






YOLO系列算法综述(1)——YOLO V1算法

Abstract(摘要)
我们设计了一种新的目标检测算法,并将其命名为YOLO。在之前的研究当中,分类器被赋予了新的用途——使用它来完成检测任务。取而代之的是,我们将目标检测任务定义为一个回归任务,继而对空间分离的边界框和相关的类别概率进行预测。在一次评估过程中,基于单一的神经网络对目标的边界框和类别概率进行预测。由于整个的目标检测过程都是基于一个神经网络完成的,因此它可以直接对检测性能实现端对端的优化。
框架的统一性使得系统的检测速度非常快,我们的基础YOLO模型的实时图像处理速度能到达每秒45帧。另一个使用了较小网络的版本,实时图像处理速度能达到每秒155帧,并且能达到其他检测器的两倍平均准确度。相比于其他先进的检测系统,YOLO更容易犯一些局部性的错误,但它检测得到假正例的概率更低。最后,YOLO算法学习目标泛化特征的能力更强,不论是自然图像还是诸如艺术风格的图像,YOLO算法的表现都要优于DPM、R-CNN等算法。
1 Introduction(简介)
对于一张图像,人类只需要瞥一眼就能知道图像里有哪些东西、它们的具体位置以及它们在干嘛。人类拥有快速、精准的视觉系统,这使得我们稍加思索就能处理复杂的任务。快速、精准的目标检测算法将使得计算机不需要特殊的传感器就能驾驶汽车,让残疾人辅助设备能为人类使用者实时传递场景信息,并将为通用交互式机器人系统的实现提供巨大推力。
当前的目标检测系统使用分类器来完成检测任务,为了检测一个目标,这些系统使用一个分类器在测试图像的不同区域进行评估,以此来探测该目标,例如DPM模型使用滑动窗口在整张图像上进行均匀间隔滑动来搜索目标。

