






1、初步学习
数据处理
xs:60000张图片,28*28大小,将所有像素点按一列排列,数据集变为了[60000, 784]的二维矩阵。
ys:60000张图片,每个图片有一个标签标识图片中数字,采用one-hot向量,数据集变为[60000, 10]的二维矩阵。
softmax函数
用来给不同的对象分配概率,一般放在分类网络最后一层。
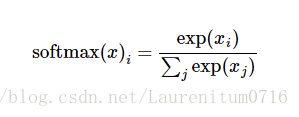
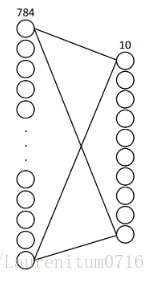
接下来,实现一个非常简单的两层全连接网络来完成MNIST数据分类的问题,输入层784个神经元,对应每张图片的784个像素点;输出层10个神经元,对应0-9这10个数字,实现分类。
计算流程
1.数据准备
2.准备好placeholder
3.初始化参数/权重
4.计算预测结果
5.计算损失值
6.初始化optimizer
7.指定迭代次数,并在session执行graph
代码
# -*- coding:utf-8 -*-
# 安装数据集,第一次执行可能需要下载
import tensorflow.examples.tutorials.mnist.input_data as input_data
mnist = input_data.read_data_sets("MNIST_data/",one_hot=True)
import tensorflow as tf
# 载入数据集
mnist = input_data.read_data_sets("MNIST_data", one_hot=True)
# 每个批次送100张图片
batch_size = 100
# 计算一共有多少个批次
n_batch = mnist.train.num_examples // batch_size
# 准备好placeholder
x = tf.placeholder(tf.float32, [None, 784])
y = tf.placeholder(tf.float32,[None, 10])
# 初始化参数、权重
W = tf.Variable(tf.zeros([784, 10]))
b = tf.Variable(tf.zeros([10]))
# 计算预测结果
prediction = tf.nn.softmax(tf.matmul(x, W) + b)
# 计算损失值
# 先使用二次代价函数
loss = tf.reduce_mean(tf.square(y - prediction))
# 初始化optimizer
# 梯度下降优化器,学习率建议给的稍大些
learning_rate = 0.2
optimizer = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss)
# 结果存放在一个布尔型列表中
# tf.argmax(vector,1)意思是返回vector中最大值的索引号,如果vector是一个向量,那就返回一个值
# 如果是一个矩阵就返回一个向量,该向量每一维都是相应矩阵行的最大值元素的索引号
# 在这里,argmax就是返回的就是向量中最大值(1)的位置,并进行比较,相同则返回1,反之为0
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(prediction, 1))# 这里输出的矩阵里面是true和false
# 准确率
# tf.cast 是类型转换函数
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
for epoch in range(21):
for batch in range(n_batch):
batch_xs, batch_ys = mnist.train.next_batch(batch_size)
sess.run(optimizer, feed_dict={x: batch_xs, y: batch_ys})
acc = sess.run(accuracy, feed_dict={x: mnist.test.images, y: mnist.test.labels})
if epoch % 2 == 0:
print("Iter" + str(epoch) + ",Testing Accuracy" + str(acc))结果如下
Iter0,Testing Accuracy8366.0
Iter2,Testing Accuracy8841.0
Iter4,Testing Accuracy8987.0
Iter6,Testing Accuracy9054.0
Iter8,Testing Accuracy9107.0
Iter10,Testing Accuracy9146.0
Iter12,Testing Accuracy9193.0
Iter14,Testing Accuracy9227.0
Iter16,Testing Accuracy9244.0
Iter18,Testing Accuracy9265.0
Iter20,Testing Accuracy9286.0这个结果暂时不算很好,我们将逐渐对其进行改进
2、添加隐藏层
1、数据准备
2、准备好placeholder
3、初始化参数、权重
我们添加两个隐藏层,分别有500和300个神经元,这样包括输入输出层,总共4层神经网络
其中:
1)隐藏层初始化函数建议使用tf.truncated_normal()(截断的随机数)类型,而非前文的tf.zero()(初始化为0)类型
2)中间层的激活函数,本文使用tanh(双曲正切函数),建议使用ReLU函数或者Sigmoid函数,比较一个输出结果
4、计算预测结果
5、计算损失值
6、初始化optimizer
7、指定迭代次数,并在session执行graph
代码如下
# -*- coding:utf-8 -*-
# 安装数据集,第一次执行可能需要下载
import tensorflow.examples.tutorials.mnist.input_data as input_data
mnist = input_data.read_data_sets("MNIST_data/",one_hot=True)
import tensorflow as tf
# 载入数据集
mnist = input_data.read_data_sets("MNIST_data", one_hot=True)
# 每个批次送100张图片
batch_size = 100
# 计算一共有多少个批次
n_batch = mnist.train.num_examples // batch_size
# 准备好placeholder
x = tf.placeholder(tf.float32, [None, 784])
y = tf.placeholder(tf.float32,[None, 10])
