






【飞桨开发者说】顾茜,PPDE飞桨开发者技术专家,烟草行业开发工程师,毕业于厦门大学数学科学学院,研究方向为:人工智能在烟草行业的应用。

该项目使用WaveFlow(Github地址:
https://github.com/PaddlePaddle/Parakeet/blob/develop/examples/waveflow/train.py)作为语音合成模型示例任务,并结合Transformer TTS验证语音合成效果。
下载安装命令
## CPU版本安装命令
pip install -f https://paddlepaddle.org.cn/pip/oschina/cpu paddlepaddle
## GPU版本安装命令
pip install -f https://paddlepaddle.org.cn/pip/oschina/gpu paddlepaddle-gpu
Parakeet是飞桨近期上新的语音合成套件,用于实现端到端的语音合成。如果您使用过各类读书app或者某些浏览器、插件的朗读功能,这些都是典型的TTS(Text To Speech)场景。本项目将使用WaveFlow语音合成模型完成相关任务,并结合Transformer TTS验证语音合成效果,比如输入“Hello World”,文字转语音效果如下。
WaveFlow模型介绍
WaveFlow来自百度研究院的论文WaveFlow: A Compact Flow-based Model for Raw Audio,飞桨复现了该语音合成模型。根据官网介绍,模型只有5.9M参数量,比经典的WaveGlow语音合成模型小了15倍,同时语音合成效果也非常好。WaveFlow和WaveGlow都是基于流的生成模型,它们和GAN都属于生成模型家族。
需要注意的是,WaveFlow是个vocoder(声码器,一种将声学参数转换成语音波形的工具),不能直接实现文字转语音,需要与Parakeet库中的TTS模型DeepVoice 3、Transformer TTS或FastSpeech模型结合,实现文字转语音的语音合成。
关于模型的详细介绍请参考:
WaveFlow论文地址:
https://arxiv.org/abs/1912.01219
WaveFlow: A Compact Flow-Based Model for Raw Audio:
http://research.baidu.com/Blog/index-view?id=139
参考资料:理解基于流的生成模型
WaveGlow: a Flow-based Generative Network for Speech Synthesis:
https://github.com/NVIDIA/waveglow
Transformer TTS文字转语音模型
Parakeet使用飞桨核心框架的动态图方式复现了Transformer TTS文字转语音模型,根据论文Neural Speech Synthesis with Transformer Network实现了基于Transformer的语音合成系统。
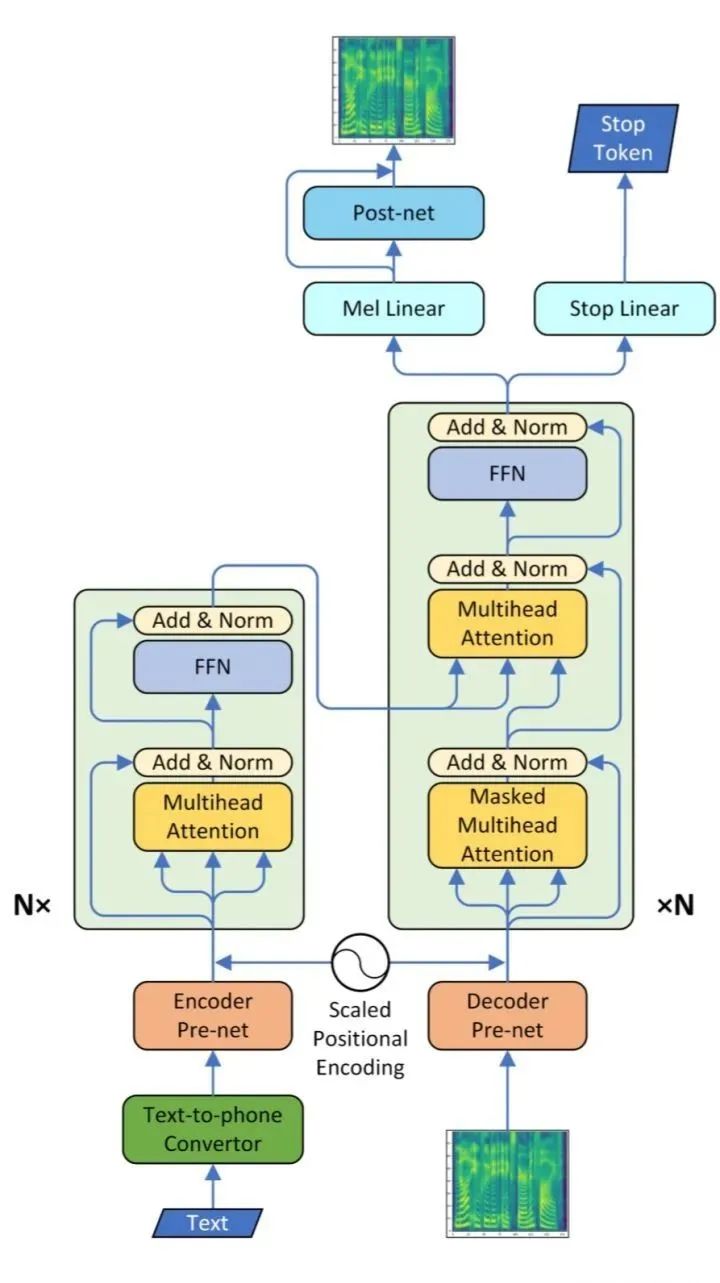
在这篇论文中,作者把Transformer和Tacotron2融合,形成了TransformerTTS。
"模型的主体还是Original Transformer,只是在输入阶段和输出阶段为了配合语音数据的特性做了改变。首先是Encoder的Input阶段,先将text逐字符转化为编号,方便Embedding,然后进入Encoder PreNet,这层网络由一个Embedding layer和三层卷积层构成,转化为512维的向量后,进入Transformer Encoder。