图1 YOLO系统结构
更多的方法例如R-CNN使用RPN(Region Proposal Network)网络先在图像中生成候选区域,然后在这些候选区域上训练分类器。在分类完成之后,之后的处理用来精细化边界框,消除重复检测,并基于场景中的其他对象重新定位框。因为每一个步骤都需要单独训练,这导致操作流程非常复杂并且难以进行优化。
我们将目标检测任务重新定义为一个单一的回归问题,直接从图像像素中获取边界框坐标和类别概率。使用这套系统,对于一张图像你只需要处理一次就能获取图像中的目标和对应位置。
YOLO出人意料的简单,一个单一的卷积神经网络同时对多种的边界框和对应的类别概率进行预测。YOLO使用完整图像进行训练,直接对检测性能进行优化。这种统一的模型相比于传统模型有多个方面的优势。
第一,YOLO算法非常的快速。由于我们将目标检测任务重新定义为回归预测问题,这使得我们不需要复杂的处理流程。在测试时,我们只需要在新图像上运行我们的神经网络就可以了。我们的基础网络在没有批处理的情况下能在Titan X GPU上达到45帧每秒的速度,另一个更快的版本能超过150帧每秒。这意味着我们可以在不到25毫秒的延迟时间内实时处理流媒体视频。此外,YOLO能达到超过其它实时检测系统两倍的平均准确率。
第二,YOLO与使用滑动窗口及RPN的系统不同,YOLO算法在训练和测试的过程中直接观察整张图像,因此它可以隐式地包含类别及性能的背景信息。Fast R-CNN是一个很好的检测算法,但由于其观察视野较小,因此会产生对目标背景信息的错误理解。与Fast R-CNN相比,YOLO算法在背景信息的错误率少于Fast R-CNN的一半。
第三,YOLO算法能够学得目标的泛化特征。当使用自然图像进行训练,并在艺术图像上进行的测试的时候,YOLO在很大程度上超过了像DPM和R-CNN这样的顶级检测算法。由于YOLO是高度泛化的,所以当应用到新的领域或遇到意外的输入时,它崩溃的可能性更小。
YOLO算法在精度上依然落后于最先进的检测系统,虽然它能够对图像进行快速的检测,但它很难精确定位一些目标,特别是小目标。
我们所有的实验和测试代码都是开源,并且我们提供了大量的预训练模型可供下载使用。
2 Unified Detection(统一检测)
我们将目标检测的各个过程整合到了一个神经网络当中,网络使用来自整张图像的特征来预测目标的边界框。它也同时对图像中所有目标类别的边界框进行预测,这意味着我们可以对整张图像以及图像中的目标进行全局分析。YOLO的设计保证了在保持高精确度的同时能够实现端对端的训练和快速的实时检测速度。
系统首先将图像分为(S, S)的网格单元,如果一个目标的中心落入了这个单元之中,那么该单元就负责检测这个目标。
每一个网格单元会对目标的边界框和这些边界框的置信度进行预测,这些置信度反映了这个边界框中是否含有该目标以及对其预测准确性的判断。我们将置信度定义为:
P
r
(
O
b
j
e
c
t
)
∗
I
O
U
p
r
e
d
t
r
u
t
h
Pr(Object) * {\bf IOU}_{pred}^{truth}
Pr(Object)∗IOUpredtruth
如果在方格中没有目标的话,那么这个置信度应该为0,否则,我们希望这个置信度分数应当与IOU相等。
每一个边界框都包含了5个预测值:(x,y,w,h)以及置信度。(x,y)表示了边界框中心与网格单元边界的相对距离,而(w,h)是相对于整幅图像进行预测的。而置信度则表示了预测得到的边界框与任意真实区域边界框的IOU(交并补)。
每一个网格单元还要预测C个条件类别概率,即:
P
r
(
C
l
a
s
s
i
∣
O
b
j
e
c
t
)
Pr(Class_i|Object)
Pr(Classi∣Object)
而这些概率以网格单元包含目标作为条件。我们在一个网格单元上只预测一组类别概率,而不管边界框的个数B有多少。在进行检测时,我们将条件类别概率与单个边界框的置信度相乘:
P
r
(
C
l
a
s
s
i
∣
O
b
j
e
c
t
)
∗
P
r
(
O
b
j
e
c
t
)
∗
I
O
U
p
r
e
d
t
r
u
t
h
=
P
r
(
C
l
a
s
s
i
)
∗
I
O
U
p
r
e
d
t
r
u
t
h
(
1
)
Pr(Class_i|Object) * Pr(Object)* {\bf IOU}_{pred}^{truth} = Pr(Class_i) * {\bf IOU}_{pred}^{truth} (1)
Pr(Classi∣Object)∗Pr(Object)∗IOUpredtruth=Pr(Classi)∗IOUpredtruth(1)
然后我们就得到了每一个边界框特定类别的置信度分数,这些分数同时包含了某一类别出现在边界框中的概率以及边界框拟合目标的精确度。
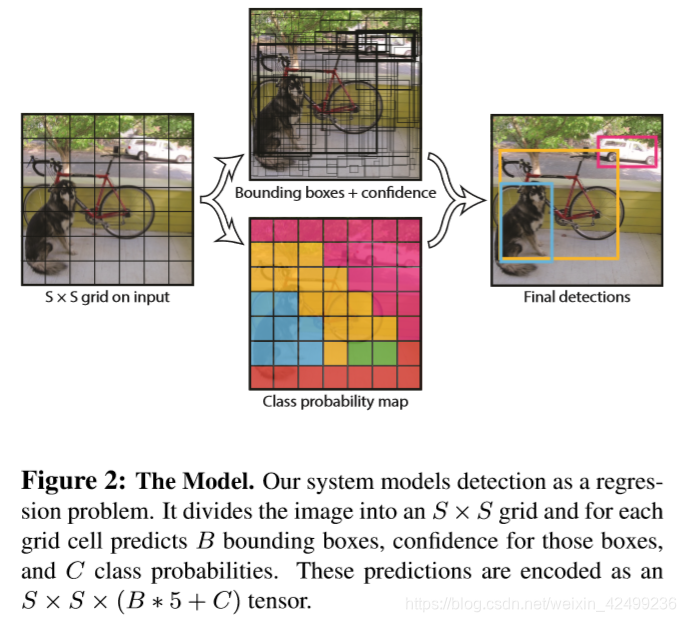
为了在Pascal VOC上进行评估,我们令S=7,B=2,Pascal VOC有20种类别,所以C=20,最终得到的预测结果是一个7x7x30的张量。
图2 YOLO模型
2.1 Network Design(网络设计)
我们使用卷积神经网络来实现这个模型并在Pascal VOC数据集上进行评估。网络的卷积层从图像中提取特征,然后全连接层预测类别概率和边界框坐标。我们的网络结构受到了GoogLeNet的启发,他拥有24的卷积层以及2个卷积层,但我们没有使用GoogLeNet中的Inception模块,而是用1x1的残差层与3x3的卷积层相结合,网络结构如下图所示:

图3 网络结构
我们还训练了一个快速版本的YOLO,旨在推进快速目标检测的边界。Fast YOLO使用了更小的卷积网络,只包含9层卷积网络和更少的卷积核。除了网络规模外,YOLO和Fast YOLO的所有训练和测试参数都相同。网络的最终输出是一个7x7x30的张量。2.2 Training(训 练)
我们使用ImageNet-1000数据集对卷积层进行了预训练。在预训练中,我们使用了图3中网络的前20层,并在其后追加了平均池化层和全连接层。在接近一个周的训练之后,与Caffe的模型仓库里的GoogLeNet相比,模型在ImageNet-2012验证集上基于单一裁剪验证达到的Top-5准确度为88%。
然后我们就将模型应用到检测任务中。Ren等人发现在预训练网络中同时添加卷积和全连接层能够改善模型性能。根据他们的先例,我们向网络中添加了随机初始化权重的4个卷积层和2个全连接层。由于检测需要精确的视觉信息,于是我们将输入分辨率从224x224调整为了448x448.
网络的最后一层同时对边界框和类别概率进行预测。我们通过原始图像的宽高来对边界框的(w,h)进行标准化,使其其落入0到1之间。
网络的最后一层使用线性激活函数,而其他层使用下面的渗漏整流线性函数作为激活函数:
ϕ
(
x
)
=
{
x
,
x
>
0
0.1
x
,
o
t
h
e
r
w
i
s
e
\phi(x)=\begin{cases} x, & x>0\\ 0.1x, & otherwise\\ \end{cases}
ϕ(x)={x,0.1x,x>0otherwise
我们对模型输出中的平方和误差进行了优化,使用平方和误差的原因是因为它易于优化,然而它并没有很好地满足我们最大化平均准确率的目标。因为它会用分类误差对局部化误进行加权,这并非我们想要的。并且,在每张图像中许多的网格单元不会包含任何目标,这使得这些网格单元的置信度分数近乎为0,经常会破坏来自包含目标的单元格的梯度。这可能导致模型不稳定,导致训练在早期出现分歧。
为了解决这一问题,我们增加了损失函数中边界框坐标预测误差的占比,减少了不包含目标的边界框置信度分数预测误差的占比。我们使用两个参数来表示这个比重:
λ
c
o
o
r
d
=
0.5
,
λ
n
o
o
b
j
=
0.5
\lambda_{coord} = 0.5, \lambda_{noobj}=0.5
λcoord=0.5,λnoobj=0.5
平方和误差对大边界框和小边界框的误差都进行加权,我们的误差度量应该反映出大边界框中的小偏差比小边界框中的小偏差重要。为了达到这个目的我们预测了边界框宽度和高度的平方根,而不是直接预测宽度和高度。
YOLO在每个网格单元中会预测多种边界框,而在训练时我们只需要一个边界框来负责一个目标,于是我们选定一个具有最高IOU的预测器来负责预测这个目标。这种做法也导致了不同边界框预测器的专门化,每个预测器在预测特定大小、长宽比或对象类别方面都会变得更好,从而提高整体召回率。
在训练中,我们对下列含有多个部分的损失函数进行了优化:

其中
1
i
o
b
j
1_i^{obj}
1iobj表示第i个网格单元是否出现了目标,而
1
i
j
o
b
j
1_{ij}^{obj}
1ijobj表示在网格单元i中的第j个边界框预测器负责这个预测。
请注意,如果网格单元中存在对象,则损失函数只会惩罚分类错误。如果预测器对真实区域边界框“负责”,它也只会惩罚边界框坐标误差。
我们在来自Pascal VOC 2007和2017的训练数据和验证数据上训练了135个世代,在训练过程中的批处理数为64,动量为0.9,衰减为0.0005。
2.3 Inference(推论)
就像训练和验证一样,进行检测时也只需要一个网络进行评估。在Pascal VOC数据集上,网络会对每一个框预测98个边界框和类别概率。和基于分类器的方法不同,由于YOLO只使用单一网络进行评估,所以YOLO在检测时非常快。
网格设计加强了边界框预测中的空间多样性。通常情况下,很清楚对象属于哪个网格单元,网络只为每个对象预测一个框。但是,一些大型物体或附近的物体多个网格单元的边界可以通过多个网格单元很好地定位。非极大值抑制可用于确定这些多重检测,当对性能要求不太高时,如R-CNN或DPM,非极大值抑制增加2~3%的平均准确率。
2.4 Limitations of YOLO(YOLO的限制)
YOLO对边界框预测施加了强大的空间约束,因为每个网格单元只能预测两个顶点,并且只能有一个类。这个空间约束限制了模型可以预测的附近对象的数量,使得我们的模型对成群出现的小物体检测效果较差,例如鸟群。
由于我们的模型学会了根据数据预测边界框,因此它很难泛化为具有新的或特殊的纵横比、配置的对象。我们的模型还使用相对粗糙的特性来预测边界框,因为我们的架构具有输入图像中的多个向下采样层。
最后,当我们训练一个逼近检测性能的损失函数时,损失函数对小边界框和大边界框中的错误同等对待。一般来说,大框里的小错误影响较小而小框中的小误差对IOU的影响更大。我们的主要错误源是定位错误。
再往后就是一些和其他检测算法性能上的比较之类杂七杂八的,没太大意义,在此就不赘述了,有兴趣的同学可以自己看一看,大概的效果如下:

3 总 结
在这一节中我们对YOLO V1的算法原理进行了翻译,有任何的问题可以在评论区留言,我会尽快回复,谢谢支持!














 737
737











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