# 初始化参数、权重
# 1)隐藏层初始化函数建议使用tf.truncated_normal()(截断的随机数)类型,而非前文的tf.zero()(初始化为0)类型
# 2)中间层的激活函数,本文使用tanh(双曲正切函数),建议使用ReLU函数或者Sigmoid函数,比较一个输出结果
# tf.truncated_normal() 函数从阶段的正态分布中输出随机值
# 函数原型为tf.truncated_normal(shape, mean=0.0, stddev=1.0, dtype=tf.float32, seed=None, name=None)
# 其中stddev是正态分布标准差,seed是一个生成随机数的种子,那么是操作的名字
W1 = tf.Variable(tf.truncated_normal([784, 500], stddev=0.1), name="W1")
b1 = tf.Variable(tf.zeros([500]) + 0.1, name='b1')
L1 = tf.nn.relu(tf.matmul(x, W1) + b1, name='L1')
W2 = tf.Variable(tf.truncated_normal([500, 300], stddev=0.1),name='W2')
b2 = tf.Variable(tf.zeros([300]) + 0.1, name='b2')
L2 = tf.nn.relu(tf.matmul(L1, W2) + b2, name='L2')
W3 = tf.Variable(tf.truncated_normal([300, 10], stddev=0.1), name='W3')
b3 = tf.Variable(tf.zeros([10]) + 0.1, name='b3')
# 计算预测结果
prediction = tf.nn.softmax(tf.matmul(L2,W3) + b3)
# 计算损失值
# 先使用二次代价函数
loss = tf.reduce_mean(tf.square(y - prediction))
# 初始化optimizer
# 梯度下降优化器,学习率建议给的稍大些
learning_rate = 0.2
optimizer = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss)
# 结果存放在一个布尔型列表中
# tf.argmax(vector,1)意思是返回vector中最大值的索引号,如果vector是一个向量,那就返回一个值
# 如果是一个矩阵就返回一个向量,该向量每一维都是相应矩阵行的最大值元素的索引号
# 在这里,argmax就是返回的就是向量中最大值(1)的位置,并进行比较,相同则返回1,反之为0
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(prediction, 1))# 这里输出的矩阵里面是true和false
# 准确率
# tf.cast 是类型转换函数
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
for epoch in range(21):
for batch in range(n_batch):
batch_xs, batch_ys = mnist.train.next_batch(batch_size)
sess.run(optimizer, feed_dict={x: batch_xs, y: batch_ys})
acc = sess.run(accuracy, feed_dict={x: mnist.test.images, y: mnist.test.labels})
if epoch % 2 == 0:
print("Iter" + str(epoch) + ",Testing Accuracy" + str(acc))
经测试,使用relu函数的效果最好,能达到96左右的正确率;其次tanh,能达到95;最差是sigmoid。
3、进一步改进——方差代价函数&交叉熵代价函数
C表示代价函数,为简便起见,以一个样本为例,此时二次代价函数为:
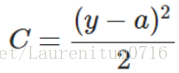
其中,y是我们期望的输出,a是神经元实际的输出:a = σ(z),z = wx + b
假如我们使用梯度下降法来调整权值参数大小,权值w和 偏置b 的梯度推导如下:
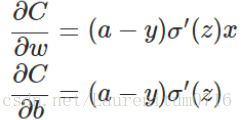
其中,z表示神经元的输入,σ表示激活函数。w和b的梯度跟激活函数的梯度成正比,激活函数的梯度越大,w和b的大小调整得越快, 训练收敛得越快。
假设我们的激活函数是sigmoid函数:
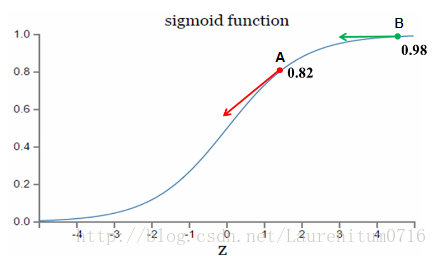
因为sigmoid的性质,导致σ·(z) 在z 取大部分值的时候会很小,这样会使得w和b 的更新很慢.
为了克服这个问题,我们换个思路,在不改变激活函数的情况下,改变代价函数,改为交叉熵代价函数:
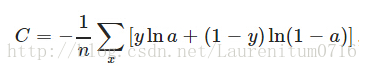
其中,y为期望的输出,a为神经元实际输出:a = σ(z), z = ∑Wj*Xj+b
同样,权重w 和 偏置 b 的梯度如下:
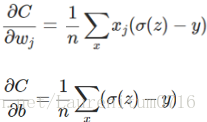
从上式可知,w、b的调整与σ·(z)无关,σ(z)-y 表示输出值与实际值的误差,当其误差越大时,梯度越大,w、b调整的越快,训练速度也越快,反之,则亦然,这正是我们想要的。
此外,交叉熵函数一般与s型函数(即sigmoid函数和tanh函数)组合适用。
步骤
1.数据准备
2.准备placeholder
3.初始化参数/权重
4.计算预测结果
5.计算损失值
这里我们使用交叉熵函数替代二次代价函数
# 计算损失值
# 先使用二次代价函数
# loss = tf.reduce_mean(tf.square(y - prediction))
# 这里我们使用交叉熵函数替代二次代价函数
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y, logits=prediction))6.初始化optimizer
全局代码
# -*- coding:utf-8 -*-
# 安装数据集,第一次执行可能需要下载
import tensorflow.examples.tutorials.mnist.input_data as input_data
mnist = input_data.read_data_sets("MNIST_data/",one_hot=True)
import tensorflow as tf
# 载入数据集
mnist = input_data.read_data_sets("MNIST_data", one_hot=True)
