






简单说明
多维度的分组统计函数包括:ROLLUP和CUBE,用在普通的分组SQL的group by子句中:
GROUP BY (a,b,c):
先根据a分组,然后根据b分组,最后根据c分组,分组维度是(a,b,c)
GROUP BY ROLLUP (a,b,c):
分组维度1:(a,b,c)
分组维度2:(a,b)
分组维度3:(a)
分组维度4:最后将全表作为一个组
GROUP BY CUBE (a,b,c):
分组维度1:(a,b,c)
分组维度2:(a,b)
分组维度3:(a,c)
分组维度4:(a)
分组维度5:(b,c)
分组维度6:(b)
分组维度7:(c)
分组维度8:最后将全表作为一个组
ROLLUP和CUBE关系有点类似于排列和组合之间的关系
ROLLUP相当于排列,分组维度有顺序要求
CUBE相当于组合,分组维度没有顺序要求
测试数据准备
CREATE TABLE studentscore
( student_name varchar2(20),
subjects varchar2(20),
score number);
INSERT INTO studentscore VALUES('WBQ','ENGLISH',90);
INSERT INTO studentscore VALUES('WBQ','MATHS',95);
INSERT INTO studentscore VALUES('WBQ','CHINESE',88);
INSERT INTO studentscore VALUES('CZH','ENGLISH',80);
INSERT INTO studentscore VALUES('CZH','MATHS',90);
INSERT INTO studentscore VALUES('CZH','HISTORY',92);
INSERT INTO studentscore VALUES('CB','POLITICS',70);
INSERT INTO studentscore VALUES('CB','HISTORY',75);
INSERT INTO studentscore VALUES('LDH','POLITICS',80);
INSERT INTO studentscore VALUES('LDH','CHINESE',90);
INSERT INTO studentscore VALUES('LDH','HISTORY',95);
commit;
