




简介:RabbitMQ是一个基于AMQP协议的开源消息队列系统,广泛应用于分布式系统中实现高效的消息通信。本“RabbitMQ学习代码”压缩包包含丰富的示例代码和实践教程,帮助开发者掌握RabbitMQ的核心概念、交换机类型及实际应用场景。通过学习,开发者可以熟练使用RabbitMQ实现消息的发送、接收、路由控制,并提升在任务调度、日志处理、异步通信等方面的开发能力。
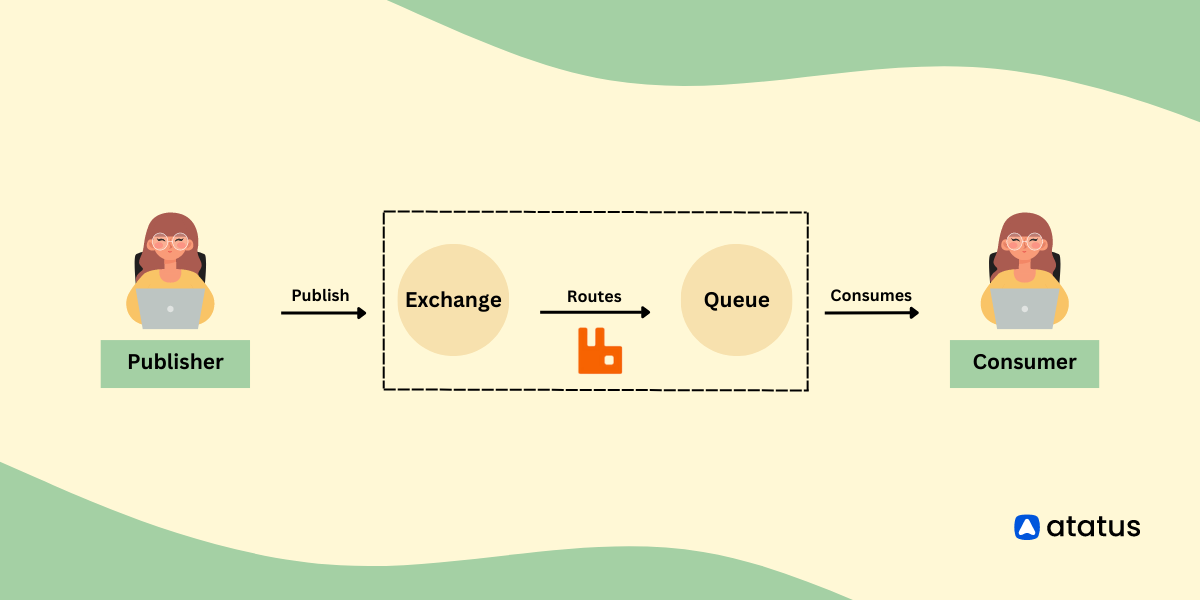
1. RabbitMQ简介与核心组件
RabbitMQ 是一个开源的、基于 AMQP(高级消息队列协议)的消息中间件,广泛应用于分布式系统中实现服务间异步通信与解耦。其核心架构由 Producer(生产者)、Consumer(消费者)、Broker(消息代理)、Exchange(交换机)、Queue(队列)等组件构成,消息通过 Exchange 路由至对应的 Queue,最终由 Consumer 消费。
其典型工作流程如下:
- Producer 发送消息到 RabbitMQ Broker;
- Broker 根据 Exchange 类型和 Binding 规则将消息路由到一个或多个 Queue;
- Consumer 从 Queue 中获取并处理消息;
- 整个过程中,消息可持久化、确认机制确保其可靠性。
在实际应用中,RabbitMQ 常用于异步任务处理、日志聚合、事件驱动架构等场景,具备高可用、可扩展和易集成的特性。
2. Exchange交换机类型详解
RabbitMQ 的核心机制之一在于其灵活的消息路由方式,而 Exchange(交换机)正是这一机制的核心。Exchange 决定了消息如何被分发到各个队列中。RabbitMQ 提供了四种主要的 Exchange 类型: Direct Exchange 、 Fanout Exchange 、 Topic Exchange 和 Headers Exchange 。每种类型适用于不同的消息路由场景,掌握其原理和使用方式对于构建高效、可靠的消息系统至关重要。
在本章中,我们将逐一深入解析这四种 Exchange 类型,包括它们的路由机制、应用场景、配置方式,并结合实际代码示例进行说明。
2.1 Direct Exchange的工作原理与使用
Direct Exchange 是 RabbitMQ 中最基础的 Exchange 类型之一。它通过 Routing Key 实现消息的精确匹配路由,只有队列绑定的 Routing Key 与消息的 Routing Key 完全一致时,消息才会被发送到该队列。
2.1.1 基于精确匹配的路由规则
Direct Exchange 的核心路由规则是“ 精确匹配 ”。它的工作流程如下:
- Producer 发送消息到 Direct Exchange,并指定一个 Routing Key。
- Exchange 查找绑定到它的所有队列,并检查绑定时使用的 Binding Key 是否与消息的 Routing Key 相等。
- 若匹配成功,消息被发送到对应的队列;否则,消息将被丢弃(除非有默认队列)。
路由流程图(Mermaid 格式)
graph TD
A[Producer] -->|发送消息+Routing Key| B((Direct Exchange))
B --> C{Routing Key匹配?}
C -->|是| D[绑定队列]
C -->|否| E[丢弃消息]
示例代码(Python + Pika)
import pika
# 建立连接
connection = pika.BlockingConnection(pika.ConnectionParameters('localhost'))
channel = connection.channel()
# 声明exchange
channel.exchange_declare(exchange='direct_logs', exchange_type='direct')
# 发送消息
severity = 'error' # Routing Key
message = 'A critical error occurred!'