其次是Transformer的Decoder部分,分为Input和Output。Input通过一个PreNet,将80维的梅尔声谱图转化为512维向量,这里的PreNet是一个三层的全连接网络(个人认为论文中应当解释一下为什么Encoder的PreNet是用卷积设计的,而Decoder的PreNet由全连接网络就可以解决问题);Output部分与Tacotron2的设计完全一致。"
——摘自:基于Transformer的语音合成系统
Parakeet库中Transformer TTS支持两种vocoder,分别是Griffin-Lim algorithm和WaveFlow。WaveFlow属于基于深度神经网络的声码器,而Griffin-Lim是在仅知幅度谱、不知道相位谱的条件下重建语音的算法,属于经典声码器,算法简单,高效,但是合成的声音比较颤抖,机器感较强。
关于模型和声码器的详细介绍请参考:
Transformer TTS论文地址:
https://arxiv.org/abs/1809.08895
基于Transformer的语音合成系统:
https://zhuanlan.zhihu.com/p/66931179
Griffin-lim算法:
https://blog.csdn.net/CSDN_71560364126/article/details/103968034
数据集介绍
本文实验中将会使用LJ Speech语音数据集。这个数据集由13100句短语音组成,时长共计24小时。所有语音由同一名说话人录制,录制设备是Macbook Pro的内建麦克风,采样率为22050Hz。LJSpeech数据集的地址:
https://keithito.com/LJ-Speech-Dataset/。
开发基于Parakeet的语音合成模型方法
下面咱们开始基于AI Studio开发基于Parakeet的语音合成模型。由于AI Studio上是Notebook的环境,所以在运行cd命令的时候前面需要加上百分号,而运行其它shell命令的时候,前面需要加上叹号。
第一步:下载Parakeet模型库
和PaddleDetection不同,目前Parakeet模型库目前文件还是比较少的,因此尽管在Gitee上没有镜像,直接去Github上拉取不需要花太长时间(一般也不会中断)。
!git clone https://github.com/PaddlePaddle/Parakeet
第二步:安装依赖库
安装 libsndfile1:
在Ubuntu上安装libsndfile1库。以Ubuntu操作系统为例,一定要装有libsndfile1这个开源声音文件格式处理库。libsndfile1库在其他平台上包名可能不同,比如在 centos 上包名为 libsndfile,可以用“sudo yum install libsndfile”安装。目前AI Studio已经内置了该处理库,无需额外安装。
!sudo apt-get install libsndfile1
在AI Studio上,用户在创建项目过程中可以选择PaddlePaddle1.8.0环境,在该环境上WaveFlow可以正常训练。
安装 Parakeet:
!git clone https://github.com/PaddlePaddle/Parakeet
%cd Parakeet
!pip install -e .