# 每个批次送100张图片
batch_size = 100
# 计算一共有多少个批次
n_batch = mnist.train.num_examples // batch_size
# 准备好placeholder
x = tf.placeholder(tf.float32, [None, 784])
y = tf.placeholder(tf.float32,[None, 10])
# 初始化参数、权重
# 1)隐藏层初始化函数建议使用tf.truncated_normal()(截断的随机数)类型,而非前文的tf.zero()(初始化为0)类型
# 2)中间层的激活函数,本文使用tanh(双曲正切函数),建议使用ReLU函数或者Sigmoid函数,比较一个输出结果
# tf.truncated_normal() 函数从阶段的正态分布中输出随机值
# 函数原型为tf.truncated_normal(shape, mean=0.0, stddev=1.0, dtype=tf.float32, seed=None, name=None)
# 其中stddev是正态分布标准差,seed是一个生成随机数的种子,那么是操作的名字
W1 = tf.Variable(tf.truncated_normal([784, 500], stddev=0.1), name="W1")
b1 = tf.Variable(tf.zeros([500]) + 0.1, name='b1')
L1 = tf.nn.relu(tf.matmul(x, W1) + b1, name='L1')
W2 = tf.Variable(tf.truncated_normal([500, 300], stddev=0.1),name='W2')
b2 = tf.Variable(tf.zeros([300]) + 0.1, name='b2')
L2 = tf.nn.relu(tf.matmul(L1, W2) + b2, name='L2')
W3 = tf.Variable(tf.truncated_normal([300, 10], stddev=0.1), name='W3')
b3 = tf.Variable(tf.zeros([10]) + 0.1, name='b3')
# 计算预测结果
prediction = tf.nn.softmax(tf.matmul(L2,W3) + b3)
# 计算损失值
# 先使用二次代价函数
# loss = tf.reduce_mean(tf.square(y - prediction))
# 这里我们使用交叉熵函数替代二次代价函数
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y, logits=prediction))
# 初始化optimizer
# 梯度下降优化器,学习率建议给的稍大些
learning_rate = 0.2
optimizer = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss)
# 结果存放在一个布尔型列表中
# tf.argmax(vector,1)意思是返回vector中最大值的索引号,如果vector是一个向量,那就返回一个值
# 如果是一个矩阵就返回一个向量,该向量每一维都是相应矩阵行的最大值元素的索引号
# 在这里,argmax就是返回的就是向量中最大值(1)的位置,并进行比较,相同则返回1,反之为0
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(prediction, 1))# 这里输出的矩阵里面是true和false
# 准确率
# tf.cast 是类型转换函数
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
for epoch in range(21):
for batch in range(n_batch):
batch_xs, batch_ys = mnist.train.next_batch(batch_size)
sess.run(optimizer, feed_dict={x: batch_xs, y: batch_ys})
acc = sess.run(accuracy, feed_dict={x: mnist.test.images, y: mnist.test.labels})
if epoch % 2 == 0:
print("Iter" + str(epoch) + ",Testing Accuracy" + str(acc))
4、Optimizer优化器和Tensorboard
——前文中,我们将三层全连接神经网络的方差代价函数(二次代价函数)替换成交叉熵函数来完成MNIST数据的分类问题,最终迭代计算20次,准确率接近0.97,离我们预期的0.98甚至0.99还有差距。
这次主要做两个修改:
1)选用合适的优化器进行梯度下降(参考)
2)学习使用tensorboard
TensorFlow的优化器
Tensorflow中包含如下几个优化器:
tf.train.GradientDescentOptimizer
tf.train.AdadeltaOptimizer
tf.train.AdagradOptimizer
tf.train.AdagradDAOptimizer
tf.train.MomentumOptimizer
tf.train.AdamOptimizer
tf.train.FtrlOptimizer
tf.train.ProximalGradientDescentOptimizer
tf.train.ProximalAdagradOptimizer
tf.train.RMSPropOptimizer
其中,
Momerntum:当前权值的改变受到上一次权值改变的影响,类似于小球向下滚动时带上了惯性。这样可以加快小球向下的速度。
NAG:在TF中跟Momentum合并在同一个函数tf.train.MomentumOptimizer中,可以通过参数配置启用。在Momentun中小球会盲目地跟从下坡的梯度,容易发生错误,所以我们需要一个更聪明的小球,这个小球提取知道它要去哪儿,它还要知道走到坡地的时候熟读慢下来而不是又冲上另一个坡,知道下一个位置大概在哪里。从而我们可以提前计算下一个位置的梯度,然后使用到当前位置。
Adagrad:它是基于SGD(随机最速下降法)的一种算法,它的核心思想是对比较常见的数据基于它比较小的学习率去调整参数,对于比较罕见的数据基于它比较大的学习率去调整参数。它很适合应用于稀疏的数据集(比如一个图片数据集,有10000张狗和猫的图片,但只有100张大象的)。Adagrad主要优势在于不需要人为调节学习率,它可以自动调节。但是其缺点在于当迭代次数增多,学习率将会越来越低最终趋于0.