channel.basic_publish(
exchange='direct_logs',
routing_key=severity,
body=message
)
print(f" [x] Sent {severity}:{message}")
connection.close()
逐行解析:
-
exchange_declare:声明一个名为direct_logs的 Direct Exchange。 -
basic_publish:发送消息到该 Exchange,并指定routing_key为error。 - 只有绑定了
errorBinding Key 的队列才能接收到该消息。
参数说明:
| 参数名 | 含义 |
|---|---|
| exchange | 要发送消息的目标 Exchange 名称 |
| routing_key | 消息的路由键,用于匹配绑定的队列 |
| body | 消息体内容 |
2.1.2 实现点对点消息分发的场景应用
Direct Exchange 常用于实现 点对点通信 。例如,在一个日志系统中,可以将不同级别的日志(info、warning、error)分别发送到不同的队列,供不同的消费者处理。
应用示例
假设我们有两个队列:
-
error_queue绑定errorRouting Key -
info_queue绑定infoRouting Key
当生产者发送一条 error 消息时,只有 error_queue 会收到该消息,实现定向投递。
队列绑定关系表
| Exchange 名称 | 队列名称 | Binding Key |
|---|---|---|
| direct_logs | error_queue | error |
| direct_logs | info_queue | info |
2.2 Fanout Exchange的广播机制
Fanout Exchange 是 RabbitMQ 中最简单的 Exchange 类型之一。它不关心 Routing Key,而是将消息 广播 给所有绑定的队列。
2.2.1 消息广播的实现方式
Fanout Exchange 的工作机制如下:
- Producer 发送消息到 Fanout Exchange。
- Exchange 忽略 Routing Key,直接将消息复制并发送给所有绑定的队列。
路由流程图(Mermaid 格式)
graph TD
A[Producer] -->|发送消息| B((Fanout Exchange))
B --> C[队列1]
B --> D[队列2]
B --> E[队列3]
示例代码(Python)
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters('localhost'))
channel = connection.channel()
# 声明fanout类型的exchange
channel.exchange_declare(exchange='logs', exchange_type='fanout')
# 发送消息,无需指定routing_key
channel.basic_publish(
exchange='logs',
routing_key='',
body='This is a broadcast message'
)
print(" [x] Sent broadcast message")
connection.close()
逐行解析:
-
exchange_type='fanout':声明一个广播类型的 Exchange。 -
routing_key='':Fanout Exchange 忽略该参数,留空即可。 - 所有绑定到
logsExchange 的队列都会收到该消息。
2.2.2 多订阅者通知系统设计
Fanout Exchange 非常适合用于实现 事件通知系统 ,如系统状态变更通知、用户操作日志广播等。
例如,一个电商平台中有多个服务(如库存服务、订单服务、物流服务),当用户下单时,可以通过 Fanout Exchange 将“订单创建”事件广播给所有相关服务,确保各服务及时响应。
场景示例表
| 服务名称 | 用途 |
|---|---|
| OrderService | 创建订单 |
| StockService | 更新库存 |
| Logistics | 触发物流流程 |
所有服务绑定到同一个 Fanout Exchange 上,即可同步收到订单创建事件。
2.3 Topic Exchange的模式匹配机制
Topic Exchange 是一种灵活的路由方式,支持通配符匹配 Routing Key,适用于多维度的消息路由。
2.3.1 通配符路由规则详解
Topic Exchange 使用 点分格式的 Routing Key 和 通配符 实现模式匹配:
-
*(星号):匹配一个单词 -
#(井号):匹配零个或多个单词
示例规则匹配表
| Binding Key | 匹配的 Routing Key | 是否匹配 |
|---|---|---|
| stock.* | stock.update | ✅ |
| stock.* | stock.delete | ✅ |
| stock.* | stock.us.update | ❌ |
| stock.# | stock.us.update | ✅ |
| stock.# | stock | ✅ |
| stock.*.update | stock.eu.update | ✅ |
| stock.*.update | stock.eu.delete | ❌ |
2.3.2 动态消息路由与多维度过滤
Topic Exchange 适用于 多维消息分类 的场景。例如,在一个日志系统中,可以使用 Topic Exchange 将日志按照设备类型(mobile、web)、地区(us、eu)和日志级别(info、error)等多个维度进行分类和分发。
示例代码(Python)
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters('localhost'))
channel = connection.channel()
# 声明topic类型的exchange
channel.exchange_declare(exchange='topic_logs', exchange_type='topic')
# 发送消息,带有多维Routing Key
routing_key = 'stock.us.update'
message = 'Stock in US has been updated'
channel.basic_publish(
exchange='topic_logs',
routing_key=routing_key,
body=message
)
print(f" [x] Sent {routing_key}:{message}")
connection.close()
逐行解析:
-
exchange_type='topic':声明 Topic 类型的 Exchange。 -
routing_key='stock.us.update':多维 Routing Key。 - 绑定时可以使用通配符如
stock.*.update或stock.#来匹配。
场景应用表
| Binding Key | 匹配的 Routing Key示例 | 用途说明 |
|---|---|---|
| stock.*.update | stock.us.update | 匹配指定地区更新 |
| stock.# | stock.eu.update、stock | 匹配所有股票消息 |
| *.update | stock.update、order.update | 匹配所有更新事件 |
2.4 Headers Exchange的高级路由方式
Headers Exchange 是 RabbitMQ 中较为高级的 Exchange 类型,它通过 消息头(Headers) 来决定路由,而非 Routing Key。这种 Exchange 更适合用于复杂业务逻辑中的多条件路由。
2.4.1 基于消息头的路由逻辑
Headers Exchange 的工作方式如下:
- Producer 发送消息时附带一组 Headers(键值对)。
- Exchange 根据绑定队列时定义的 Header 匹配规则,决定将消息发送到哪些队列。
- 匹配方式可以是“全匹配”(all)或“任意匹配”(any)。
示例代码(Python)
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters('localhost'))
channel = connection.channel()
# 声明headers类型的exchange
channel.exchange_declare(exchange='header_logs', exchange_type='headers')
# 设置消息headers
headers = {
'x-match': 'all', # 匹配方式:全匹配
'type': 'error',
'source': 'auth'
}
# 发送消息
channel.basic_publish(
exchange='header_logs',
routing_key='',