-- 一张简单的成绩表,包括 学生姓名、科目和成绩
需求一
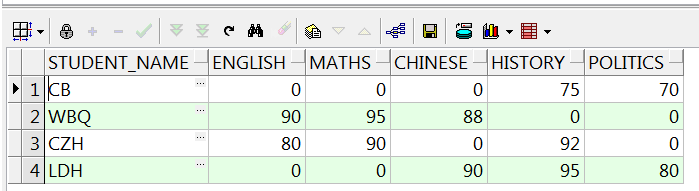
列转行展示数据,展示某个学生的所有科目成绩,一个较为普通的需求:
select s.student_name,
max(decode(s.subjects, 'ENGLISH', s.score, 0)) ENGLISH,
max(decode(s.subjects, 'MATHS', s.score, 0)) MATHS,
max(decode(s.subjects, 'CHINESE', s.score, 0)) CHINESE,
max(decode(s.subjects, 'HISTORY', s.score, 0)) HISTORY,
max(decode(s.subjects, 'POLITICS', s.score, 0)) POLITICS
from studentscore s
group by s.student_name;
-- 使用decode做列转行,即case行列转换相关的需求
需求二
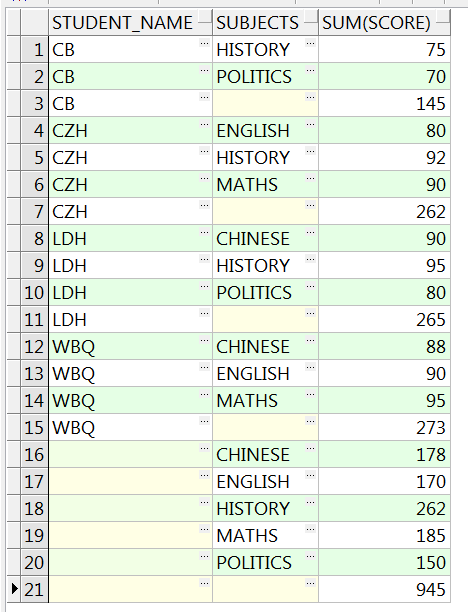
使用CUBE多维度分组分析,分别根据学生、科目、学生和科目、整个表四个维度分析:
SELECT student_name, subjects, sum(score)
FROM studentscore
GROUP BY CUBE(student_name, subjects)
order by student_name, subjects nulls last;
-- 分组维度为:
-- (student_name,subjects)
-- (student_name)
-- (subjects)
-- 全表
SELECT student_name, subjects, SUM(score)
FROM studentscore
GROUP BY student_name, subjects
UNION
SELECT student_name, NULL, SUM(score)
FROM studentscore
GROUP BY student_name
UNION
SELECT NULL, subjects, SUM(score)
FROM studentscore
GROUP BY subjects
UNION
SELECT NULL, NULL, SUM(score) FROM studentscore;