RMSprop:借鉴了一些Adagrad的思想,不过这里RMSprop只用到了前t-1次 梯度平方的均值加上当前梯度的平方的和再开方作为学习率的分母。这样就不会出现学习率越来越低的问题,而且还能自己调节学习率,可以有一个比较好的效果。
Adadelta:我们甚至不需要设置一个默认学习率,在Adadelta不需要使用学习率也可以达到一个非常好的效果。
Adam:像Adadelta和RMSprop一样,Adam会存储之前衰减的平方梯度,同时它也会保存之前衰减的梯度。经过一些处理之后再使用类似Adadelta和RMSprop的方式更新参数。
本文采用的AdamOptimizer,同时会控制学习率的衰减,一开始速度很快,当越接近终点速度越慢。
TensorFlow
——可视化是深度学习神经网络开发、调试。应用中极为重要的手段。当我们使用TensorFlow搭建深层神经网络时,我们希望能够了解整个网络的结构,信息是如何传递的,想了解每次训练后权重值W与偏置值b是如何变化的,损失值、准确率的变化趋势等待。
——使用Google的可视化工具Tensorboard可以帮我们实现上述功能,它可以将模型训练过程中的各种数据汇总起来保存在日志文件里,然后在指定的web端可视化地展现这些信息。
步骤
1、数据准备
2、准备placeholder
这次我们在placeholder中加入了name这项参数,这是为Tensorboard做准备
这里为了刚才说的,实现学习率逐渐衰减的AdamOptimizer,这里我们建一个lr变量,命名为learning_rate,初始值设为0.001
x = tf.placeholder(tf.float32, [None, 784], name='x_input')
y = tf.placeholder(tf.float32, [None, 10], name='y_input')
lr = tf.Variable(0.001, dtype=tf.float32, name='learning_rate')3、初始化参数/权重
这里对所有的权重和偏置也都命上名。
W1 = tf.Variable(tf.truncated_normal([784, 500], stddev=0.1), name='W1')
b1 = tf.Variable(tf.zeros([500]) + 0.1, name='b1')
L1 = tf.nn.tanh(tf.matmul(x, W1) + b1, name='L1')
W2 = tf.Variable(tf.truncated_normal([500, 300], stddev=0.1), name='W2')
b2 = tf.Variable(tf.zeros([300]) + 0.1, name='b2')
L2 = tf.nn.tanh(tf.matmul(L1, W2) + b2, name='L2')
W3 = tf.Variable(tf.truncated_normal([300, 10], stddev=0.1), name='W3')
b3 = tf.Variable(tf.zeros([10]) + 0.1, name='b3')4、计算预测结果
5、计算损失值
6、初始化optimizer
这里我们用 tf.train.AdamOptimizer() 替代 tf.train.GradientDescentOptimizer()
# learning_rate = 0.2
# optimizer = tf.train.GradientDescentOptimizer(learning_rate).minimizer(loss)
optimizer = tf.train.AdamOptimizer(lr).minimize(loss)
# 结果存放在一个布尔型列表中
correct_prediction = tf.equai(tf.argmax(y, 1), tf.argmax(prediction, 1))
# 求准确率
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))7、指定迭代次数,并在session中执行graph
Tensorboard的可视化需要建立一个graph,你想从这个graph中获取某些数据的信息,之后,我们使用tf.summary.FileWriter()将运行后输出的数据文件都保存到本地磁盘(自己设定的文件路径)中。这里选择这个程序文件的同目录下,生成一个graph文件夹,其中又有个名为mnist的文件夹,生成的数据文件将保存在mnist文件夹中。
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
writer = tf.summary.FileWriter('/graphs/mnist',sess.graph)
for epoch in rage(21):
sess.run(tf.assign(lr, 0.001 * (0.95 ** epoch)))
# 这句话是说在实现每次迭代后,学习率逐渐衰减,在最初开始的0.001基础上
# 乘以0.95的迭代次数epoch次幂
for batch in range(n_batch):
batch_xs, batch_ys = mnist.train.next_batch(batch_size)
sess.run(optimizer, feed_dict={x:batch_xs, y:batch_ys})
rest_acc = sess.run(accuracy, feed_dict={x: mnist.test.images, y: mnist.test.labels})
learning_rate = sess.run(lr)
if epoch % 2 ==0:
print("Iter" + str(epoch) + ", Testing accuracy:" + str(test_acc) + ", Learning rate:" + str(learning_rate))
# 每次输出准确率和学习率
writer.close() # 最后记得将写入文件操作关闭 完整代码
# -*- coding:utf-8 -*-
# 安装数据集,第一次执行可能需要下载
import tensorflow.examples.tutorials.mnist.input_data as input_data
mnist = input_data.read_data_sets("MNIST_data/",one_hot=True)
import tensorflow as tf
# 载入数据集
mnist = input_data.read_data_sets("MNIST_data", one_hot=True)
# 每个批次送100张图片
batch_size = 100
# 计算一共有多少个批次
n_batch = mnist.train.num_examples // batch_size
# 准备好placeholder
x = tf.placeholder(tf.float32, [None, 784], name='x_input')
y = tf.placeholder(tf.float32,[None, 10], name='y_input')
lr = tf.Variable(0.001, dtype=tf.float32, name='learning_rate')
# 初始化参数、权重
# 1)隐藏层初始化函数建议使用tf.truncated_normal()(截断的随机数)类型,而非前文的tf.zero()(初始化为0)类型
# 2)中间层的激活函数,本文使用tanh(双曲正切函数),建议使用ReLU函数或者Sigmoid函数,比较一个输出结果
# tf.truncated_normal() 函数从阶段的正态分布中输出随机值
# 函数原型为tf.truncated_normal(shape, mean=0.0, stddev=1.0, dtype=tf.float32, seed=None, name=None)
# 其中stddev是正态分布标准差,seed是一个生成随机数的种子,那么是操作的名字
W1 = tf.Variable(tf.truncated_normal([784, 500], stddev=0.1), name="W1")
b1 = tf.Variable(tf.zeros([500]) + 0.1, name='b1')
L1 = tf.nn.tanh(tf.matmul(x, W1) + b1, name='L1')