body='Authentication error occurred',
properties=pika.BasicProperties(headers=headers)
)
print(" [x] Sent message with headers")
connection.close()
逐行解析:
-
exchange_type='headers':声明 Headers 类型的 Exchange。 -
x-match:匹配方式,可选all或any。 -
headers:自定义的键值对,用于路由匹配。 -
routing_key无需设置,留空即可。
匹配规则说明表
| x-match | 匹配条件 | 示例队列绑定规则 |
|---|---|---|
| all | 所有Header键值必须完全匹配 | type=error, source=auth |
| any | 至少一个Header键值匹配即可 | type=error |
2.4.2 复杂业务场景下的灵活路由策略
Headers Exchange 非常适合用于 多条件筛选 的复杂场景。例如在一个监控系统中,可以根据多个维度(如错误类型、发生位置、影响等级)组合判断消息应被发送到哪个队列处理。
应用场景表
| 队列名称 | 匹配Header规则 | 用途说明 |
|---|---|---|
| auth_error | type=error, source=auth | 身份认证错误处理 |
| high_level | severity=high | 高优先级错误处理 |
| any_error | type=error(x-match: any) | 所有错误汇总处理 |
本章通过深入解析四种 Exchange 类型(Direct、Fanout、Topic、Headers)的路由机制、代码实现和实际应用场景,为构建灵活的消息路由系统提供了坚实的基础。下一章将围绕 Queue 队列的创建与管理展开,进一步完善 RabbitMQ 的整体架构设计。
3. Queue队列的创建与管理
队列(Queue)是 RabbitMQ 中消息的最终存储单元,是消息传递过程中的关键组成部分。消息在 Exchange 中经过路由后,最终会进入与之绑定的队列中,等待消费者进行消费。因此,如何创建和管理队列,直接影响系统的可靠性、可扩展性以及性能表现。本章将详细介绍队列的创建方式、属性配置以及高级管理功能,帮助开发者全面掌握 RabbitMQ 队列的使用方法。
3.1 队列的基本创建方式
RabbitMQ 提供了多种方式来创建队列,包括使用命令行工具 rabbitmqctl 和通过客户端 SDK(如 Java、Python、Node.js 等)进行编程创建。理解这些方法有助于开发者在不同场景下灵活地管理队列。
3.1.1 命令行工具创建队列
rabbitmqctl 是 RabbitMQ 提供的命令行管理工具,可以用于创建、删除、查看队列等操作。以下是一个使用 rabbitmqctl 创建队列的示例:
rabbitmqctl declare_queue queue_name durable auto_delete arguments
-
queue_name:队列名称。 -
durable:是否持久化,值为true或false。 -
auto_delete:是否自动删除,当最后一个消费者断开连接后是否删除队列。 -
arguments:队列的额外参数,如最大长度、死信队列等。
示例:创建一个名为 task_queue 的持久化队列
rabbitmqctl declare_queue task_queue true false
该命令创建了一个名为 task_queue 的持久化队列,并且不会在消费者断开连接后自动删除。
注意 :使用 rabbitmqctl 创建队列时,必须确保 RabbitMQ 服务正在运行,并且你有相应的操作权限。
3.1.2 使用客户端 SDK 创建队列
除了命令行工具,开发者还可以通过 RabbitMQ 客户端 SDK 创建队列。以下以 Python 为例,展示如何使用 pika 库创建队列:
import pika
# 建立连接
connection = pika.BlockingConnection(pika.ConnectionParameters('localhost'))
channel = connection.channel()
# 声明一个持久化队列
channel.queue_declare(queue='task_queue', durable=True)
print(' [*] Waiting for messages. To exit press CTRL+C')
# 关闭连接
connection.close()
代码解释与参数说明 :
-
pika.BlockingConnection:创建一个阻塞式连接到 RabbitMQ 服务。 -
queue_declare方法的参数: -
queue:队列名称。 -
durable=True:设置队列为持久化,即使 RabbitMQ 重启也不会丢失。 -
exclusive=False(默认):队列不被独占。 -
auto_delete=False(默认):队列不会在消费者断开后自动删除。 -
arguments=None(默认):队列的其他可选参数。
流程图:队列创建逻辑流程
graph TD
A[建立与RabbitMQ的连接] --> B{是否需要自定义队列属性?}
B -->|是| C[设置durable, auto_delete等参数]
B -->|否| D[使用默认参数创建队列]
C --> E[调用queue_declare创建队列]
D --> E
E --> F[完成队列创建]
通过 SDK 创建队列,可以在应用程序启动时自动完成队列的初始化,避免手动操作带来的繁琐性,同时也便于自动化部署和测试。
3.2 队列的属性配置
在创建队列时,可以通过配置不同的属性来控制队列的行为,例如是否持久化、最大长度、自动删除、死信队列等。合理配置这些属性可以提升系统的稳定性和性能。
3.2.1 持久化与自动删除设置
持久化(Durable) :如果队列设置为持久化(durable=True),即使 RabbitMQ 服务器重启,队列及其消息也不会丢失。适用于需要长期保留消息的场景,如任务队列。
自动删除(Auto Delete) :如果队列设置为自动删除(auto_delete=True),则当最后一个消费者断开连接后,队列将被自动删除。适用于临时队列,如 RPC 调用中的回调队列。
示例代码:设置持久化与自动删除
channel.queue_declare(
queue='logs_queue',
durable=True, # 队列持久化
auto_delete=False # 不自动删除
)
表格:队列属性对比
| 属性名 | 默认值 | 说明 |
|---|---|---|
| durable | False | 是否持久化,决定队列是否在重启后保留 |
| auto_delete | False | 是否在最后一个消费者断开后自动删除队列 |
| exclusive | False | 是否为独占队列,仅限当前连接访问 |
| arguments | None | 队列的扩展参数,如最大长度、死信队列等 |
3.2.2 最大长度与死信队列配置
最大长度(x-max-length) :设置队列的最大消息数量。当队列中的消息数量超过该限制时,旧的消息将被丢弃或转发到死信队列。
死信队列(Dead Letter Exchange, DLX) :当消息被拒绝、过期或超过最大长度限制时,会被转发到指定的死信队列,便于后续处理或日志记录。
示例:配置最大长度与死信队列
arguments = {
'x-max-length': 100, # 队列最多保留100条消息
'x-dead-letter-exchange': 'dlx_exchange' # 设置死信交换机
}
channel.queue_declare(
queue='important_queue',
durable=True,
arguments=arguments
)
逻辑分析 :
-
x-max-length: 控制队列消息数量上限,防止内存溢出或性能下降。 -
x-dead-letter-exchange: 指定死信交换机名称,消息被拒绝或过期后会转发至此交换机。 - 可以进一步结合
x-dead-letter-routing-key设置死信消息的路由键。
流程图:死信队列配置逻辑
graph TD
A[消息进入队列] --> B{是否超过最大长度或被拒绝?}
B -->|是| C[检查是否配置了死信交换机]
C --> D{是否存在DLX?}
D -->|是| E[转发到死信队列]
D -->|否| F[丢弃消息]
B -->|否| G[正常等待消费]
3.3 队列的高级管理功能
除了基本的创建和属性配置,RabbitMQ 还提供了一些高级管理功能,如队列策略(Policy)、监控与性能调优等,帮助运维人员和开发者更好地管理队列。
3.3.1 队列策略的定义与应用
RabbitMQ 支持通过策略(Policy)为多个队列统一配置行为,而无需逐个设置。策略可以在 RabbitMQ 管理插件中或使用 rabbitmqctl 命令进行设置。
示例:设置最大长度策略
rabbitmqctl set_policy MaxLengthPolicy "^important.*" \