--CUBE等价SQL
需求三
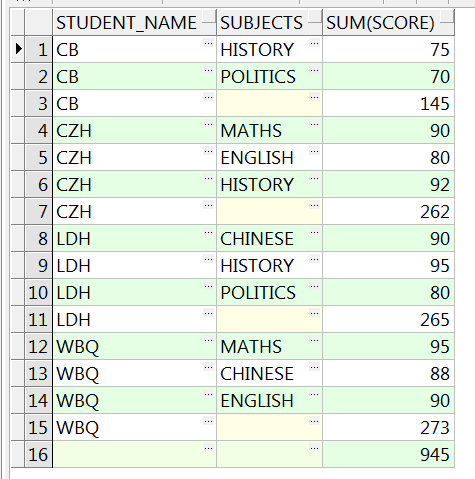
使用ROLLUP多维度分组分析,分别根据学生和科目、学生、整个表三个维度分析:
SELECT student_name, subjects, sum(score)
FROM studentscore
GROUP BY ROLLUP(student_name, subjects);
SELECT student_name, subjects, SUM(score)
FROM studentscore
GROUP BY student_name, subjects
UNION
SELECT student_name, NULL, SUM(score)
FROM studentscore
GROUP BY student_name
UNION
SELECT NULL, NULL, SUM(score) FROM studentscore;
--ROLLUP等价SQL
需求四
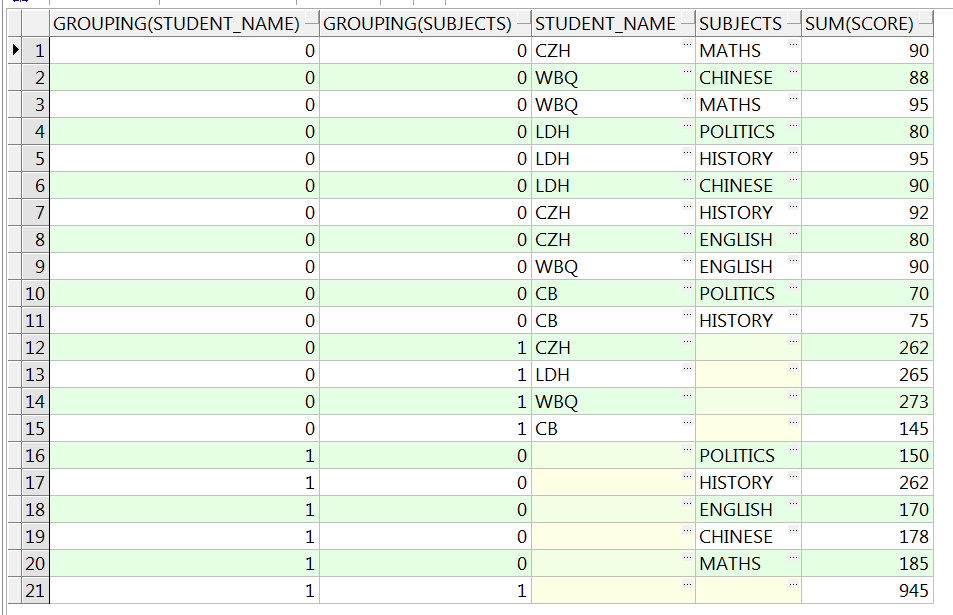
使用函数grouping和grouping_id继续对上方的查询进行优化展示,
grouping 可以对列是否是分析生成的进行判断,分析生成的则为1,反之为0,
grouping_id 可以标识出不同的分组规则,生成一个从0开始的数列,
以上两个函数出现在select子句中,且以上两个函数只能修饰被分组的列。
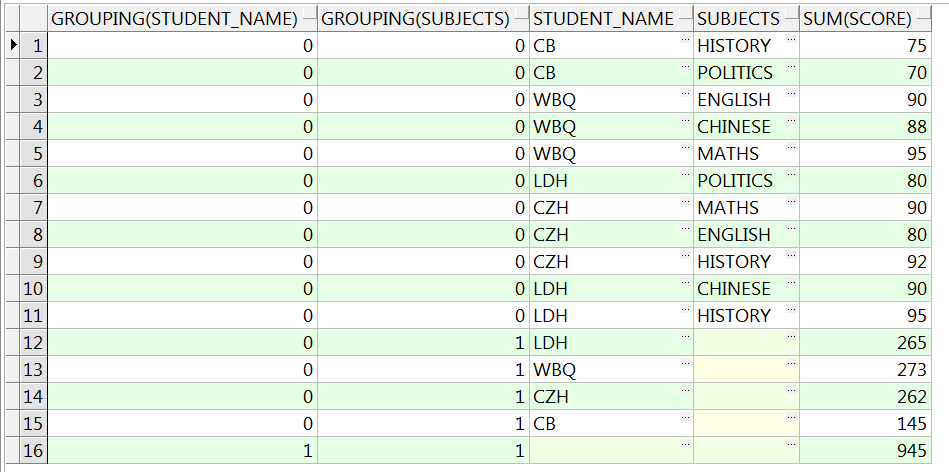
SELECT grouping(student_name),
grouping(subjects),
student_name,
subjects,
sum(score)
FROM studentscore
GROUP BY CUBE(student_name, subjects)
ORDER BY 1, 2;
SELECT grouping(student_name),
grouping(subjects),
student_name,
subjects,
sum(score)
FROM studentscore
GROUP BY ROLLUP(student_name, subjects)
ORDER BY 1, 2;
-- 使用函数grouping,看出规律,空列一般是分析维度造成的,函数返回值是1
SELECT grouping_id(student_name, subjects),