W2 = tf.Variable(tf.truncated_normal([500, 300], stddev=0.1),name='W2')
b2 = tf.Variable(tf.zeros([300]) + 0.1, name='b2')
L2 = tf.nn.tanh(tf.matmul(L1, W2) + b2, name='L2')
W3 = tf.Variable(tf.truncated_normal([300, 10], stddev=0.1), name='W3')
b3 = tf.Variable(tf.zeros([10]) + 0.1, name='b3')
# 计算预测结果
prediction = tf.nn.softmax(tf.matmul(L2,W3) + b3)
# 计算损失值
# 先使用二次代价函数
# loss = tf.reduce_mean(tf.square(y - prediction))
# 这里我们使用交叉熵函数替代二次代价函数
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y, logits=prediction))
# 初始化optimizer
# 梯度下降优化器,学习率建议给的稍大些
# learning_rate = 0.2
# optimizer = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss)
optimizer = tf.train.AdamOptimizer(lr).minimize(loss)
# 结果存放在一个布尔型列表中
# tf.argmax(vector,1)意思是返回vector中最大值的索引号,如果vector是一个向量,那就返回一个值
# 如果是一个矩阵就返回一个向量,该向量每一维都是相应矩阵行的最大值元素的索引号
# 在这里,argmax就是返回的就是向量中最大值(1)的位置,并进行比较,相同则返回1,反之为0
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(prediction, 1))# 这里输出的矩阵里面是true和false
# 准确率
# tf.cast 是类型转换函数
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
writer = tf.summary.FileWriter('graphs/mnist/', sess.graph)
for epoch in range(21):
sess.run(tf.assign(lr, 0.001 * (0.95 ** epoch)))
# 这句话是说在实现每次迭代后,学习率逐渐衰减,在最初开始的0.01基础上
# 乘以0.95的迭代次数epoch次幂
for batch in range(n_batch):
batch_xs, batch_ys = mnist.train.next_batch(batch_size)
sess.run(optimizer, feed_dict={x: batch_xs, y:batch_ys})
test_acc = sess.run(accuracy, feed_dict={x: mnist.test.images, y: mnist.test.labels})
learning_rate = sess.run(lr)
if epoch % 2 == 0:
print("Iter" + str(epoch) + ",Testing Accuracy" + str(test_acc) + ", Learning rate:" + str(learning_rate))
writer.close() # 最后记得关闭写入文件操作运行结果
Iter0,Testing Accuracy9513.0, Learning rate:0.001
Iter2,Testing Accuracy9653.0, Learning rate:0.0009025
Iter4,Testing Accuracy9750.0, Learning rate:0.00081450626
Iter6,Testing Accuracy9754.0, Learning rate:0.0007350919
Iter8,Testing Accuracy9778.0, Learning rate:0.0006634204
Iter10,Testing Accuracy9795.0, Learning rate:0.0005987369
Iter12,Testing Accuracy9797.0, Learning rate:0.0005403601
Iter14,Testing Accuracy9804.0, Learning rate:0.000487675
Iter16,Testing Accuracy9814.0, Learning rate:0.00044012666
Iter18,Testing Accuracy9807.0, Learning rate:0.00039721432
Iter20,Testing Accuracy9816.0, Learning rate:0.00035848594可以看到准确率已经升到了98.
记得中间我们做了一些使用tensorboard的准备工作。接下来我们就讲下怎么使用tensorboard。
这里有个坑,就是在打开tensorboard的时候,网上的方法一般是:
先在命令行输入
tensorboard --logdir= D:/TensorFlow/graphs/mnist/ (这里是存放数据的路径,程序中定义的,不加引号)然后过一会儿会生成一个端口,用谷歌会火狐打开就可以看到图
但实际上这样操作只会显示当前目录没有图。
找了好多攻略,都不管用,最后发现一个办法可以。
先在命令行中cd到你存放数据的文件夹的上一级文件夹。然后在这个目录(比如说在D:/TensorFlow/graphs) 里输入
tensorboard --logdir= mnist/再打开他给的地址,就可以看到图了。
5、 TensorBoard可视化界面
前面我们在三层全连接神经网络中使用了学习率随迭代次数增加而衰减的AdamOptimizer优化器来完成MN IST数据的分类问题,最终跌打计算20次,准确率超过0.98,同时掌握了如何写入Graph数据文件,并在Tensorboard查看。
Tensorboard的数据形式
Tensorboard可以记录与展示一下数据形式:
1)标量Scalar
2)图片Imags
3)音频Audio
4)计算图Graph
5)数据分布Distribution
6)直方图Histograms
7)嵌入向量Embeddings
Tensorboard的可视化过程
1)建立一个graph,你想从这个graph中获取某些数据的信息
2)确定要在graph中的那些节点放置summary operations以记录信息
使用 tf.summary.scallar记录标量
使用tf.summary.histogram记录数据的直方图
使用tf.summary.distributuion记录数据的的分布图
使用tf.summary.image记录图像数据
。。。。
3)operations并不会去真的执行计算,除非你告诉他们需要去run,或者它被其他的需要run’的operation所依赖。而我们上一步创建的这些summary operations其实并不被其他节点依赖,因此,我们需要特地去运行所有的summary节点。但是一份程序很多这种节点一个个运行很麻烦,就可用tf.summary.merge_all去将所有summary节点合并成一个节点,只要运行这个节点,就能产生所有我们之前设置的summary data。
4)使用tf.summary.FileWriter将运行后输出的数据都保存到本地磁盘中
5)运行整个程序,并在命令行输入运行tensorboard的指令,之后打开web端可查看可视化的结果
tf.name_scope()函数
复杂的TensorFlow一般由数以千计的节点所构成的,所以难以以下全部看到,甚至无法用标准图表工具来展示。为简单起见,我们为op/tensor名划定范围,并且可视化把该信息用于在图表中的节点上定义一个层级。默认情况下,只有顶层节点会显示。
代码示例
1、数据准备
今天程序上来第一部分就发生变化,出现了新面孔,那就是定义了一个variable_summaries()函数,传递参数为var。
这个函数的作用是:
1)将传递过来的参数var进行求均值(mean)、标准差(stddev)、最大最小值(max、min)