'{"max-length":100}' \
--apply-to queues
-
MaxLengthPolicy:策略名称。 -
"^important.*":匹配队列名的正则表达式。 -
{"max-length":100}:策略内容。 -
--apply-to queues:表示该策略应用于队列。
逻辑分析 :
- 使用策略可以统一管理多个队列的配置,避免重复设置。
- 策略优先级高于队列的本地配置。
- 可用于设置最大长度、死信交换机、镜像队列等。
3.3.2 队列监控与性能调优
RabbitMQ 提供了丰富的监控接口和管理插件,可以实时查看队列的状态、消息堆积情况、消费者数量等信息。
使用管理插件查看队列信息
RabbitMQ 管理插件提供了 Web 界面,可以通过浏览器访问: http://localhost:15672 (默认用户名和密码为 guest/guest)。
在 Queues 标签页中可以查看所有队列的详细信息,包括:
- 消息数量(Messages)
- 消费者数量(Consumers)
- 持久化状态(Durable)
- 自动删除状态(Auto delete)
- 消息速率(Message rates)
性能调优建议 :
- 监控队列消息堆积情况,避免内存溢出。
- 合理设置预取数量(prefetch count),控制消费者的并发消费能力。
- 对高吞吐量队列启用镜像队列(Mirrored Queues),提升可用性。
- 使用死信队列收集异常消息,便于分析与重试。
本章从队列的基本创建方式入手,详细讲解了命令行与 SDK 创建队列的方法,并深入探讨了队列的属性配置(如持久化、最大长度、死信队列)以及高级管理功能(如策略配置、监控与调优)。这些内容为开发者提供了全面的队列管理能力,有助于构建稳定、高效的消息系统。
4. Binding绑定规则配置
Binding 是 RabbitMQ 中用于连接 Exchange 与 Queue 的桥梁,它决定了消息如何从 Exchange 路由到具体的 Queue。不同的 Exchange 类型对 Binding 的依赖方式和配置规则不同,因此理解 Binding 的工作机制及其优化方式,是构建高效、灵活消息路由系统的关键。本章将从 Binding 的基础概念出发,逐步深入讲解其配置逻辑、参数优化及动态管理方式,帮助开发者在不同 Exchange 类型下设计合理的绑定策略。
4.1 Binding 与 Exchange 类型的匹配逻辑
Binding 的作用是将消息从 Exchange 路由至 Queue,但不同 Exchange 类型对 Binding 的依赖程度和匹配方式各不相同。了解这些差异,有助于在设计消息系统时选择合适的 Exchange 类型并配置正确的 Binding 规则。
4.1.1 Direct、Fanout、Topic 下的 Binding 配置差异
Binding 的配置方式取决于所使用的 Exchange 类型。以下是三种常见 Exchange 类型中 Binding 的配置逻辑:
| Exchange 类型 | Binding 作用 | Routing Key 使用方式 | Binding Key 匹配逻辑 |
|---|---|---|---|
| Direct | Binding Key 必须与发送消息的 Routing Key 完全匹配 | 必须指定 | 精确匹配 |
| Fanout | Binding Key 被忽略,所有绑定的 Queue 都会接收到消息 | 不使用 | 无 |
| Topic | Binding Key 使用通配符 * 和 # 匹配 Routing Key | 必须指定 | 通配符匹配 |
示例:Direct Exchange 的 Binding 配置
import pika
# 建立连接
connection = pika.BlockingConnection(pika.ConnectionParameters('localhost'))
channel = connection.channel()
# 声明 Exchange
channel.exchange_declare(exchange='direct_logs', exchange_type='direct')
# 声明队列
channel.queue_declare(queue='error_queue')
# 绑定队列到 Exchange,指定 Binding Key 为 'error'
channel.queue_bind(exchange='direct_logs', queue='error_queue', routing_key='error')
print("Binding created for 'error' severity.")
逐行解读分析:
- 第 4 行:建立与 RabbitMQ 的连接。
- 第 5 行:创建一个通道对象。
- 第 8 行:声明一个 Direct 类型的 Exchange,名为
direct_logs。 - 第 11 行:声明一个队列
error_queue。 - 第 14 行:将队列绑定到 Exchange,并指定 Binding Key 为
error。 - 第 16 行:输出绑定成功提示。
参数说明:
-
exchange:指定绑定的目标 Exchange。 -
queue:需要绑定的队列名称。 -
routing_key:绑定时使用的 Binding Key,对于 Direct Exchange 必须与发送时的 Routing Key 一致。
示例:Fanout Exchange 的 Binding 配置
# 声明 Fanout 类型 Exchange
channel.exchange_declare(exchange='fanout_logs', exchange_type='fanout')
# 声明两个队列
channel.queue_declare(queue='fanout_queue1')
channel.queue_declare(queue='fanout_queue2')
# 绑定队列到 Exchange,忽略 Routing Key
channel.queue_bind(exchange='fanout_logs', queue='fanout_queue1')
channel.queue_bind(exchange='fanout_logs', queue='fanout_queue2')
说明:
- Fanout Exchange 不依赖 Binding Key,因此
queue_bind中无需指定routing_key。 - 消息会被广播给所有绑定的队列。
示例:Topic Exchange 的 Binding 配置
# 声明 Topic 类型 Exchange
channel.exchange_declare(exchange='topic_logs', exchange_type='topic')
# 声明两个队列
channel.queue_declare(queue='topic_queue1')
channel.queue_declare(queue='topic_queue2')
# 绑定队列并设置通配符 Binding Key
channel.queue_bind(exchange='topic_logs', queue='topic_queue1', routing_key='*.error')
channel.queue_bind(exchange='topic_logs', queue='topic_queue2', routing_key='kern.#')
Binding Key 解释:
-
*.error:匹配任意以.error结尾的消息,如kern.error、db.error。 -
kern.#:匹配以kern开头的所有层级消息,如kern.info、kern.auth.warning。
4.1.2 多绑定关系的设计策略
在实际系统中,通常会存在多个 Exchange 与多个 Queue 的复杂绑定关系。合理设计 Binding 可以提升系统的灵活性与可维护性。
策略一:基于业务逻辑的绑定
将不同业务模块的消息通过不同的 Exchange 与 Queue 绑定,避免消息混杂。
策略二:基于优先级的绑定
为高优先级的消息设置独立的 Binding,确保其优先被处理。
策略三:动态绑定设计
通过运行时配置 Binding,实现动态路由机制,如通过配置中心动态修改 Binding Key。
4.2 Binding 的参数配置与优化
Binding 的配置不仅涉及 Exchange 与 Queue 的连接,还包括一些参数设置,如 Binding Key、Headers 等。这些参数的选择与优化对消息的路由效率和系统灵活性有直接影响。
4.2.1 Routing Key 的设置与匹配规则
Routing Key 是消息发送时指定的关键字,Binding Key 是绑定时使用的匹配规则。两者的匹配方式取决于 Exchange 类型。
示例:使用 Routing Key 发送消息
channel.basic_publish(
exchange='topic_logs',
routing_key='kern.critical',
body='A critical kernel error occurred.'
