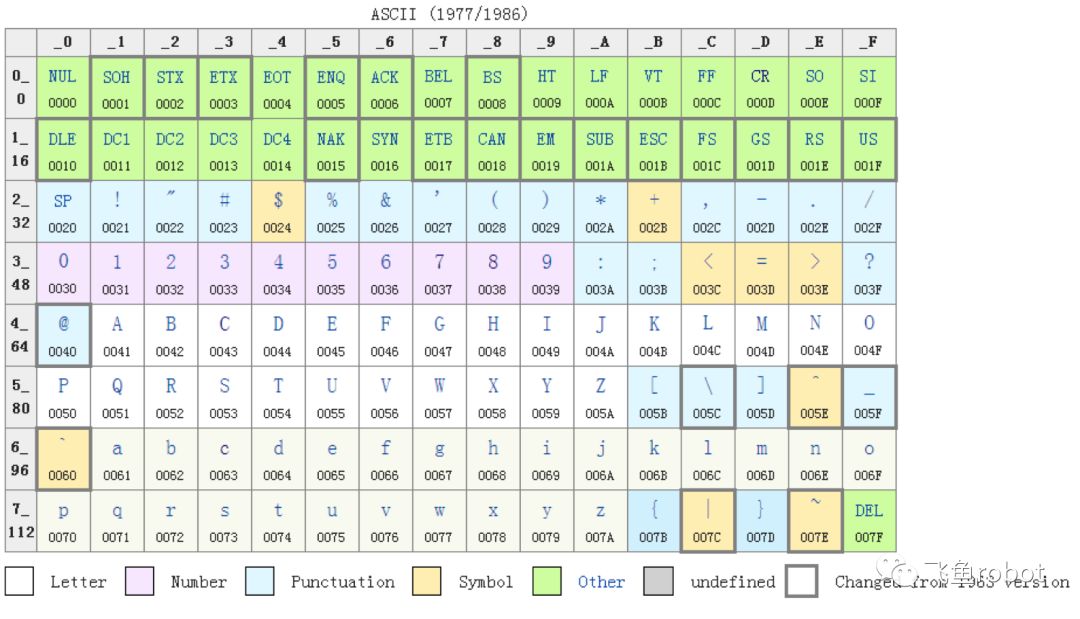 特点
特点
只使用了一个字节的后7位
一共能表示128个字符
32个不能打印的控制字符
英文标点、数学运算符、阿拉伯数字和大小写拉丁字母(英文字母)
缺点
只能用于显示现代英语
各种字符集和编码--EASCII
EASCII(Extended ASCII,延伸美国标准信息交换码),一些欧洲国家利用ASCII码中闲置的最高位,来编入新的符号
后来欧洲人也要使用计算机了,对于他们来说,最大的问题就是字母表了,毕竟欧洲语种很多,很多字母和英文字母很像,但是又不太一样,因此出现了很多不同版本的7位ascii码变种,做法就是将码表中一些用不到的字符换成他们常用的。后来就直接把ascii码中闲置的最高位也用上了,这样就能多放入128个字符了
特点:
用到了一个字节的全部8位
兼容ASCII
缺点:
每个国家有不同的字母,同一个码在不同国家可能代表不同字母
各个厂家都有自己的想法,大家没有统一标准
只能用于欧洲国家
各种字符集和编码—ISO 8859系列
ISO 8859 ISO 8859是一系列8位字符集的标准,主要为世界各地的不同语言(除中日韩)而单独编写的字符集,其下共包含了15个字符集,即ISO/IEC 8859-n,其中n=1,2,3,...,15,16(其中12未定义,所以共15个),使用最多的是ISO 8859-1,ISO 8859-1首次推出于1987年。
国际标准化组织(ISO)及国际电工委员会(IEC)于1984年联合成立了ISO/IEC小组,主要用于开发统一编码项目
eascii码没有统一标准,这样带来的问题是显而易见的。
最终ISO站出来出台了国际标准的8位ascii码的扩展,就是著名的iso 8859系列。
特点
由ISO/IEC小组开发
是一系列8位字符集的标准
缺点
不包含中日韩字符
各种字符集和编码—GB2312
GB2312于是【中国国家标准总局】(现已更名为【国家标准化管理委员会】)在1981年,正式制订了中华人民共和国国家标准简体中文字符集,全称《信息交换用汉字编码字符集·基本集》,项目代号为GB 2312 或 GB 2312-80(GB为国标汉语拼音的首字母),此套字符集于当年的5月1日起正式实施。
gb2312包含6763个中文汉字,除此之外,还包括标点符号、日文假名、希腊字母、斯拉夫字母、注音符号、拼音等
特点
共包含7445个字符,6763个汉字和682个其他字符(拉丁字母、希腊字母、日文平假名及片假名字母、俄语西里尔字母)
每个汉字及符号以两个字节来表示,第一个字节为“高位字节”,第二个字节为“低位字节”
兼容ASCII码
缺点
没有繁体字
各种字符集和编码—BIG5
BIG5台湾信息工业策进会在1984年定义的,这个名字“Big5”是指为了纪念合作推出此标准的5个台湾最大的IT公司:分别是宏碁、神通、佳佳、零壹和大眾
刚才的gb2312是不支持繁体中文的,所以这个重任就落到了用繁体中文的台湾和香港身上。
特点
共收录13,060个汉字及441个符号
用两个字节来为每个字符编码,第一个字节称为“高位字节”,第二个字节称为“低位字节”
各种字符集和编码—ANSI
ANSI各个国家和地区独立制定的既兼容 ASCII 编码又彼此之间不兼容的字符编码,微软统称为 ANSI 编码。
在 Windows 系统中,ANSI 编码一般代表系统默认的编码方式,并且不是确定的某一种特定编码方式,比如在英文 Windows 操作系统中,ANSI 指的是 ISO-8859-1;简体中文操作系统中 ANSI 编码默认指的是 GB 系列编码(GB2312、GBK、GB18030)等;在繁体中文操作系统中 ANSI 编码默认指的是 BIG5;在日文操作系统中 ANSI 编码默认指的是 Shift JIS 等等,并且默认的 ANSI 编码可以通过设置系统 Locale 更改。
特点
兼容ASCII码
用于windows中,不是具体的某一种编码
英文 Windows 操作系统中,是 ISO-8859-1
简体中文操作系统中默认指的是 GB 系列编码(GB2312、GBK、GB18030)等
在繁体中文操作系统中默认指的是 BIG5
在日文操作系统中编码默认指的是 Shift JIS
缺点
彼此之间并不兼容,因为都不是一种编码
各种字符集和编码—UNICODE
UNICODE是计算机科学领域里的一项业界标准,包括字符集、编码方案等。可以理解为一张表,里面包含了可能出现的所有字符,每个字符对应一个数字,这个数字称为码点(Code Point),地球上所有字符都可以在Unicode表中找到对应的唯一码点。

