







Hadoop简介:
Hadoop官网:http://hadoop.apache.org/
Hadoop是Apache软件基金会旗下的一个开源分布式计算平台,为用户提供了系统底层细节透明的分布式基础架构
Hadoop 底层用Java语言、跨平台性,可以部署在廉价的计算机集群中。
Hadoop在分布式环境下提供了海量数据的处理能力
几乎所有主流厂商都围绕Hadoop提供开发工具、开源软件、商业化工具和技术服务,如谷歌、雅虎、微软、思科、淘宝等,都支持Hadoop。
Hadoop核心:
Hadoop组成:
- 分布式文件系统 HDFS(Hadoop Distributed File System) | 存储系统
- 分布式计算 MapReduce | 并行运算框架
Hadoop的特性:
Hadoop是一个能够对大量数据进行分布式处理的软件框架,并且是以一种可靠、高效、可伸缩的方式进行处理的,它具有以下几个方面的特性:
- 高可靠性
- 高效性
- 高可扩展性
- 高容错性
- 成本低
- 运行在Linux平台上
- 持多种编程语言
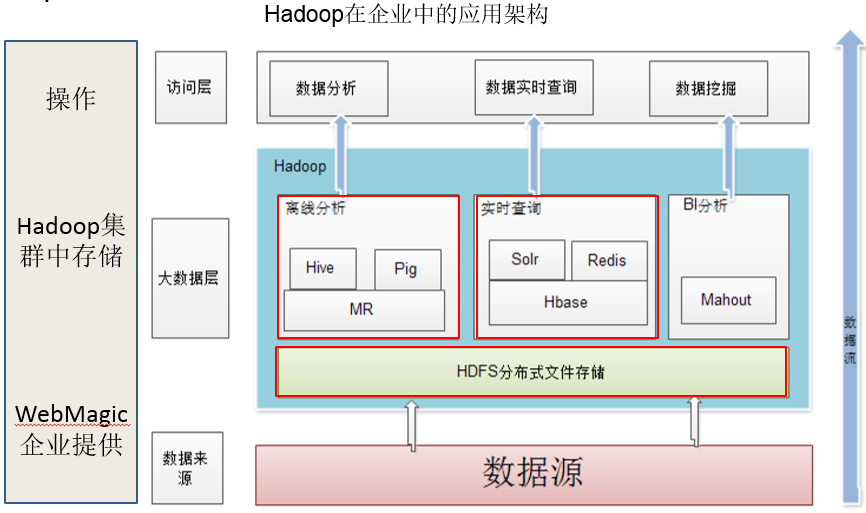
Hadoop 生态系统架构
Hadoop的项目结构不断丰富发展,已经形成一个丰富的Hadoop生态系统。
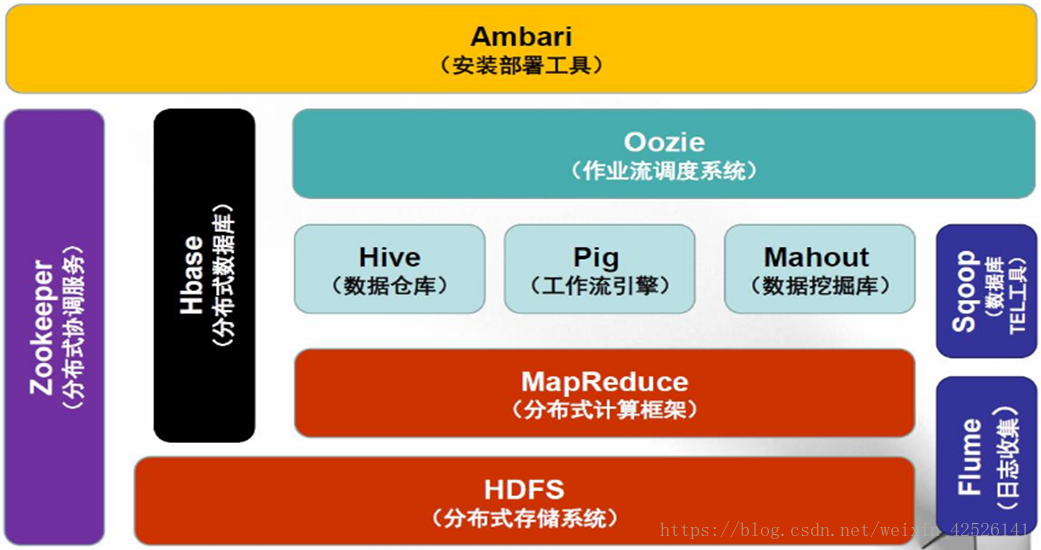
Hadoop1 生态系统架构
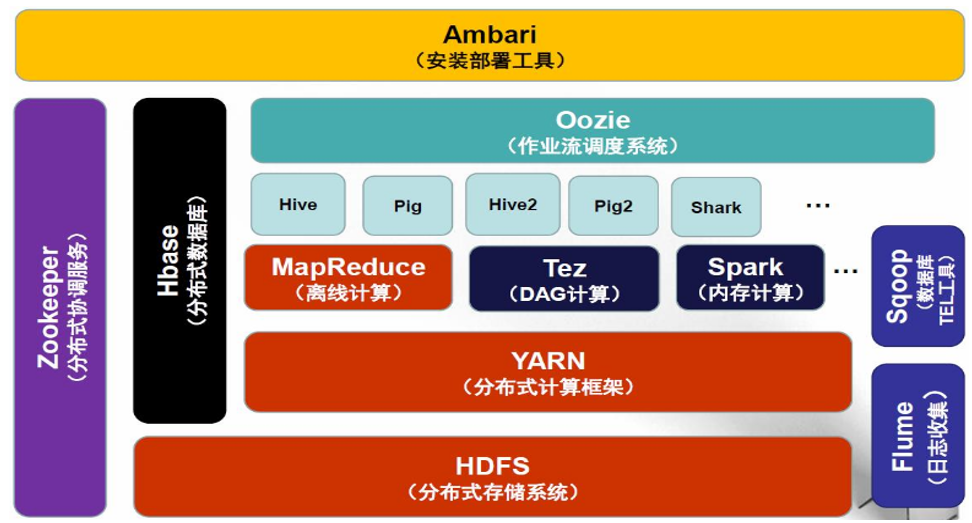
Hadoop2 生态系统架构