安装 nltk中的美国英语CMU发音词典
import nltk
nltk.download("punkt")
nltk.download("cmudict")
在Notebook环境都比较简单,照做就行。如果执行nltk.download()时出现网络不通的报错,可以参考如下链接解决:
https://www.cnblogs.com/webRobot/p/6065831.html
第三步:准备数据集和预训练模型
Parakeet项目提供了WaveFlow模型在64, 96和128隐藏层大小(比如 128 则意味着每个隐藏层的大小是 128)下的预训练模型。本文将使用隐藏层大小为128的模型。
!mkdir examples/waveflow/data
!tar xjvf /home/aistudio/data/data35036/LJSpeech.tar.bz2 -C examples/waveflow/data/
!unzip /home/aistudio/data/data45064/waveflow_128.zip -d examples/waveflow/
第四步:环境配置和YAML文件准备
1. 执行“export CUDA_VISIBLE_DEVICES=0”指定GPU
2.根据个人的任务需要修改配置文件。配置文件的位置在
Parakeet/examples/waveflow/configs/waveflow_ljspeech.yaml。读者可以根据需要改动一些超参数,例如使用预训练模型、调整learning_rate、batch_size等。
第五步:开始训练
执行如下命令调用train.py脚本启动训练。
!cd examples/waveflow
/home/aistudio/Parakeet/examples/waveflow
!python train.py \