student_name, subjects, sum(score)
FROM studentscore
GROUP BY CUBE(student_name, subjects)
ORDER BY 1;
SELECT grouping_id(student_name, subjects),
student_name, subjects, sum(score)
FROM studentscore
GROUP BY ROLLUP(student_name, subjects)
ORDER BY 1;
-- 使用函数grouping_id对分组维度进行标识,生成一个从0开始的数列来标识不同的分组维度
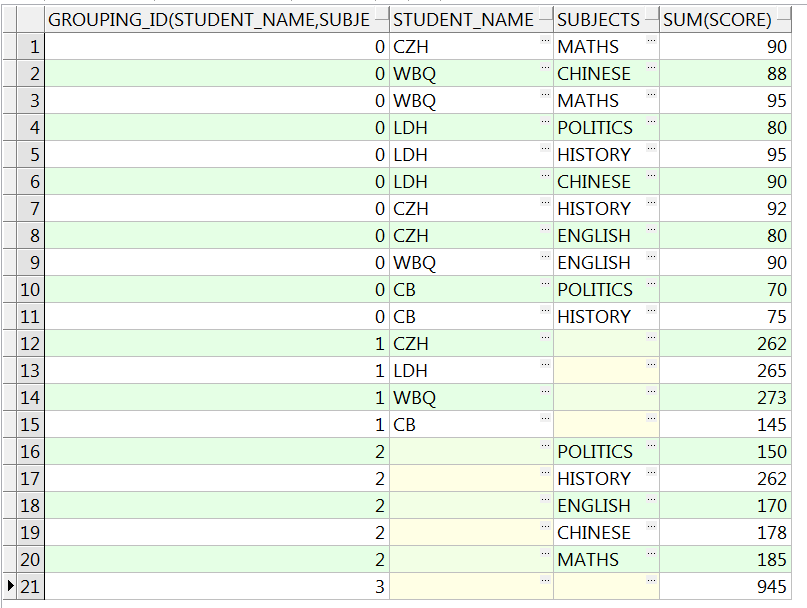
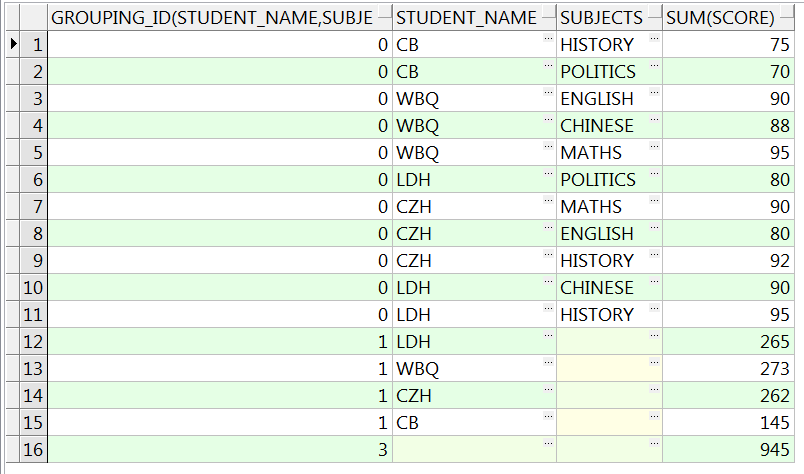
从grouping_id的结果可以分析猜测,ROLLUP实际上是对CUBE分组维度过滤之后生成的。
需求五
使用上方的两个函数,借助其他函数,进一步做规范化展示:
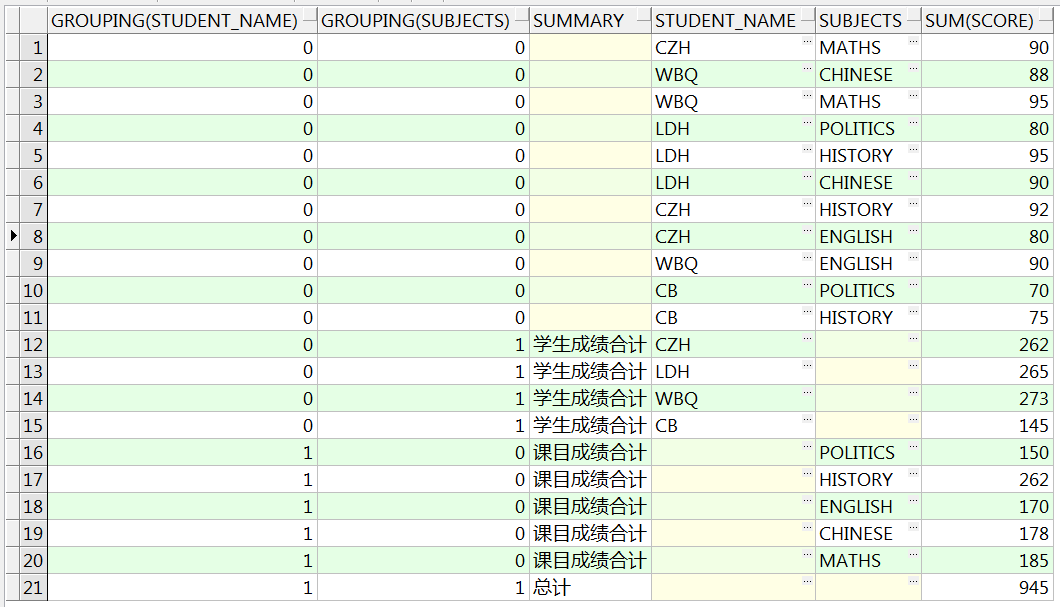
SELECT grouping(student_name), grouping(subjects),
decode(grouping(student_name) || grouping(subjects),
'01', '学生成绩合计',
'10', '课目成绩合计',
'11', '总计',
null) SUMMARY,
student_name,
subjects,
sum(score)
FROM studentscore
GROUP BY CUBE(student_name, subjects)
ORDER BY 1, 2;
-- 使用decode对列进行判断,添加对应的描述信息
SELECT grouping(student_name), grouping(subjects),
CASE
WHEN grouping(student_name) = 0 AND grouping(subjects) = 1 THEN
'学生成绩合计'
WHEN grouping(student_name) = 1 AND grouping(subjects) = 0 THEN
'课目成绩合计'
WHEN grouping(student_name) = 1 AND grouping(subjects) = 1 THEN
'总计'
ELSE null