有两个独立的, 创立单一字符集的尝试. 一个是国际标准化组织(ISO)的 ISO 10646 项目, 另一个是由多语言软件制造商组成的协会组织的 Unicode 项目. 在1991年前后, 两个项目的参与者都认识到, 世界不需要两个不同的单一字符集. 它们合并双方的工作成果, 并为创立一个单一编码表而协同工作. 两个项目仍都存在并独立地公布各自的标准, 但 Unicode 协会和 ISO/IEC JTC1/SC2 都同意保持 Unicode 和 ISO 10646 标准的码表兼容, 并紧密地共同调整任何未来的扩展。分为17个平面(plane),用0-16编号。平面0也叫作基本多文种平面(Basic Multilingual Plane)BMP,里面包含了最常用的字符
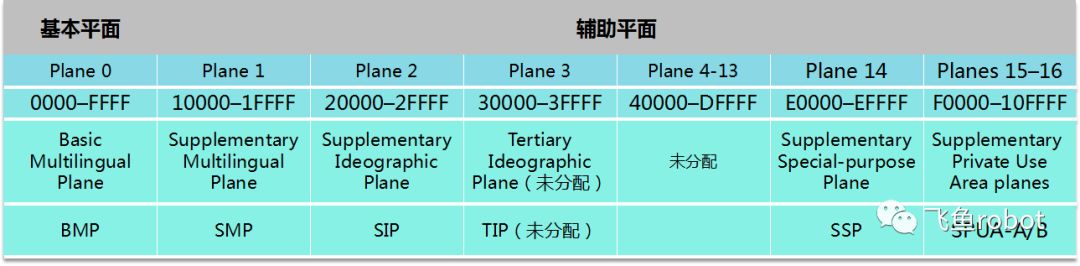
标准中,一个平面就是一组连续的65536个,2的16次方个码点。一共有17个平面,用0到16编号,这个编号正好对应着码点U+hhhhhh格式的前两位(用16进制表示)。0号平面叫做基本多语言平面,包含了绝大多数常用的字符。剩下的1到16,叫做辅助平面。整个unicode码表最后一个码点就是16平面的最后一个码点,编号是U+10FFFF。截止最新的unicode 12版,已经有6个平面有分配码点。这里弄了17个平面的限制,是因为后面要介绍的UTF-16,他能编码2的20次方个码点成4字节;UTF-8更厉害些,能最多编码2的31次方个码点,并且可以用4个字节编码2的21次方个码点。这17个平面容纳了1,114,112个码点。其中2048个代理码点用来给utf-16用作代码对,66个非字符,137,468个保留,剩下的974,530个是公用的。在往下分,会有个unicode块,和平面不同的是,它的大小不固定。暂不介绍了。。
各种字符集和编码—BMP
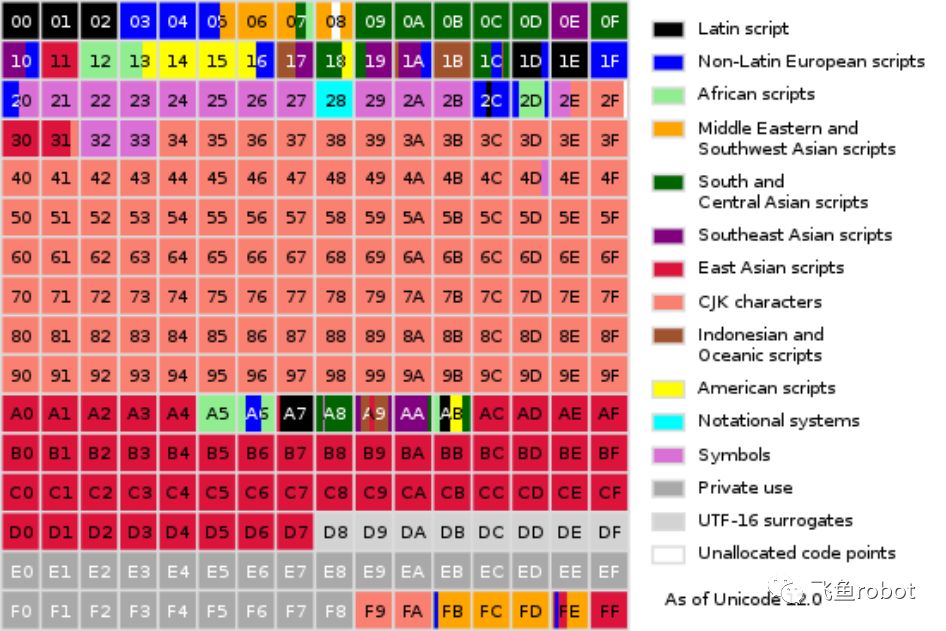
每个方格代表256个码点,0000到00FF共FF+1个码点,256个
各种字符集和编码—SSP
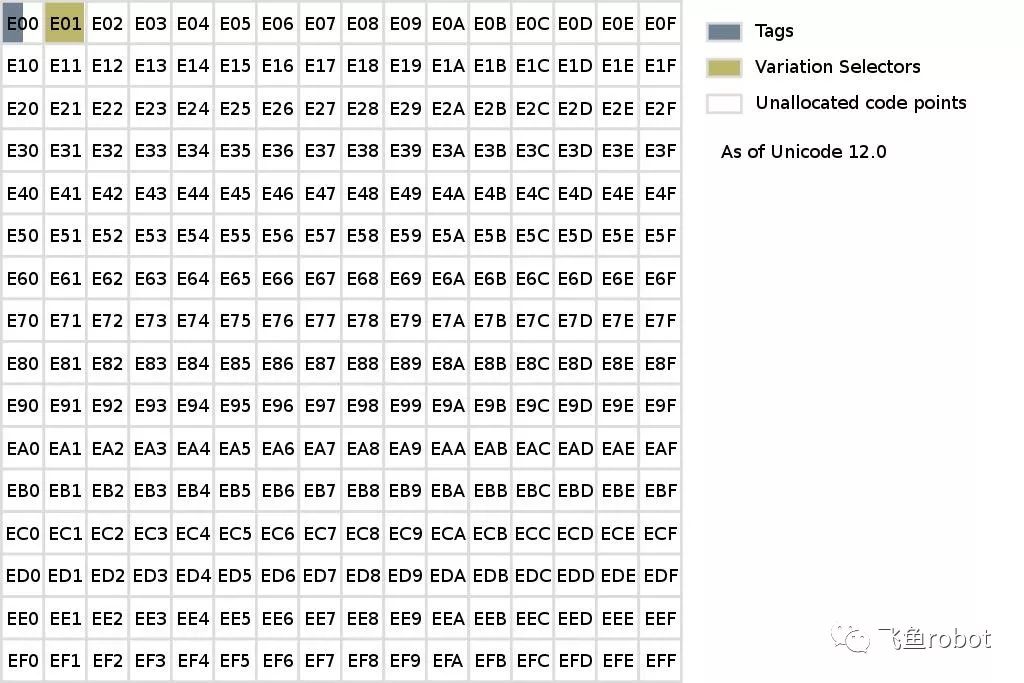
