








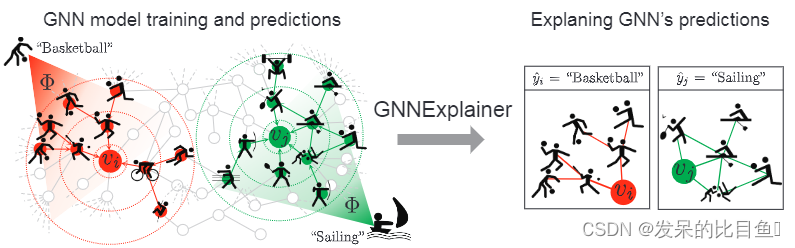
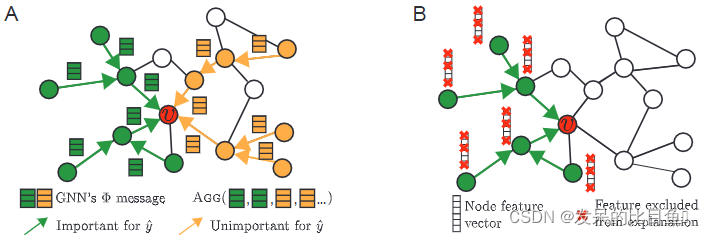
NIPS 2019 | gnexplainer:生成图神经网络的解释
图神经网络(gnn)是一个强大的工具,机器学习的图形。gnn通过递归地沿着输入图的边缘传递神经信息,将节点特征信息与图结构结合起来。然而,图结构和特征信息的结合导致了复杂的模型,并解释了由gnn所做的预测仍然没有解决。在这里,我们提出了GNNEXPLAINER,这是第一个通用的、模型不可知的方法,用于在任何基于图的机器学习任务中为任何基于gnn的模型的预测提供可解释的解释。给定一个实例,GNNEXPLAINER识别出一个紧凑的子图结构和一个在GNN预测中具有关键作用的节点特征子集。此外,gnexplainer可以为整个类的实例生成一致且简洁的解释。我们将gnexplainer定义为一种优化任务,可以最大化GNN的预测和可能子图结构的分布之间的相互信息。在合成图和真实图上的实验表明,我们的方法可以识别重要的图结构和节点特征,并且在解释准确率上比其他基线方法高出43.0%。GNNEXPLAINER提供了多种好处,从可视化语义相关结构到可解释性,再到洞察错误gnn的错误。
Introduction
设计和合成具有理想性质的新分子是药物发现和化学科学的一项具有挑战性的任务。所有化学分子的搜索空间估计在1033个左右,因此无法进行彻底搜索。近年来,机器学习方法的进步大大加快了这一领域的进展。许多研究将分子表示为二维分子图,并提出利用深度生成模型(如变分自编码器)自动生成分子图和优化分子性质。为了解决这一挑战,图神经网络(GNNs)已经成为图上机器学习的最先进技术,因为它们具有递归地合并图中邻近节点的信息的能力,自然地捕获图结构和节点特征。
尽管它们有优势,但gnn缺乏透明度,因为它们不容易让人类理解它们的预测。然而,理解GNN的预测的能力是重要和有用的,原因如下:(i)可以增加GNN模型的信任度 。(ii)在越来越多的涉及公平、隐私和其他安全挑战的关键决策应用中,它提高了模型的透明度。(iii)它允许实践者了解网络特征,识别并纠正模型在现实世界中所犯错误的系统模式。
虽然目前还没有解释gnn的方法,但最近解释其他类型神经网络的方法主要采取了两种途径之一。其中一行工作是用更简单的代理模型在局部近似模型,然后对这些模型进行探测以进行解释。其他方法仔细检查相关特征的模型,找到高层次特征的良好定性解释,或确定有影响的输入实例。然而,这些方法在合并关系信息(图的本质)方面能力不足。由于这方面对于图上机器学习的成功至关重要,所以任何对GNN预测的解释都应该利用图提供的丰富关系信息和节点特性。


















 94
94

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