--config=./waveflow_res128_ljspeech_ckpt_1.0/waveflow_ljspeech.yaml \
--root=./data/LJSpeech-1.1 \
--name=finetune \
--checkpoint=./waveflow_res128_ljspeech_ckpt_1.0/step-2000000 \
--batch_size=8 \
--use_gpu=true
查看评估指标:
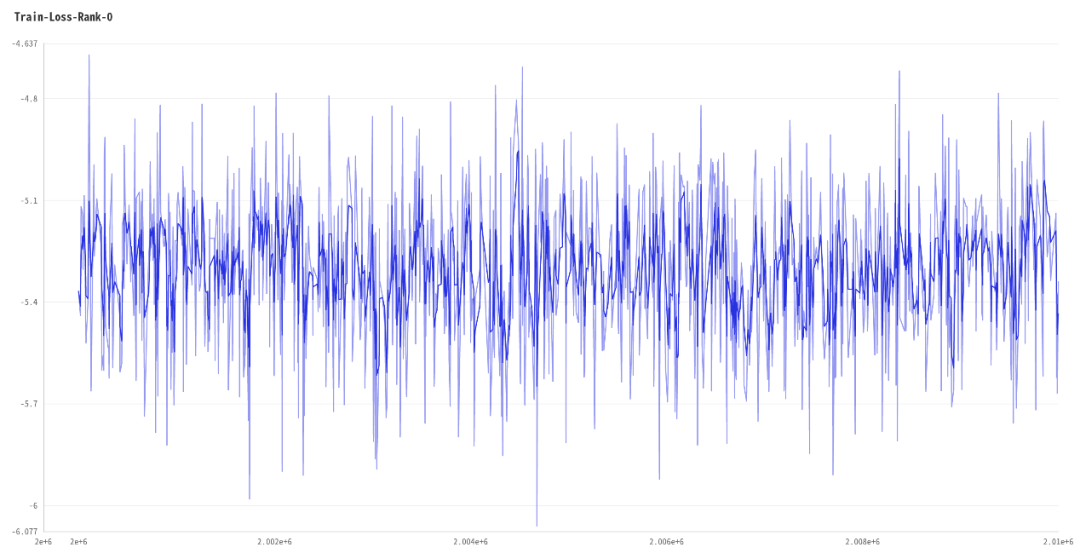
1. Train-Loss 训练集上loss变化趋势:
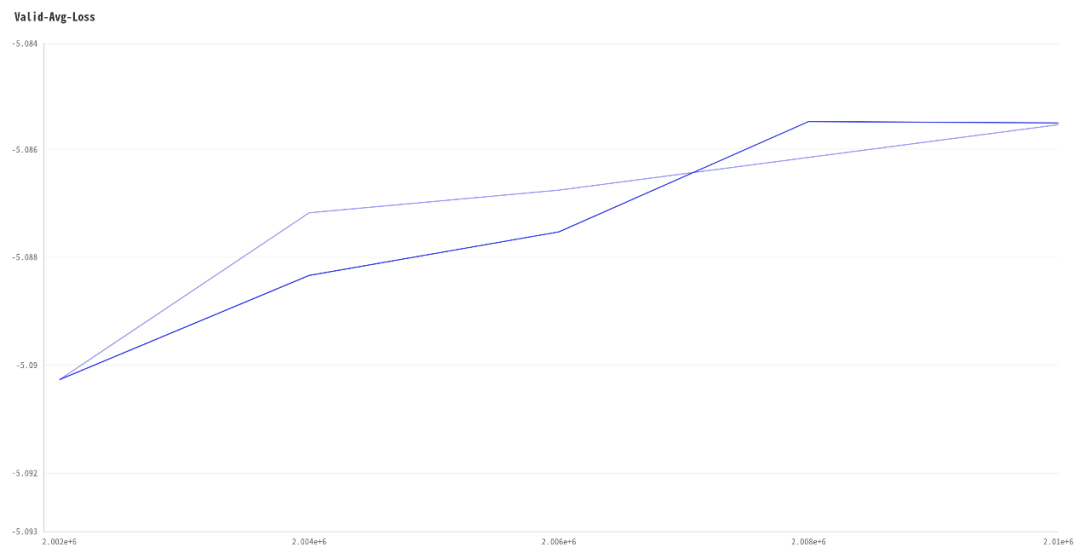
2. Valid-Avg-Loss 验证集上loss变化趋势:
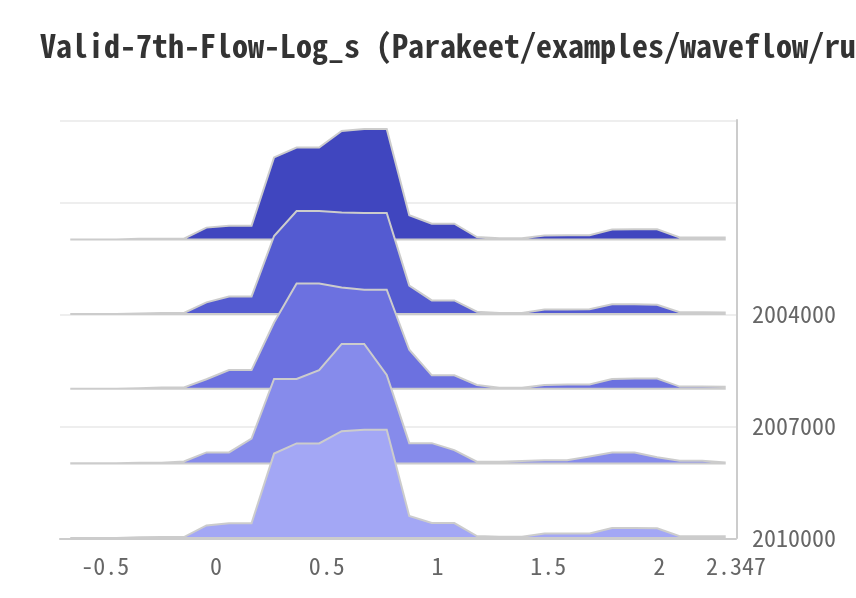
3. Valid-7th-Flow-Log_s 模型中的第7个流生成的log scale:
第六步:使用Transformer TTS + WaveFlow实现文字转语音(TTS)
在Parakeet模型库中,Deep Voice 3、Transformer TTS或FastSpeech是TTS模型,下面演示如何使用训练好的WaveFlow模型权重作为声码器,通过Transformer TTS实现文字转语音。
Transformer TTS的训练过程与WaveFlow非常类似,本文直接使用Parakeet项目中提供的预训练模型演示效果,使用时需要同时配置Transformer TTS和WaveFlow的预训练模型权重。
在Transformer TTS的示例中,最终会将下面这段文字转为语音:
“Life was like a box of chocolates, you never know what you're gonna get.”
