






1、首先导入solrj需要的的架包
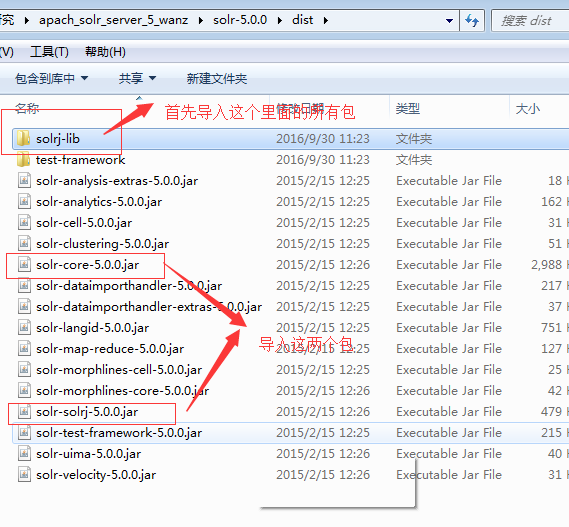
2、需要注意的是低版本是solr是使用SolrServer进行URL实例的,5.0之后已经使用SolrClient替代这个类了,在添加之后首先我们需要根据schema.xml配置一下我们的分词器

这里的msg_all还需要在schema.xml中配置
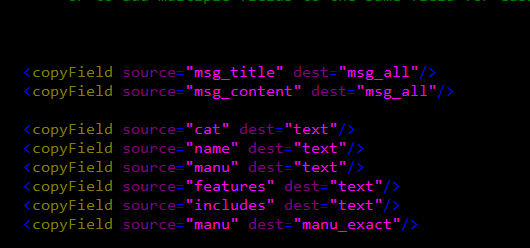
它的主要作用是将msg_title,msg_content两个域的值拷贝到msg_all域中,我们在搜索的时候可以只搜索这个msg_all域就可以了,
solr默认搜索需要带上域,比如
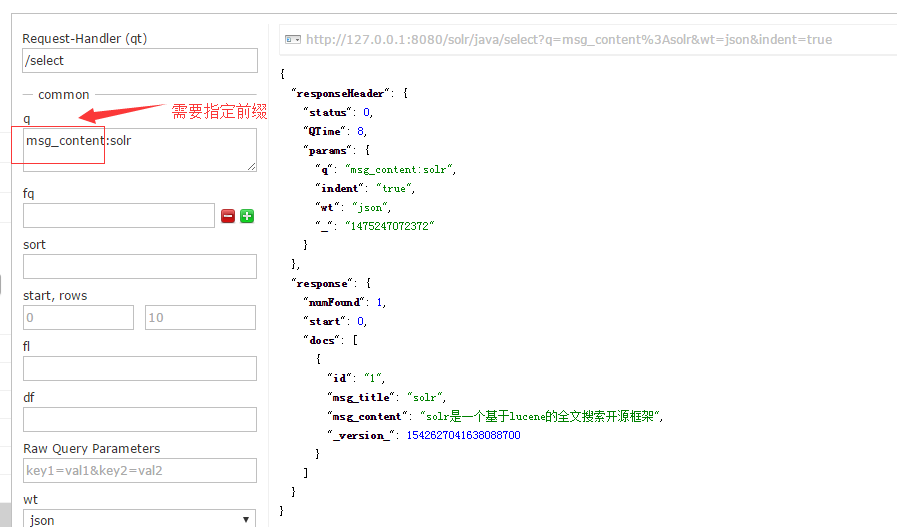
solr更改默认搜索域的地方也在schema.xml,它默认是搜索text域的,但是5.0之后不在这里配置默认搜索域了,它的文档也告诉我们,在solrconfig.xml中配置

在solrconfig.xml中配置默认搜素域,这样我们就可以按照我们自己的域进行搜索了

配置好以上,就可以使用代码进行CURD
删除所有分词
增加分词
基于Bean增加分词
查询结果
将查询结果集封装为对象Bean
将结果集高亮显示
ok,solr的基本使用就完成了















 1324
1324

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