每个方格代表256个码点,0000到00FF共FF+1个码点,256个
Supplementary Special-purpose Plane
各种字符集和编码—UTF
utf代表unicode transformation format 的缩写,是对unicode 的编码,unicode固然好,但是不适合数据的存储和传递,之后就有3中比较流行的对unicode的编码
8 16 和32,具体这些特点的含义我们后面会详说UTF-8
变长编码方式,使用1-4个字节进行编码
非常流行,尤其在互联网领域
向上兼容性
回退和自动检查
前缀码机制
自同步
排序
UTF-16
变长编码,使用一个或两个16位码元,也就是2字节或4字节
是很多系统的内码,比如Windows、Java和JavaScript
互联网领域不是很流行
UTF-32
定长编码,4个字节
和Unicode中的码点一一对应,前端补零
比较浪费空间
使用场景有限
各种字符集和编码—UTF-8
BMP中的码点可能被编码成一个,两个或三个字节,辅助平面码点被编码成4个字节
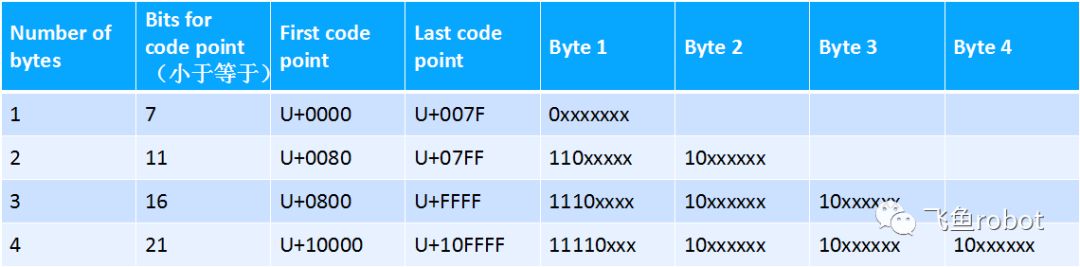
前128个字符只需要一个字节。接下来1920个字符需要2个字节,基本包含了剩下的所有拉丁字母,还有些希腊字母等等,剩下的BMP中的字符都会用3个字节表示,这里面就包括了大多数的中文,日文和韩文。其他平面的unicode码都用4个字节表示,包括少量的不常用的cjk数学符号和emoji等等。向上兼容性:兼容ascii码回退和自动检查:我们已知u8码向上兼容7位ascii码,但是在使用unicode之前有很多软件和数据都是用的8位扩展ascii码来表示欧洲字符的,u8能流行起来的一部分原因就是他对这种编码也有一定兼容性。那么它是如何做到的呢?一个u8处理器在错误的接收到扩展ascii码的输入后,当这个字节很明显不是合法的u8字节序列时,可以回退或者干脆把这个字节替换成正确的unicode码点。这是因为现实生活中的扩展ascii码文章里的字节序列基本都不是合法的u8字节序列,所以处理器能把它筛选出来。这又是为什么呢?