2)用tf.summary.scalar()函数,分别对上述的几个统计量(标量)进行记录,同时记录参数var的直方图(tf.summary.histogram()函数实现)
在这里大家发现了我用的tf.name_scope()函数,我在这里建立一个名叫summaries的可视化节点的层级,之后在Tensorboard中将会找到它。
# 安装数据集,第一次执行可能需要下载
import tensorflow.examples.tutorials.mnist.input_data as input_data
mnist = input_data.read_data_sets("MNIST_data/",one_hot=True)
import tensorflow as tf
# 载入数据集
mnist = input_data.read_data_sets("MNIST_data", one_hot=True)
# 每个批次送100张图片
batch_size = 100
# 计算一共有多少个批次
n_batch = mnist.train.num_examples // batch_size
def variable_summaries(var):
with tf.name_scope('summaries'):
mean = tf.reduce_mean(var)
tf.summary.scalar('mean',mean)
with tf.name_scope('stddev'):
stddev = tf.sqrt(tf.reduce_mean(tf.square(var - mean)))
tf.summary.scalar('stddev',stddev)
tf.summary.scalar('max', tf.reduce_max(var))
tf.summary.scalar('min', tf.reduce_min(var))
tf.summary.histogram('histogram', var)# 直方图
2.准备好placeh
同样,我用tf.name_scope()函数,建立了一个名叫input的可视化节点的层级,这个节点层下包含x_input/y_input、learning_rate 三个子节点。
with tf.name_scope('input'):
x = tf.placeholder(tf.float32, [None, 784], name='x_input')
y = tf.placeholder(tf.float32,[None, 10], name='y_input')
lr = tf.Variable(0.001, dtype=tf.float32, name='learning_rate')3.初始化参数/权重
这里对每个变量都做了同样的操作,只不过这里命名了3个层级的节点,同时对权重W1,W2,W3,偏置值b1,b2,b3进行variable_summaries()函数的调用,想具体了解这些参数在模型训练中是如何变化的。
with tf.name_scope('layer'):
with tf.name_scope('Input_layer'):
with tf.name_scope('W1'):
W1 = tf.Variable(tf.truncated_normal([784, 500], stddev=0.1), name="W1")
variable_summaries(W1)
with tf.name_scope('b1'):
b1 = tf.Variable(tf.zeros([500]) + 0.1, name='b1')
variable_summaries((b1))
with tf.name_scope('L1'):
L1 = tf.nn.tanh(tf.matmul(x, W1) + b1, name='L1')
with tf.name_scope('Hidden layer'):
with tf.name_scope('W2'):
W2 = tf.Variable(tf.truncated_normal([500, 300], stddev=0.1),name='W2')
with tf.name_scope('b2'):
b2 = tf.Variable(tf.zeros([300]) + 0.1, name='b2')
with tf.name_scope('L2'):
L2 = tf.nn.tanh(tf.matmul(L1, W2) + b2, name='L2')
with tf.name_scope('Output_layer'):
with tf.name_scope('W3'):
W3 = tf.Variable(tf.truncated_normal([300, 10], stddev=0.1), name='W3')
with tf.name_scope('b3'):
b3 = tf.Variable(tf.zeros([10]) + 0.1, name='b3')
# 计算预测结果
prediction = tf.nn.softmax(tf.matmul(L2,W3) + b3)4.计算预测结果
5.计算损失值
with tf.name_scope('loss'):
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y, logits=prediction))
tf.summary.scalar('loss',loss)6.初始化optimizer
with tf.name_scope('optimizer'):
optimizer = tf.train.AdamOptimizer(lr).minimize(loss)
with tf.name_scope('train'):
with tf.name_scope('correct_prediction'):
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(prediction, 1))# 这里输出的矩阵里面是true和false
with tf.name_scope('accuracy'):
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
tf.summary.scalar('accuracy', accuracy)7、指定迭代次数,并在session中执行graph
init = tf.global_variables_initializer()
merged = tf.summary.merge_all()
# 将所有的summary节点合并成一个节点,只要运行这个节点,就能产生所有我们之间设置的summary data
with tf.Session() as sess:
sess.run(init)
writer = tf.summary.FileWriter('graphs/mnist/', sess.graph)
# 这个写法是针对mac的,在win下生成的文件读不了?
# writer = tf.summary.FileWriter('graphs/mnist/', tf.get_default_graph())
for epoch in range(21):
sess.run(tf.assign(lr, 0.001 * (0.95 ** epoch)))
# 这句话是说在实现每次迭代后,学习率逐渐衰减,在最初开始的0.01基础上
# 乘以0.95的迭代次数epoch次幂
for batch in range(n_batch):
batch_xs, batch_ys = mnist.train.next_batch(batch_size)
# sess.run(optimizer, feed_dict={x: batch_xs, y:batch_ys})
summary,_ = sess.run([merged, optimizer], feed_dict={x:batch_xs, y:batch_ys})
# 这里我们在tun的时候增加了merged,说明了之前我们设置的节点都不会执行
# 在这里run以后才会把结果反馈给summary
writer.add_summary(summary, epoch)
# 将每次迭代产生的summary写入graph的数据文件中,以便我们在tensorboard中显示出
test_acc = sess.run(accuracy, feed_dict={x: mnist.test.images, y: mnist.test.labels})