)
参数说明:
-
exchange:目标 Exchange 名称。 -
routing_key:发送消息时指定的 Routing Key。 -
body:消息内容。
Routing Key 与 Binding Key 的匹配逻辑(Topic Exchange):
| Routing Key | Binding Key | 是否匹配 | 说明 |
|---|---|---|---|
| kern.info | *.info | ✅ | 匹配第一个层级的 info |
| kern.critical.auth | kern.# | ✅ | 匹配所有以 kern 开头的消息 |
| user.error | *.error | ✅ | 匹配任意以 .error 结尾的消息 |
| db.warning | kern.# | ❌ | 不以 kern 开头 |
4.2.2 Headers Exchange 中的绑定策略
Headers Exchange 是一种基于消息头(Headers)进行路由的 Exchange 类型,不依赖 Routing Key,而是通过消息头的键值对进行匹配。
示例:Headers Exchange 的 Binding 配置
# 声明 Headers 类型 Exchange
channel.exchange_declare(exchange='headers_logs', exchange_type='headers')
# 声明队列
channel.queue_declare(queue='headers_queue')
# 设置 Binding 参数:headers 和 x-match
binding_args = {
'x-match': 'all',
'log_type': 'error',
'level': 'high'
}
# 绑定队列到 Headers Exchange
channel.queue_bind(
exchange='headers_logs',
queue='headers_queue',
arguments=binding_args
)
逐行解读分析:
- 第 4 行:声明一个 Headers 类型的 Exchange。
- 第 7 行:声明一个队列。
- 第 9–12 行:定义绑定参数,
x-match可选值为all(全部匹配)或any(任一匹配),这里设置为all。 - 第 15–18 行:绑定队列到 Exchange,并传递匹配参数。
示例:发送带有 Headers 的消息
headers = {
'log_type': 'error',
'level': 'high'
}
props = pika.BasicProperties(headers=headers)
channel.basic_publish(
exchange='headers_logs',
routing_key='', # Headers Exchange 不使用 routing_key
body='High-level error message.',
properties=props
)
参数说明:
-
headers:消息头信息,用于匹配 Binding 中的规则。 -
x-match:决定是否全部匹配或任一匹配。
4.3 Binding 的动态管理与运行时修改
在生产环境中,Binding 的配置可能需要根据业务需求进行动态调整。RabbitMQ 提供了多种方式支持 Binding 的运行时管理,包括通过管理插件和程序化方式进行修改。
4.3.1 RabbitMQ 管理插件的绑定操作
RabbitMQ 自带的管理插件提供了图形化界面,可以方便地查看、添加和删除 Binding。
操作步骤:
-
启用管理插件:
bash rabbitmq-plugins enable rabbitmq_management -
访问管理界面:
http://localhost:15672/ -
登录后进入 Exchanges 页面,选择目标 Exchange。
-
在 Bindings 标签页中查看或添加新的 Binding。
使用 Mermaid 流程图表示管理插件操作流程:
graph TD
A[启用 RabbitMQ 管理插件] --> B[访问管理界面]
B --> C[选择 Exchange]
C --> D[查看 Binding 列表]
D --> E[添加或删除 Binding]
4.3.2 程序化绑定关系的维护
除了图形化操作,还可以通过 API 实现 Binding 的动态维护。
示例:使用 pika 动态删除 Binding
# 删除绑定
channel.queue_unbind(
exchange='topic_logs',
queue='topic_queue1',
routing_key='*.error'
)
参数说明:
-
exchange:目标 Exchange。 -
queue:绑定的队列。 -
routing_key:绑定时使用的 Binding Key。
示例:动态添加 Binding
# 添加新的 Binding
channel.queue_bind(
exchange='topic_logs',
queue='topic_queue1',
routing_key='user.#'
)
通过程序化方式维护 Binding,可以实现动态路由配置,适用于需要频繁调整消息流向的系统场景。
总结:
Binding 是 RabbitMQ 消息路由的核心配置项,其配置方式与 Exchange 类型密切相关。通过深入理解不同 Exchange 类型下 Binding 的工作原理、参数配置方式及动态管理手段,开发者可以构建出更加灵活、高效的消息路由系统。下一章节将继续深入探讨消息生产者的实现细节,包括消息的发送方式、格式设置及确认机制等关键内容。
5. Producer消息生产者实现
消息生产者(Producer)是 RabbitMQ 架构中负责将消息发布到 Broker 的核心角色。其设计与实现直接影响到系统的消息发送效率、可靠性和稳定性。本章将从代码层面详细讲解消息生产者的实现流程,涵盖连接建立、消息格式设置、属性配置以及消息确认机制等关键内容,帮助开发者构建高效、可靠的消息发送系统。
5.1 消息生产者的基本实现流程
消息生产者的基本实现流程可以分为两个主要步骤: 建立连接与信道 、 发送消息到指定Exchange 。这一流程是所有语言客户端(如 Java、Python、Go、Node.js 等)的通用逻辑,理解这一流程是构建稳定生产者的基础。
5.1.1 建立连接与信道
在 RabbitMQ 中,生产者与 Broker 的通信是通过 AMQP 协议 进行的。生产者首先需要建立一个 TCP 连接(Connection) 到 RabbitMQ Broker,然后在连接上创建一个 信道(Channel) 来发送和接收消息。
示例:使用 Python 的 pika 客户端建立连接与信道
import pika
# 创建连接参数
credentials = pika.PlainCredentials('guest', 'guest')
parameters = pika.ConnectionParameters('localhost',
5672,
'/',
credentials)
# 建立连接
connection = pika.BlockingConnection(parameters)
# 创建信道
channel = connection.channel()
参数说明:
-
'guest': RabbitMQ 默认用户名 -
'guest': 默认密码 -
'localhost': Broker 的 IP 地址 -
5672: RabbitMQ 的 AMQP 端口 -
'/': 虚拟主机(vhost)
逻辑分析:
-
pika.PlainCredentials用于封装认证信息,是连接的凭证。 -
pika.ConnectionParameters定义了连接的配置信息。 -
BlockingConnection是同步阻塞模式的连接对象。 -
channel()方法在连接上创建一个信道,后续所有消息的发送操作都通过这个信道完成。
补充:为何使用信道而不是多个连接?