因为我们知道,多字节u8字符序列是11开头那种,然后是10那种,一般11开头那种在扩展ascii码里都是重音元音字符,10开头的都是符号或者标点,一般正常的文章里很难见到这样的组合,即使真的有,让u8处理器误解,这也是少数情况,最坏情况也就是几个字符出错而已。前缀码:这个比较简单,意思就是编码后的字符的首个字节,因为这个字节会表示出这个字符被编码了多少个字节。这样的好处就是,一个字节流到来之后,处理器可以立即解码,而不用等待下一个字节的开头或者整个流的结尾标志。自同步:这是因为字符编码字节的开头和后续字节完全不一样,具体就是,单字节是0开头,多字节开头是11,多字节后续是10,这就使得我在任意一个字节,最多向前或者向后3个字节,就能找到这个字符的开头,这也是u8能在互联网领域流行的一个原因,错误的或者丢失的字节是不会被错误的解码的。排序:这个意思大概是说要将一堆u8字符串按照码点顺序排列,只需要排列对应的字节序列就行。
第三节 JAVA世界里的编码char类型原本用于表示单个字符,占用两个字节,表示为16进制时范围是\u0000到\ffff;如今一些Unicode字符可以用一个char表示,另外一些需要用两个char表示;
历史
1991年发布了Unicode 1.0,当时仅占用65536个代码值中不到一半的部分;
1996年Java问世,当时设计时决定采用16位的Unicode字符集,这样会比用8位字符集的程序设计语言有很大改进;
然而。。后来Unicode字符超过了65536个,增加了大量汉语、日语和韩语中的表意文字
方案
码点(code point):与编码表中的某个字符对应的代码值,例如U+0041就是拉丁字母A的码点;
代码单元(code unit):UTF-16中BMP的字符用16字节表示,成为码元,辅助字符采用一对码元进行编码,称为代理对;
代理对编码值落入BMP平面中空闲的2048字节内,巧妙的设计使得人们可以迅速知道一个码元是一个字符的编码,还是一个辅助字符的第一或第二部分;
在Java中,char类型描述了UTF-16编码中的一个代码单元;
所以强烈建议不要在程序中使用char类型,除非确实需要处理UTF-16代码单元
String类的length()