END SUMMARY,
student_name, subjects, sum(score)
FROM studentscore
GROUP BY CUBE(student_name, subjects)
ORDER BY 1, 2;
-- 使用CASE的写法
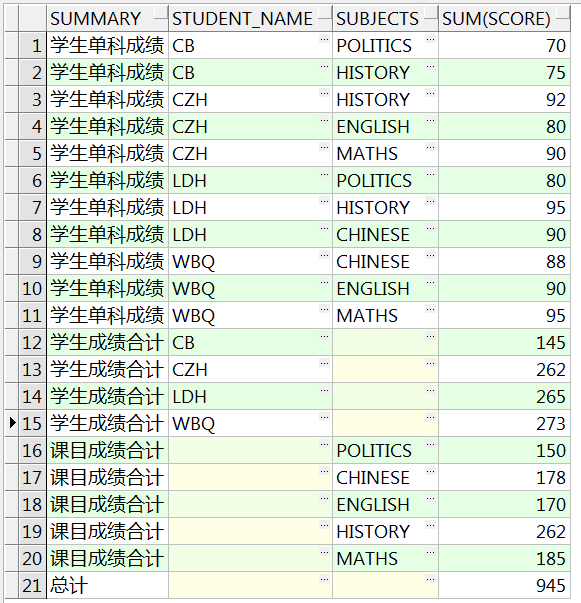
SELECT decode(grouping(student_name),
0, decode(grouping(subjects), 1, '学生成绩合计', '学生单科成绩'),
1, decode(grouping(subjects), 0, '课目成绩合计', '总计')) SUMMARY,
student_name, subjects, sum(score)
FROM studentscore
GROUP BY CUBE(student_name, subjects)
ORDER BY grouping_id(student_name, subjects), 2;
-- 使用decode嵌套对case多条件的改写
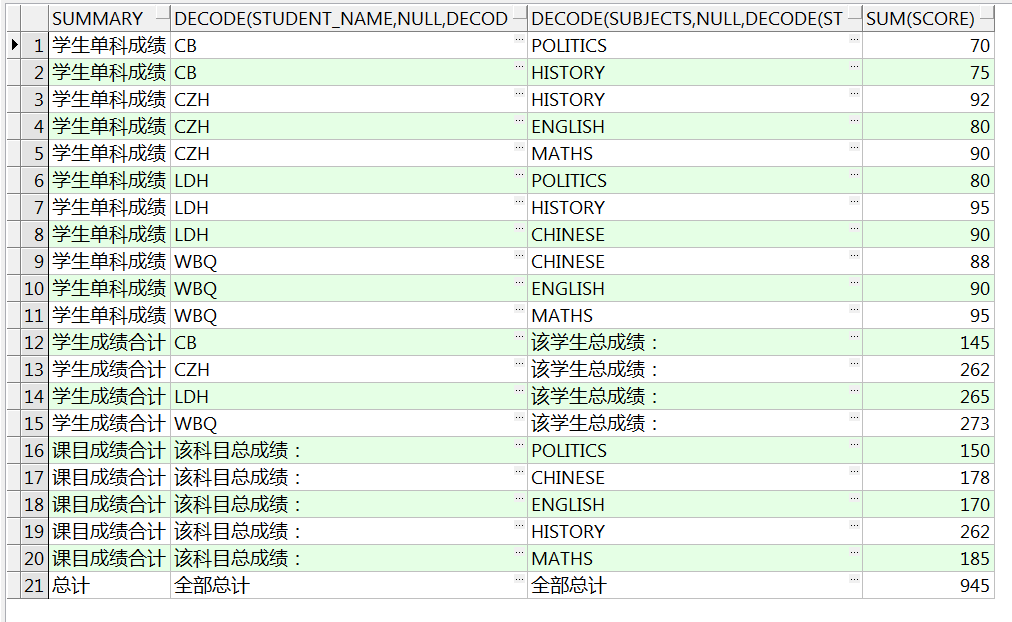
SELECT decode(grouping(student_name),
0, decode(grouping(subjects), 1, '学生成绩合计', '学生单科成绩'),
1, decode(grouping(subjects), 0, '课目成绩合计', '总计')) SUMMARY,
decode(student_name,null,decode(subjects,null,'全部总计','该科目总成绩:'),student_name),
decode(subjects,null,decode(student_name,null,'全部总计','该学生总成绩:'),subjects),
sum(score)
FROM studentscore
GROUP BY CUBE(student_name, subjects)
ORDER BY grouping_id(student_name, subjects), 2;
-- 既然用了decode嵌套,那么送佛送到西
[TOC]















 3818
3818











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