RabbitMQ 的设计中, 信道(Channel)是轻量级的通信通道 ,多个信道可以复用同一个 TCP 连接。这样做的优势包括:
- 减少系统资源消耗;
- 避免 TCP 连接过多带来的网络开销;
- 提高消息发送效率。
5.1.2 发送消息到指定 Exchange
一旦连接和信道建立成功,生产者就可以通过 basic_publish 方法向指定的 Exchange 发送消息。
示例:发送一条消息到默认 Exchange
channel.basic_publish(
exchange='logs', # Exchange 名称
routing_key='error', # 路由键
body='This is an error message!' # 消息体
)
参数说明:
-
exchange: 指定消息发送的目标 Exchange。如果为空字符串(''),则使用默认的 Direct Exchange。 -
routing_key: 路由键,用于决定消息如何被路由到队列。 -
body: 消息内容,通常是字符串或序列化后的数据(如 JSON)。
逻辑分析:
- 此方法会将消息发送到指定的 Exchange,Exchange 根据绑定规则将消息路由至一个或多个 Queue。
- 如果没有与 Exchange 绑定的 Queue,消息会被丢弃(除非配置了死信队列)。
流程图:消息发送流程
graph TD
A[建立TCP连接] --> B[创建信道]
B --> C[设置Exchange与Routing Key]
C --> D[调用basic_publish发送消息]
D --> E[消息进入Exchange]
E --> F[根据Binding规则路由到Queue]
5.2 消息的格式与属性设置
在实际开发中,消息不仅仅是字符串,还可能携带元数据、TTL(Time To Live)、优先级等高级属性。RabbitMQ 支持通过 pika.BasicProperties 类来设置这些属性。
5.2.1 设置消息内容、类型与元数据
示例:设置消息属性
import pika
import json
# 构造消息体
message = {
"id": "MSG001",
"type": "alert",
"content": "Disk usage is over 90%",
"timestamp": "2024-04-05T12:30:00Z"
}
# 设置消息属性
properties = pika.BasicProperties(
content_type='application/json',
content_encoding='utf-8',
delivery_mode=2, # 持久化消息
headers={'source': 'monitoring_system', 'priority': 'high'}
)
# 发送消息
channel.basic_publish(
exchange='alerts',
routing_key='high',
body=json.dumps(message),
properties=properties
)
参数说明:
-
content_type: 内容类型,常用于描述消息的格式(如application/json)。 -
content_encoding: 编码方式,通常为utf-8。 -
delivery_mode: 消息持久化设置,2 表示消息持久化。 -
headers: 自定义消息头,用于携带额外的元数据。
逻辑分析:
- 通过
BasicProperties设置消息属性,可以增强消息的语义表达能力; - 持久化设置(
delivery_mode=2)确保消息在 Broker 重启后不会丢失; - 自定义 Header 可用于后续消费者端的路由、过滤或日志追踪。
5.2.2 消息的 TTL 与优先级配置
示例:设置消息 TTL 和优先级
properties = pika.BasicProperties(
expiration='60000', # 消息存活时间(单位:毫秒)
priority=8, # 消息优先级(0~9)
delivery_mode=2
)
channel.basic_publish(
exchange='urgent',
routing_key='critical',
body='System will shut down in 1 minute.',
properties=properties
)
参数说明:
-
expiration: 消息在队列中的最大存活时间,单位为毫秒。 -
priority: 消息优先级,范围为 0~9,优先级高的消息会被优先消费(前提是队列支持优先级)。
逻辑分析:
- 设置
expiration可防止消息在队列中堆积; - 优先级机制可用于实现“紧急消息优先处理”的业务需求;
- 使用 TTL 和优先级时,需要确保队列支持这些功能(如声明时设置
x-max-priority属性)。
5.3 消息确认机制与事务支持
为了确保消息能够可靠地发送到 Broker,RabbitMQ 提供了两种机制: Confirm 模式 和 事务机制 。在高并发或高可靠性场景中,建议启用这些机制。
5.3.1 Confirm 模式保障消息送达
Confirm 模式是一种异步确认机制,Broker 在接收到消息后会返回一个确认(ack)给生产者,确保消息已成功入队。
示例:启用 Confirm 模式
channel.confirm_delivery() # 启用 confirm 模式
try:
channel.basic_publish(
exchange='logs',
routing_key='info',
body='System is running normally.',
properties=pika.BasicProperties(delivery_mode=2)
)
print("Message confirmed.")
except pika.exceptions.UnroutableError:
print("Message was not delivered.")
逻辑分析:
-
confirm_delivery()启用 Confirm 模式; - 如果消息无法被路由(如没有绑定的队列),会抛出
UnroutableError异常; - Confirm 模式适用于异步场景,性能较好,推荐使用。
5.3.2 事务机制在高可靠性场景中的应用
事务机制是一种同步确认方式,通过事务提交来确保消息的可靠性。虽然可靠性高,但性能开销较大。
示例:使用事务机制
channel.tx_select() # 开启事务
try:
channel.basic_publish(
exchange='orders',
routing_key='new',
body='Order #20240405 created.'
)
channel.tx_commit() # 提交事务
except Exception as e:
channel.tx_rollback() # 回滚事务
print(f"Transaction failed: {e}")
逻辑分析:
-
tx_select()开启事务; -
tx_commit()提交事务,确保消息写入成功; -
tx_rollback()回滚事务,在异常发生时保证数据一致性; - 事务机制适用于金融、支付等对数据一致性要求极高的场景。
5.3.3 Confirm 模式与事务机制对比
| 特性 | Confirm 模式 | 事务机制 |
|---|---|---|
| 实现方式 | 异步 | 同步 |
| 性能 | 高 | 低 |
| 可靠性 | 高(消息入队确认) | 极高(原子操作) |
| 适用场景 | 日志、通知、异步任务 | 金融、支付、数据一致性要求高 |
| 开启方式 | confirm_delivery() | tx_select() |
| 回调支持 | 支持回调 | 不支持回调 |
5.3.4 消息重试与幂等性设计建议
在生产环境中,消息发送可能会失败,因此建议:
- 启用 Confirm 模式并设置重试策略;
- 记录消息 ID 或业务唯一标识,防止重复消费;
- 结合幂等性设计,确保即使消息重复发送也不会造成业务错误。
小结
本章详细讲解了 RabbitMQ 消息生产者的实现流程,包括连接建立、消息格式设置、属性配置以及消息确认机制。通过代码示例与逻辑分析,读者可以掌握不同语言客户端的核心实现方式,并根据业务需求选择合适的发送策略。下一章将深入讲解消费者端的实现逻辑,帮助构建完整的消息处理系统。
6. Consumer消息消费者实现
消费者是RabbitMQ中负责接收和处理消息的关键组件。一个良好的消费者设计不仅能提高系统的吞吐能力,还能确保消息的可靠消费、异常处理和系统稳定性。本章将从消费者的基本架构入手,详细讲解Pull模式与Push模式的区别与实现方式,探讨消息确认机制(包括自动确认与手动确认),并深入分析消息处理过程中的异常控制与重试机制。此外,还将讨论多消费者并发下的调度策略与性能优化手段。
6.1 消息消费者的基本架构
消费者在RabbitMQ中的基本职责是从队列中取出消息并进行业务处理。其核心流程包括:连接RabbitMQ Broker、声明或绑定队列、监听消息、处理消息、确认消费。