learning_rate = sess.run(lr)
if epoch % 2 == 0:
print("Iter" + str(epoch) + ",Testing Accuracy" + str(test_acc) + ", Learning rate:" + str(learning_rate))
writer.close() # 最后记得关闭写入文件操作后面就是和前面讲的一样,打开tensorboard,可以看到自己的数据走势图,直方图,等等。注意Graph 的变化,不再是前面看到的一大堆节点很混乱的样子,而变成了简单的几个元件。将其打开后还可以看到里面的组织结构。
完整代码
# 安装数据集,第一次执行可能需要下载
import tensorflow.examples.tutorials.mnist.input_data as input_data
mnist = input_data.read_data_sets("MNIST_data/",one_hot=True)
import tensorflow as tf
# 载入数据集
mnist = input_data.read_data_sets("MNIST_data", one_hot=True)
# 每个批次送100张图片
batch_size = 100
# 计算一共有多少个批次
n_batch = mnist.train.num_examples // batch_size
def variable_summaries(var):
with tf.name_scope('summaries'):
mean = tf.reduce_mean(var)
tf.summary.scalar('mean',mean)
with tf.name_scope('stddev'):
stddev = tf.sqrt(tf.reduce_mean(tf.square(var - mean)))
tf.summary.scalar('stddev',stddev)
tf.summary.scalar('max', tf.reduce_max(var))
tf.summary.scalar('min', tf.reduce_min(var))
tf.summary.histogram('histogram', var)# 直方图
# 准备好placeholder
with tf.name_scope('input'):
x = tf.placeholder(tf.float32, [None, 784], name='x_input')
y = tf.placeholder(tf.float32,[None, 10], name='y_input')
lr = tf.Variable(0.001, dtype=tf.float32, name='learning_rate')
# 初始化参数、权重
# 1)隐藏层初始化函数建议使用tf.truncated_normal()(截断的随机数)类型,而非前文的tf.zero()(初始化为0)类型
# 2)中间层的激活函数,本文使用tanh(双曲正切函数),建议使用ReLU函数或者Sigmoid函数,比较一个输出结果
# tf.truncated_normal() 函数从阶段的正态分布中输出随机值
# 函数原型为tf.truncated_normal(shape, mean=0.0, stddev=1.0, dtype=tf.float32, seed=None, name=None)
# 其中stddev是正态分布标准差,seed是一个生成随机数的种子,那么是操作的名字
with tf.name_scope('layer'):
with tf.name_scope('Input_layer'):
with tf.name_scope('W1'):
W1 = tf.Variable(tf.truncated_normal([784, 500], stddev=0.1), name="W1")
variable_summaries(W1)
with tf.name_scope('b1'):
b1 = tf.Variable(tf.zeros([500]) + 0.1, name='b1')
variable_summaries(b1)
with tf.name_scope('L1'):
L1 = tf.nn.tanh(tf.matmul(x, W1) + b1, name='L1')
with tf.name_scope('Hidden_layer'):
with tf.name_scope('W2'):
W2 = tf.Variable(tf.truncated_normal([500, 300], stddev=0.1),name='W2')
variable_summaries(W2)
with tf.name_scope('b2'):
b2 = tf.Variable(tf.zeros([300]) + 0.1, name='b2')
variable_summaries(b2)
with tf.name_scope('L2'):
L2 = tf.nn.tanh(tf.matmul(L1, W2) + b2, name='L2')
with tf.name_scope('Output_layer'):
with tf.name_scope('W3'):
W3 = tf.Variable(tf.truncated_normal([300, 10], stddev=0.1), name='W3')
variable_summaries(W3)
with tf.name_scope('b3'):
b3 = tf.Variable(tf.zeros([10]) + 0.1, name='b3')
variable_summaries(b3)
# 计算预测结果
prediction = tf.nn.softmax(tf.matmul(L2,W3) + b3)
# 计算损失值
# 先使用二次代价函数
# loss = tf.reduce_mean(tf.square(y - prediction))
# 这里我们使用交叉熵函数替代二次代价函数
with tf.name_scope('loss'):
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y, logits=prediction))
tf.summary.scalar('loss',loss)
# 初始化optimizer
# 梯度下降优化器,学习率建议给的稍大些
# learning_rate = 0.2
# optimizer = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss)
with tf.name_scope('optimizer'):
optimizer = tf.train.AdamOptimizer(lr).minimize(loss)
# 结果存放在一个布尔型列表中
# tf.argmax(vector,1)意思是返回vector中最大值的索引号,如果vector是一个向量,那就返回一个值
# 如果是一个矩阵就返回一个向量,该向量每一维都是相应矩阵行的最大值元素的索引号
# 在这里,argmax就是返回的就是向量中最大值(1)的位置,并进行比较,相同则返回1,反之为0
with tf.name_scope('train'):
with tf.name_scope('correct_prediction'):
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(prediction, 1))# 这里输出的矩阵里面是true和false
# 准确率
# tf.cast 是类型转换函数
with tf.name_scope('accuracy'):
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
tf.summary.scalar('accuracy', accuracy)
init = tf.global_variables_initializer()
merged = tf.summary.merge_all()
# 将所有的summary节点合并成一个节点,只要运行这个节点,就能产生所有我们之间设置的summary data
with tf.Session() as sess:
sess.run(init)
writer = tf.summary.FileWriter('graphs/mnist/', sess.graph)