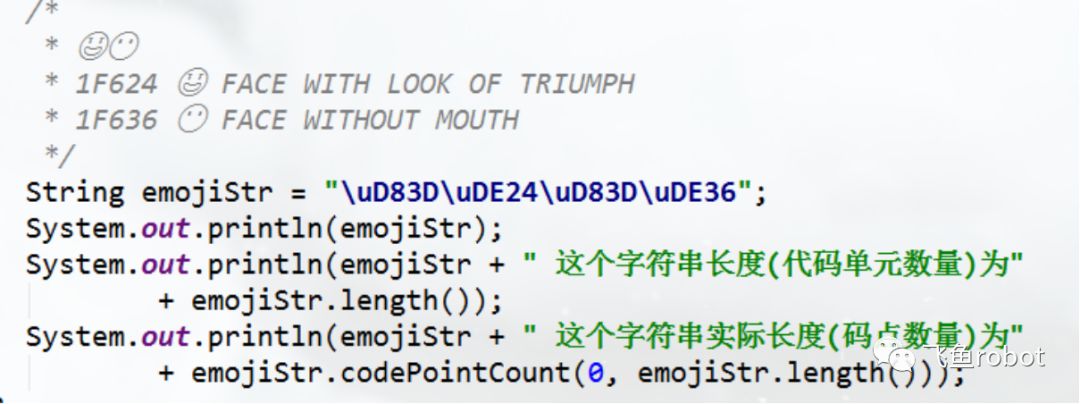

第四节 乱码乱码产生的根源有三种
编码引起的乱码
解码引起的乱码
缺少某种字体库引起的乱码
编码引起的乱码
这里在vscode中,键入思密达三个字,然后选择8859-1保存,我们知道,8859-1是单字节编码,然后我们重新用gb2312打开文件,大家猜猜会显示什么,结果是三个问号,这是为什么呢,我们用16进制文本编辑器打开这个文件,看看里面到底存的啥
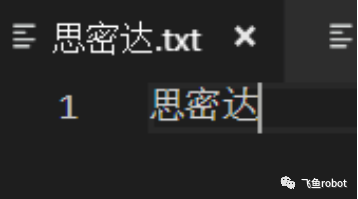
用ISO 8859-1保存思密达
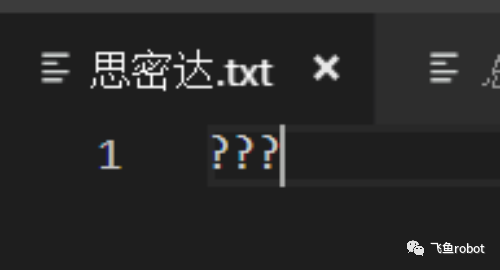
用GB2312打开的思密达
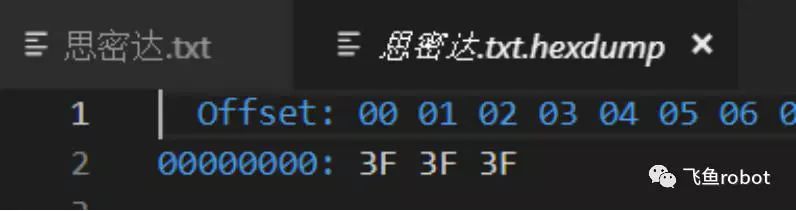
发现里面存了3组3f,这是因为用8859-1编码时,将不在字符集范围内的字符统一用 3F 表示,3F 对应的字符为问号“?”,这种情况下形成的乱码是不可逆的,也就是说无论用什么解码方式都不能正确显示字符,即使你换回8859-1也无济于事。
解码引起的乱码
写入思密达,然后用gb2312保存,然后用8859-1打开,大家猜猜会显示什么,会显示一堆西欧字母和数学符号,也就是乱码,我们再次用16进制编辑器看看发生了什么
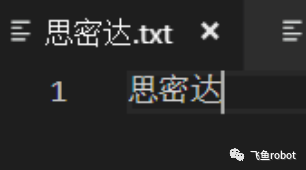
用GB2312保存的思密达
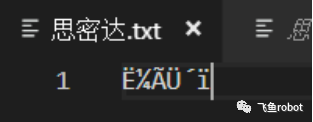
用ISO 8859-1打开的思密达
里面有6个字节,大家可能猜到了,这是gb2312编码,为了验证,我们查看一下gb2312的码表,看看这三个字的编码分别是什么。。
如何解决这种乱码,只需要编码和解码对应上即可
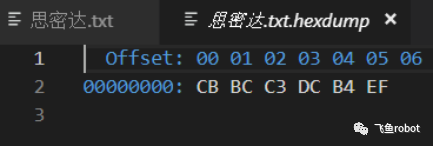
用16进制编辑器打开的思密达