6.1.1 消费者连接与消息监听
消费者需要通过AMQP协议与RabbitMQ Broker建立连接。通常使用客户端SDK(如Python的 pika 、Java的 Spring AMQP 、Go的 streadway/amqp 等)实现连接和消息监听。
示例代码(以Python pika 为例):
import pika
# 建立连接
connection = pika.BlockingConnection(pika.ConnectionParameters('localhost'))
channel = connection.channel()
# 声明队列
channel.queue_declare(queue='task_queue', durable=True)
# 定义回调函数
def callback(ch, method, properties, body):
print(f" [x] Received {body}")
# 模拟处理耗时
time.sleep(1)
print(" [x] Done")
ch.basic_ack(delivery_tag=method.delivery_tag) # 手动确认
# 设置QoS(一次只处理一个消息)
channel.basic_qos(prefetch_count=1)
# 开始监听
channel.basic_consume(queue='task_queue', on_message_callback=callback)
print(' [*] Waiting for messages. To exit press CTRL+C')
channel.start_consuming()
代码逻辑分析:
- 连接建立 :通过
pika.BlockingConnection连接本地RabbitMQ服务器。 - 声明队列 :使用
queue_declare声明一个持久化的队列task_queue。 - 回调函数 :定义处理消息的
callback函数,并在其中模拟消息处理过程。 - QoS设置 :
basic_qos设置消费者一次只处理一个消息,实现公平调度。 - 消息监听 :
basic_consume注册回调函数并开始监听队列。 - 手动确认 :通过
basic_ack进行手动确认,确保消息在处理完成后才被移除。
6.1.2 自动确认与手动确认模式
RabbitMQ提供了两种确认机制: 自动确认(autoAck) 和 手动确认(manualAck) 。
| 确认模式 | 行为描述 | 适用场景 |
|---|---|---|
| autoAck | 消费者收到消息后立即确认,队列将消息删除 | 高吞吐但不保证处理成功 |
| manualAck | 消费者在处理完成后主动发送确认 | 需要确保消息可靠消费 |
示例:设置手动确认模式
# 将 auto_ack 设为 False
channel.basic_consume(queue='task_queue', on_message_callback=callback, auto_ack=False)
⚠️ 注意 :如果使用
autoAck=True,而消息处理失败,消息将丢失。因此,在生产环境中推荐使用manualAck,并在处理完成后发送确认。
6.2 消息的处理与异常控制
消息处理过程中可能会遇到网络中断、业务逻辑异常、数据解析错误等问题。如何优雅地处理这些异常,决定了系统的稳定性和消息的可靠性。
6.2.1 消息重试机制设计
消息重试机制是消费者实现中的核心部分。常见的策略包括:
- 最大重试次数限制 :避免无限重试导致死循环。
- 延迟重试 :使用延迟队列或TTL+死信队列实现重试间隔。
- 死信队列(DLQ) :将多次失败的消息投递到专门队列,供后续人工处理。
示例:使用TTL和死信队列实现重试
# 声明原始队列,并绑定死信交换机
channel.exchange_declare(exchange='dlx_exchange', exchange_type='direct')
channel.queue_declare(
queue='retry_queue',
durable=True,
arguments={
'x-dead-letter-exchange': 'dlx_exchange',
'x-message-ttl': 5000, # 5秒后未被确认则转发
'x-max-length': 3 # 最多3次重试
}
)
# 声明死信队列
channel.queue_declare(queue='dead_letter_queue', durable=True)
channel.queue_bind(exchange='dlx_exchange', queue='dead_letter_queue', routing_key='')
# 消费者监听 retry_queue
def callback(ch, method, properties, body):
try:
# 业务处理逻辑
if some_failure_condition:
raise Exception("Simulated failure")
ch.basic_ack(delivery_tag=method.delivery_tag)
except Exception as e:
print(f" [!] Message failed: {e}")
# 不发送ack,消息将被转发至DLQ
参数说明:
-
x-dead-letter-exchange:指定死信交换机。 -
x-message-ttl:消息在队列中存活时间。 -
x-max-length:限制队列最大长度,防止无限堆积。
6.2.2 死信队列与异常消息处理
死信队列是处理异常消息的重要手段。它允许我们将多次失败的消息集中到一个队列中,供后续分析、重试或人工干预。
典型流程图(mermaid):
graph TD
A[消息进入队列] --> B{是否消费成功?}
B -- 是 --> C[发送ack,消息删除]
B -- 否 --> D[未确认,达到TTL]
D --> E[转发到DLQ]
E --> F[人工处理/监控报警]
📌 建议 :结合日志系统与监控告警,对进入死信队列的消息进行实时追踪和分析。
6.3 多消费者并发与负载均衡
在高并发场景下,单个消费者可能无法满足处理需求。通过多消费者并发处理,可以提升系统的吞吐能力和容错能力。
6.3.1 公平调度与消息分配策略
RabbitMQ支持通过设置 prefetch_count 控制每个消费者一次处理的消息数量,从而实现 公平调度(Fair Dispatch) 。
示例代码:
# 设置每个消费者最多同时处理1条消息
channel.basic_qos(prefetch_count=1)
📌 原理 :RabbitMQ不会将新消息发送给正在处理消息的消费者,而是发送给空闲的消费者,实现负载均衡。
6.3.2 消费者并发配置与性能优化
在实际部署中,消费者可以以多线程、多进程或多个实例的方式运行,以提升处理能力。
多消费者部署结构(mermaid):
graph LR
A[RabbitMQ Queue] --> B[Consumer 1]
A --> C[Consumer 2]
A --> D[Consumer 3]
B --> E[业务处理]
C --> E
D --> E
性能优化建议:
| 优化方向 | 说明 |
|---|---|
| 并发数控制 | 合理设置并发消费者数量,避免资源争用 |
| 线程池管理 | 使用线程池或协程提高CPU利用率 |
| 消息批处理 | 批量确认消息,减少网络开销 |
| 异步处理 | 消费端异步处理业务逻辑,防止阻塞监听线程 |
示例:使用线程池异步处理消息
from concurrent.futures import ThreadPoolExecutor
executor = ThreadPoolExecutor(max_workers=4)
def async_callback(ch, method, properties, body):
def process():
try:
# 业务处理
print(f"Processing {body}")
time.sleep(1)
ch.basic_ack(delivery_tag=method.delivery_tag)
except Exception as e:
print(f"Error: {e}")
ch.basic_nack(delivery_tag=method.delivery_tag, requeue=False)
executor.submit(process)
# 设置QoS
channel.basic_qos(prefetch_count=4)
channel.basic_consume(queue='task_queue', on_message_callback=async_callback, auto_ack=False)
说明:
- 使用
ThreadPoolExecutor实现消息处理的异步化。 -
basic_nack用于在处理失败时拒绝消息,并设置不重新入队。 - 通过并发处理提升整体吞吐能力。
小结