- HDFS:构建于廉价计算机集群之上的分布式文件系统,低成本、高可靠性、高吞吐量
- MapReduce:分布式编程模型和软件框架,用于在集群上编写对海量数据处理的并行化程序
- Common:整体架构提供基础支撑性功能,主要包括了文件系统、RPC和数据串行化库
- Hive:数据仓库工具,将结构化数据文件映射为库表,并提供强大的类SQL查询功能
- Hbase:分布式的、面向列的数据库,是一个适合于非结构化海量数据存储的数据库
- Pig:适合海量数据分析的脚本语言工具,包括了一个数据分析语言和支持的运行环境
- Sqoop:在Hadoop与传统数据库间进行数据交换的工具,支持两者之间的数据导入和导出
- Zookeeper:维护Hadoop集群的配置和命名信息,并提供分布式锁同步功能和群组管理功能
- Ambari:安装、管理和监控Hadoop集群的Web界面工具。目前已支持大部分组件的管理,就 Ambari 的作用来说,就是创建、管理、监视 Hadoop 的集群
Hadoop的生态圈
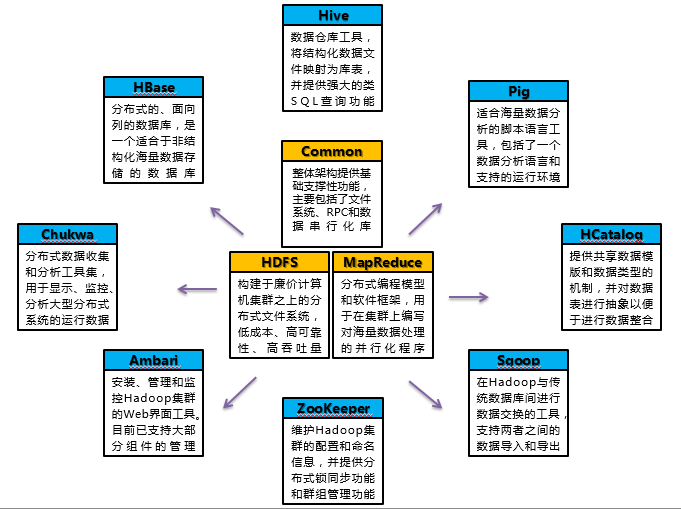
Hadoop生态系统详解:
- HDFS:分布式文件系统
- MapReduce:分布式并行编程模型
- YARN:资源管理和调度器
- Tez:运行在YARN之上的下一代Hadoop查询处理框架,它会将很多的mr任务分析优化后构建一个有向无环图,保证最高的工作效率
- Hive:Hadoop上的数据仓库
- Hbase:Hadoop上的非关系型的分布式数据库
- Pig:一个基于Hadoop的大规模数据分析平台,提供类似SQL的查询语言Pig Latin
- Sqoop:用于在Hadoop与传统数据库之间进行数据传递
- Oozie ['u:zɪ]:Hadoop上的工作流管理系统
- Zookeeper:提供分布式协调一致性服务
- Storm:流计算框架
- Flume:一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统
- Ambari:Hadoop快速部署工具,支持Apache Hadoop集群的供应、管理和监控
- Kafka:一种高吞吐量的分布式发布订阅消息系统,可以处理消费者规模的网站中的所有动作流数据
- Spark:类似于Hadoop MapReduce的通用并行框架
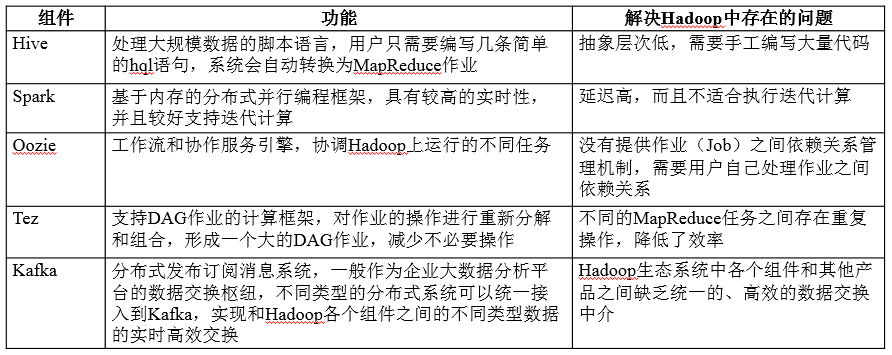
Hadoop项目结构
| 组件 |
功能 |
| HDFS |
分布式文件系统 |
| MapReduce |
分布式并行编程模型 |
| YARN |
资源管理和调度器 |
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1138
1138











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