思:CBBC

密:C3DC

达:B4EF
缺少某种字体库引起的乱码
最后还有这种,缺少某种字体库导致的乱码,这个就要说下电脑显示一个字的流程了。
二进制字节序列转换成对应字符集中的码点
然后码点通过查找字体库找到对应的字符
最后通过点阵的方式显示在屏幕上

不是乱码的“乱码”
最后,额外再讲两种不是乱码的乱码,说他是乱码,是因为看不懂,一种就是百分号编码。
比如我在百度里查我这个字,跳转的链接会是这样的,百分号后面跟着字母和数字。这种就是百分号编码,也就是url编码。
这里是两类URI的字符,分别是保留字符和非保留字符;保留字符是那些有时候会有特殊含义的字符。非保留字符就没这些含义。在需要使用url encoding时,保留字符会用一种特别的字符序列表示。
如何百分号编码这些保留字呢,很简单,在百分号后面跟上保留字符的ASCII码就行,这个ASCII码用16进制表示。这个时候这个百分号就是一个转义字符。对于那些非ascii码的字符,一般情况都是转成utf-8后,每个字节前面加上百分号就行。
百分号编码(Percent-encoding)又叫URL encoding

https://www.baidu.com/s?wd=%E6%88%91
保留字符:

非保留字符:

不过不是说url里的保留字一定要编码,这个也是分场景的,暂不介绍了。
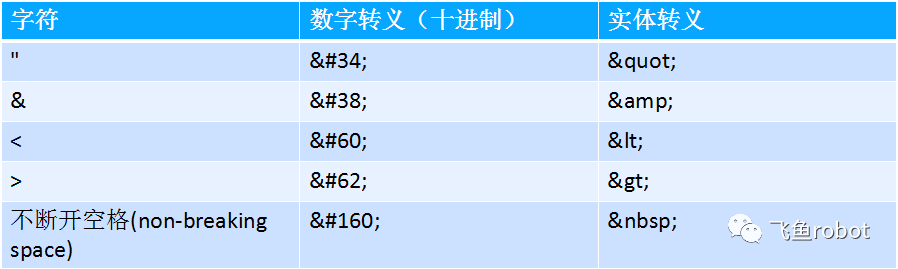
还有一种是html转义,有两种转义方法,一种是后面加数字,数字可以是10进制,也可以是16进制,16进制时候要有小x开头,这个数字就是unicode码点,还有一种实体转义,就是&后面加上实体名字,比如说下面这个表,同一个字符可以用数字转义,也可以用实体转义,name就是实体名,引号就是quot。
HTML转义
数字转义 nnnn; hhhh; nnnn和hhhh代表UCS/Unicode码点
实体转义 &name;
到这里,我们编码的故事就告一段落了。
以下是我们帅气的讲师吴晔晖,身强力壮人又帅,平时爱好技术和健身,有想认识的朋友速速联系我们小编啦

















 9756
9756











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