消费者是RabbitMQ消息处理链路的终端,其实现质量直接影响系统的稳定性与消息可靠性。本章详细讲解了消费者的基本架构、监听方式、确认机制、异常处理与重试策略,并探讨了多消费者并发下的调度与性能优化手段。通过合理设计消费者逻辑、结合死信队列与异步处理机制,可以有效提升系统的容错能力与吞吐效率。
📌 下一章预告 :第七章将深入探讨RabbitMQ的 消息确认机制与持久化配置 ,包括生产端Confirm机制、消费端Ack机制、消息与队列的持久化设置,以及集群环境下的高可用设计。
7. RabbitMQ消息确认与持久化机制
消息的可靠传递是RabbitMQ的核心特性之一,本章将深入探讨消息确认机制、队列与Exchange的持久化配置,以及如何通过持久化保障系统在故障恢复时的数据完整性。
7.1 消息确认机制详解
在分布式系统中,消息的可靠性投递和消费是关键问题。RabbitMQ提供了两种确认机制: 生产端Confirm机制 和 消费端Ack机制 ,它们分别保障消息从生产者发送到Broker,以及从Broker投递给消费者的过程是可靠的。
7.1.1 生产端Confirm机制
生产端的Confirm机制用于确保消息成功发送到RabbitMQ Broker。开启Confirm模式后,Broker会在消息被写入磁盘或内存后返回确认信息(ack),否则返回nack,生产者可以根据返回结果决定是否重发。
代码示例:Java客户端开启Confirm机制
Channel channel = connection.createChannel();
channel.confirmSelect(); // 开启Confirm模式
String message = "Hello RabbitMQ";
channel.basicPublish("exchange.name", "routing.key", null, message.getBytes());
// 添加监听器处理确认结果
channel.addConfirmListener((deliveryTag, multiple) -> {
System.out.println("Message confirmed. DeliveryTag: " + deliveryTag);
}, (deliveryTag, multiple) -> {
System.out.println("Message not confirmed. DeliveryTag: " + deliveryTag);
// 可在此处进行重发处理
});
-
channel.confirmSelect():启用Confirm模式。 -
addConfirmListener:添加确认监听器,用于接收Broker返回的ack或nack。 -
deliveryTag:消息的唯一标识符。 -
multiple:是否批量确认。
7.1.2 消费端Ack机制与可靠性保障
消费者端的Ack机制用于确认消息是否被正确消费。如果消费者在处理消息时发生异常,可以通过拒绝消息并重新入队,保障消息不会丢失。
代码示例:Java客户端手动确认消息
Channel channel = connection.createChannel();
channel.basicConsume("queue.name", false, (consumerTag, delivery) -> {
String message = new String(delivery.getBody(), "UTF-8");
try {
// 模拟业务处理
System.out.println("Received: " + message);
// 业务逻辑处理完成后手动确认
channel.basicAck(delivery.getEnvelope().getDeliveryTag(), false);
} catch (Exception e) {
// 消息处理失败,拒绝消息并重新入队
channel.basicNack(delivery.getEnvelope().getDeliveryTag(), false, true);
}
}, consumerTag -> {});
-
basicConsume:开启消费者,第二个参数设为false表示关闭自动确认。 -
basicAck:手动确认消息。 -
basicNack:拒绝消息,第三个参数为true表示消息重新入队。
7.2 持久化配置与数据安全
为了防止RabbitMQ服务异常或宕机导致的消息丢失,需要对Exchange、Queue以及消息本身进行持久化配置。
7.2.1 Exchange、Queue与消息的持久化设置
- Exchange持久化 :设置Exchange为持久化类型,重启后不会丢失。
- Queue持久化 :声明队列为持久化,即使服务重启也能保留队列结构。
- 消息持久化 :消息属性设置为持久化,确保消息写入磁盘。
代码示例:声明持久化Exchange与Queue
// 声明持久化Exchange
channel.exchangeDeclare("my_exchange", "direct", true, false, null);
// 声明持久化队列
channel.queueDeclare("my_queue", true, false, false, null);
// 绑定Exchange与Queue
channel.queueBind("my_queue", "my_exchange", "routing.key", null);
// 发送持久化消息
AMQP.BasicProperties props = new AMQP.BasicProperties.Builder()
.deliveryMode(2) // 2表示消息持久化
.contentType("application/json")
.build();
channel.basicPublish("my_exchange", "routing.key", props, "Hello Persistent".getBytes());
| 属性 | 说明 |
|---|---|
durable | 是否持久化(true/false) |
autoDelete | 是否自动删除(当最后一个消费者取消订阅后) |
deliveryMode | 消息持久化模式:1(内存)、2(磁盘) |
7.2.2 RabbitMQ持久化机制的性能考量
虽然持久化可以提高数据安全性,但也带来了性能开销:
- 磁盘IO压力 :每条持久化消息都需要写入磁盘。
- 日志写入频率 :默认使用
confirm机制时,每条消息都会写入事务日志。 - 批量写入优化 :可通过配置
publisher confirm与持久化批量提交提升性能。
推荐配置优化:
- 使用
confirm机制 +持久化结合。 - 启用
publisher confirm的批量确认模式。 - 使用SSD硬盘提升IO性能。
7.3 持久化与集群环境下的高可用设计
在集群环境下,RabbitMQ支持镜像队列(Mirror Queue)来实现队列数据的高可用,确保即使节点宕机也不会丢失消息。
7.3.1 镜像队列与数据复制策略
镜像队列将主队列的数据复制到多个节点上,实现高可用和容灾能力。可以通过策略(Policy)配置镜像规则。
创建镜像队列策略命令:
rabbitmqctl set_policy ha-policy "^ha." '{"ha-mode":"exactly","ha-params":2,"ha-sync-mode":"automatic"}'
-
ha-mode:exactly表示精确复制2个节点。 -
ha-sync-mode:automatic表示自动同步。
策略匹配规则:
该策略会匹配以 ha. 开头的队列名称,自动为其创建镜像队列。
7.3.2 RabbitMQ集群中的消息持久化实践
在集群环境中,消息的持久化需满足以下条件:
- 队列与消息都需持久化 :确保即使主节点宕机,消息不会丢失。
- 镜像队列同步机制 :保证副本队列的数据一致性。
- 节点故障恢复机制 :故障节点恢复后,镜像队列自动同步数据。
典型部署结构:
graph TD
A[生产者] --> B((RabbitMQ Broker1))
A --> C((RabbitMQ Broker2))
A --> D((RabbitMQ Broker3))
B <--> E[镜像队列]
C <--> E
D <--> E
E --> F[消费者]
- 每个Broker节点都维护队列的副本。
- 消息写入主队列后,通过内部复制机制同步到镜像节点。
- 消费者可从任意节点拉取消息,提升可用性与负载均衡能力。
简介:RabbitMQ是一个基于AMQP协议的开源消息队列系统,广泛应用于分布式系统中实现高效的消息通信。本“RabbitMQ学习代码”压缩包包含丰富的示例代码和实践教程,帮助开发者掌握RabbitMQ的核心概念、交换机类型及实际应用场景。通过学习,开发者可以熟练使用RabbitMQ实现消息的发送、接收、路由控制,并提升在任务调度、日志处理、异步通信等方面的开发能力。

















 1702
1702

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









