







Scrapy框架、
为什么要学习scrapy?

理由:日常的Requests + Selenium虽然可以爬取网站内容,一旦遇到下载文件/图片,下载速度慢的鸡肋很快就暴露出来,有人说可以自己写高并发处理,再加上各种处理规则,如此一来,代码维护难度只增未减,另不排除遇到进程/线程堵塞,作为成熟的scrapy库,具备异步网络库、稳定性高、非堵塞。

框架图
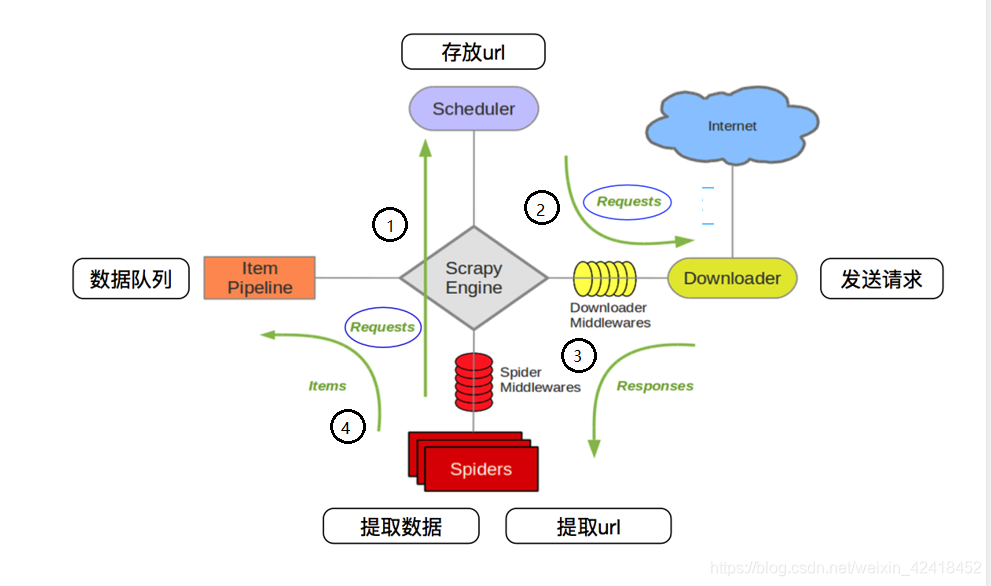
简单解析Scrapy框架流程
1.运行项目spiders执行到yield将request发送给engine,再到scheduler入队、排序处理
2.scheduler返回给engine、downloadermiddlewares交给downloader
3.downloader请求网络响应Responses,并经过engine、spidermiddlewares交给spiders
4.spiders提取数据并将items经engine发送给itempipline
.
组件介绍
Scrapy由5部分组成
Spiders:爬虫,定义了爬取的逻辑和网页内容的解析规则,主要负责解析响应并生成结果和新的请求
Engine:引擎,处理整个系统的数据流处理,框架的核心。
Scheduler:调度器,接受引擎发过来的请求,并将其加入队列中,在引擎再次请求时将请求提供给引擎
Downloader:下载器,下载网页内容,并将下载内容返回给spider
ItemPipeline:项目管道,负责处理spider从网页中抽取的数据,主要是负责清洗,验证和向数据库中存储数据
Downloader Middlewares:下载中间件,属于可自定义扩展,如代理(一般不写)
Spider Middlewares:spider中间件,可自定义request和responses过滤
网站分析
漫画首页:https://www.36mh.net/manhua/borenchuanhuoyingcishidai/
1、打开网站elements可以看到每个章节都存放在ul下
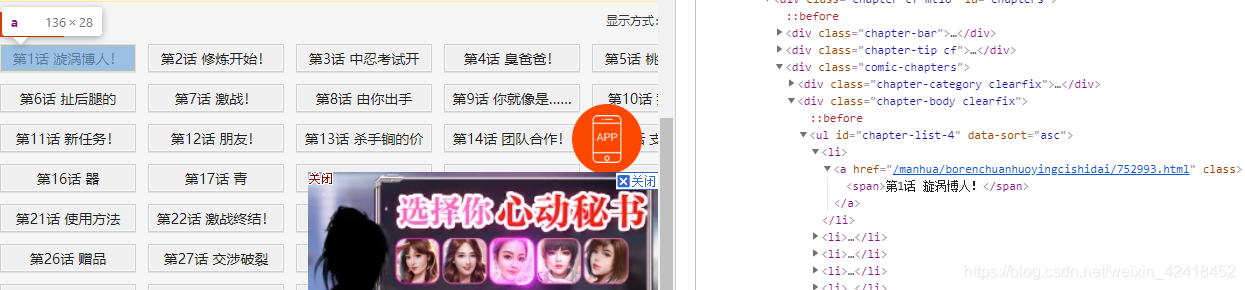
2、进入第1话,层层展开div,每一页只有一张图片,如果每次爬图片都要切换下一页,爬虫效率太低。可以看到图片src上面有一个nextPage函数,证明图片是经过js动态加载过的,图片动态加载无非两种方式:a.变量列表,b.图片名称编码加密(分析此方法需要对JavaScript有一定经验)
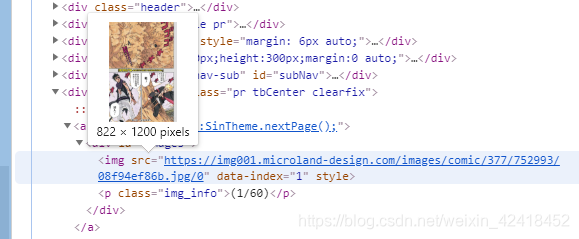
3、比较幸运的是该章节的所有图片名称都放在chapterImages列表里,在这里我们获取到另外两个重要信息,就是chapterpath(下载图片的图片),PageImage(含有下载图片的域名)。

分析完毕后,开始撸起代码。
创建/执行项目命令
创建项目:scrapy startproject borenzhuan
进入项目:cd borenzhuan #创建项目后会生成borenzhuan文件夹
创建爬虫:scrapy genspider borenzhuan(爬虫名) www.36mh.net (爬取域)
生成文件:scrapy crawl borenzhuan -o xxx.json (生成某种类型的文件)
运行爬虫:scrapy crawl borenzhuan #路径切换到spiders
列出所有爬虫:scrapy list
获得配置信息:scrapy settings [options]
目录结构
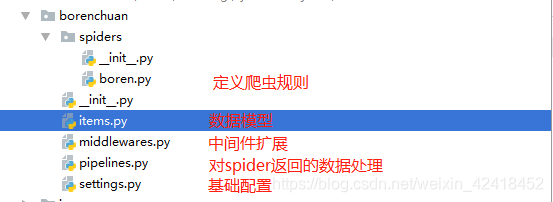
setting文件
ROBOTSTXT_OBEY = False #机器人协议,用来限定程序爬取范围,False不遵守协议
IMAGES_STORE=os.path.dirname(os.path.dirname(__file__)) #图片下载路径
#删除管道注释
ITEM_PIPELINES = 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