# 这个写法是针对mac的,在win下生成的文件读不了?
# writer = tf.summary.FileWriter('graphs/mnist/', tf.get_default_graph())
for epoch in range(21):
sess.run(tf.assign(lr, 0.001 * (0.95 ** epoch)))
# 这句话是说在实现每次迭代后,学习率逐渐衰减,在最初开始的0.01基础上
# 乘以0.95的迭代次数epoch次幂
for batch in range(n_batch):
batch_xs, batch_ys = mnist.train.next_batch(batch_size)
# sess.run(optimizer, feed_dict={x: batch_xs, y:batch_ys})
summary,_ = sess.run([merged, optimizer], feed_dict={x:batch_xs, y:batch_ys})
# 这里我们在tun的时候增加了merged,说明了之前我们设置的节点都不会执行
# 在这里run以后才会把结果反馈给summary
writer.add_summary(summary, epoch)
# 将每次迭代产生的summary写入graph的数据文件中,以便我们在tensorboard中显示出
test_acc = sess.run(accuracy, feed_dict={x: mnist.test.images, y: mnist.test.labels})
learning_rate = sess.run(lr)
if epoch % 2 == 0:
print("Iter" + str(epoch) + ",Testing Accuracy" + str(test_acc) + ", Learning rate:" + str(learning_rate))
writer.close() # 最后记得关闭写入文件操作6、过拟合和Dropout
过拟合
不多解释,应该都懂。说下解决过拟合的常用方法:
1)增加训练数据集
2)正则化
3)Dropout
Dropout
正则化是通过修改代价函数来的,而Dropout 是通过修改神经网络本身来的,它是在训练网络时用的一种技巧。

我们要训练上面这个网络,在训练开始时,我们先随机的“删除”一般隐层单元,视为不存在,得到如下:

保持输入输出层不变,按照BP算法更新上图神经网络的权值(休息连接的单元不更新)。
以上是一次迭代的过程,然后在第二次迭代又用同样方法。它之所以能防止过拟合,在于运用dropout的训练过程,相当于训练了很多个只有半数隐层单元的神经网络(简称“半数网络”),每一个这样的半数网络,都可以给出一个分类结果,这些结果有点对有的错,但是随着训练的进行,大部分半数网络都能给出正确 的结果,那么少数的错误分类结果就不会对最终结果造成太大影响。(这个解释感觉很怪,具体怎么解释也没有定论,更多可见此)
数据示例
1.数据准备
2.准备好placeholder
这里我们需要新建一个placeholder,叫keep_prob,作用是控制实际参与训练的神经元比例,取值范围为0.0-1.0;0.6表示有 60%的神经元参与工作。
with tf.name_scope('input'):
x = tf.placeholder(tf.float32, [None, 784], name='x_input')
y = tf.placeholder(tf.float32,[None, 10], name='y_input')
keep_prob = tf.placeholder(tf.float32, name='keep_prob')
lr = tf.Variable(0.001, dtype=tf.float32, name='learning_rate')3.初始化参数/权重
这里使用tf.nndropout() 函数来实现Dropout,通过keep_prob参数控制
with tf.name_scope('layer'):
with tf.name_scope('Input_layer'):
with tf.name_scope('W1'):
W1 = tf.Variable(tf.truncated_normal([784, 500], stddev=0.1), name="W1")
variable_summaries(W1)
with tf.name_scope('b1'):
b1 = tf.Variable(tf.zeros([500]) + 0.1, name='b1')
variable_summaries(b1)
with tf.name_scope('L1'):
L1 = tf.nn.tanh(tf.matmul(x, W1) + b1, name='L1')
L1_dorp = tf.nn.dropout(L1,keep_prob)
with tf.name_scope('Hidden_layer'):
with tf.name_scope('W2'):
W2 = tf.Variable(tf.truncated_normal([500, 300], stddev=0.1),name='W2')
variable_summaries(W2)
with tf.name_scope('b2'):
b2 = tf.Variable(tf.zeros([300]) + 0.1, name='b2')
variable_summaries(b2)
with tf.name_scope('L2'):
L2 = tf.nn.tanh(tf.matmul(L1_dorp, W2) + b2, name='L2')
L2_drop = tf.nn.dropout(L2, keep_prob)
with tf.name_scope('Output_layer'):
with tf.name_scope('W3'):
W3 = tf.Variable(tf.truncated_normal([300, 10], stddev=0.1), name='W3')
variable_summaries(W3)
with tf.name_scope('b3'):
b3 = tf.Variable(tf.zeros([10]) + 0.1, name='b3')
variable_summaries(b3)4.计算预测结果
5.计算损失值
6.初始化optimizer
7.指定迭代次数,并在session执行graph
既然我们说了过拟合,当然就要涉及到训练集和数据集的 划分。
init = tf.global_variables_initializer()
merged = tf.summary.merge_all()
# 将所有的summary节点合并成一个节点,只要运行这个节点,就能产生所有我们之间设置的summary data
with tf.Session() as sess:
sess.run(init)
writer = tf.summary.FileWriter('graphs/mnist/', sess.graph)
# 这个写法是针对mac的,在win下生成的文件读不了?
# writer = tf.summary.FileWriter('graphs/mnist/', tf.get_default_graph())
for epoch in range(21):
sess.run(tf.assign(lr, 0.001 * (0.95 ** epoch)))
# 这句话是说在实现每次迭代后,学习率逐渐衰减,在最初开始的0.01基础上
# 乘以0.95的迭代次数epoch次幂
for batch in range(n_batch):
batch_xs, batch_ys = mnist.train.next_batch(batch_size)
# sess.run(optimizer, feed_dict={x: batch_xs, y:batch_ys})
summary,_ = sess.run([merged, optimizer], feed_dict={x:batch_xs, y:batch_ys, keep_prob:0.6})
# 这里我们在run的时候增加了merged,说明了之前我们设置的节点都不会执行
# 在这里run以后才会把结果反馈给summary
# 这里讲keep_prob也用字典形式传入
writer.add_summary(summary, epoch)
# 将每次迭代产生的summary写入graph的数据文件中,以便我们在tensorboard中显示出
test_acc = sess.run(accuracy, feed_dict={x: mnist.test.images, y: mnist.test.labels, keep_prob:1.0})
train_acc = sess.run(accuracy, feed_dict={x: mnist.train.images, y:mnist.train.labels, keep_prob:1.0})
# 这里我们分别让它同时运行测试集与训练集,同时输出准确率比较,测试时我们让所有神经元都工作
learning_rate = sess.run(lr)
if epoch % 2 == 0:
print("Iter" + str(epoch) + ",Testing Accuracy" + str(test_acc) + ", Training accuracy:" + str(train_acc))
writer.close() # 最后记得关闭写入文件操作













 729
729











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