也可以修改
Parakeet/examples/transformer_tts/synthesis.py文件中synthesis()方法的输入,合成我们想要的其它英文,比如Hello world!
if __name__ == '__main__':
parser = argparse.ArgumentParser(description="Synthesis model")
add_config_options_to_parser(parser)
args = parser.parse_args()
# Print the whole config setting.
pprint(vars(args))
synthesis(
"Hello world!",
args)
切换目录到TransformerTTS示例
!cd /home/aistudio/Parakeet/examples/transformer_tts
下载并解压Transformer TTS预训练模型
!wget https://paddlespeech.bj.bcebos.com/Parakeet/transformer_tts_ljspeech_ckpt_1.0.zip
!unzip transformer_tts_ljspeech_ckpt_1.0.zip -d transformer_tts_ljspeech_ckpt_1.0/
!python synthesis.py \
--use_gpu=1 \
--output='./synthesis' \
--config='transformer_tts_ljspeech_ckpt_1.0/ljspeech.yaml' \
--checkpoint_transformer='./transformer_tts_ljspeech_ckpt_1.0/step-120000' \
--vocoder='waveflow' \
--config_vocoder='../waveflow/waveflow_res128_ljspeech_ckpt_1.0/waveflow_ljspeech.yaml' \
--checkpoint_vocoder='../waveflow/runs/waveflow/finetune/checkpoint/step-2010000'
{'checkpoint_transformer': './transformer_tts_ljspeech_ckpt_1.0/step-120000',
'checkpoint_vocoder': '../waveflow/runs/waveflow/finetune/checkpoint/step-2010000',
'config': 'transformer_tts_ljspeech_ckpt_1.0/ljspeech.yaml',
'config_vocoder': '../waveflow/waveflow_res128_ljspeech_ckpt_1.0/waveflow_ljspeech.yaml',
'max_len': 1000,
'output': './synthesis',
'stop_threshold': 0.5,
'use_gpu': 1,
'vocoder': 'waveflow'}
[checkpoint] Rank 0: loaded model from ./transformer_tts_ljspeech_ckpt_1.0/step-120000.pdparams
[checkpoint] Rank 0: loaded model from ../waveflow/runs/waveflow/finetune/checkpoint/step-2010000.pdparams
Synthesis completed !!!
使用如下代码即可在Notebook中试听音频效果:
import IPython
IPython.display.Audio('./synthesis/samples/waveflow.wav')
下载安装命令
## CPU版本安装命令
pip install -f https://paddlepaddle.org.cn/pip/oschina/cpu paddlepaddle
## GPU版本安装命令
pip install -f https://paddlepaddle.org.cn/pip/oschina/gpu paddlepaddle-gpu
来源:oschina
链接:https://my.oschina.net/u/4067628/blog/4535787















 4941
4941











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









