







原理
一、训练中的三个参数定义:
- Epoch:当所有的数据都被前向传播和反向传播一次以后,称为迭代了一次
- Batch-size:一个mini-batch中的个数
- Iteration:进行一次epoch需要迭代多少个Batch-size,即数据集可以分成几份mini-batch。
i t e r a t i o n = a l l t r a i n i n g d a t a b a t c h s i z e iteration= \frac{all \ training \ data}{batch \ size} iteration=batch sizeall training data
二、加载数据集的过程:
- 关于初始数据集加载有两种方法,这两种方法需要再新建的数据类的
__init__中来定义:
(1)在训练之前一次性将所有数据都读到内存里,适用于数据集不那么大(eg:diabetes_dataset)。
(2)将每一条数据的文件名放入一个列表中,例如图像数据。如果标签简单,则直接读到内存里面,若同样复杂,则也将文件名放进一个列表里。 - 小批量的训练过程是两层嵌套循环,如下所示:
#Training cycle
for epoch in range(training_epochs):
#Loop over all batches
for i in range(total_batch):
- 小批量的数据加载使用DataLoader,这是pytorch中一个专门用来加载数据的类。使用方法:
DataLoder(dataset = dataset, batch_size = 2, shuffle = True),这代表将所有数据分成大小为2的mini-batch,并且shuffle = True代表打乱加载顺序。如果是测试数据test_loader,则可以令shuffle = False,这样方便测试。

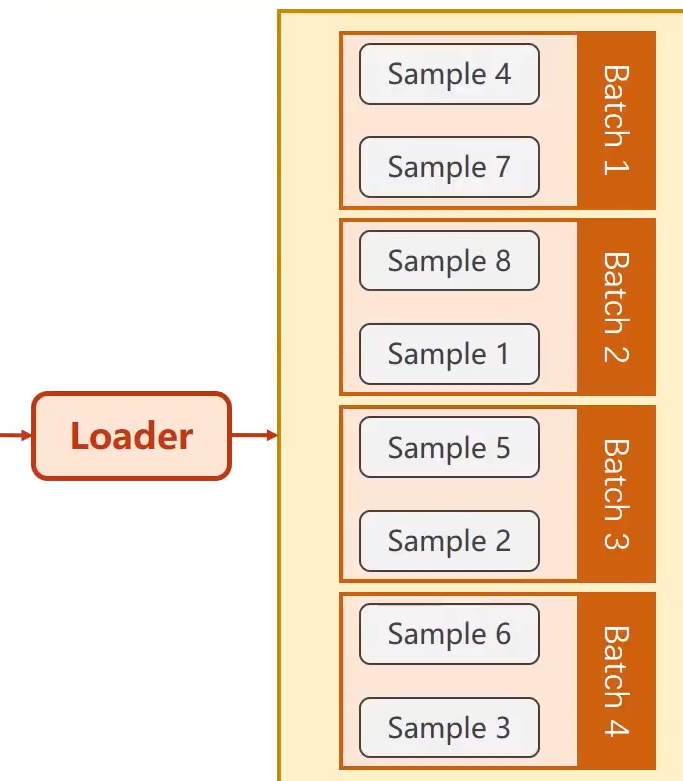
· Dataset类的介绍
可以看到上面使用DataLoader的时候第一个参数是我们的要迭代的数据集,这个数据是需要提前定义的,pytorch中提供了两个类分别用于定义数据集和加载数据集:
- from torch.utils.data import Dataset
- from torch.utils.data import DataLoader
由于Dataset是抽象类,不能实例化,只能被其他的类去继承,所以我们必须重新写一个新的类,例如:
class DiabetesDataset(Dataset): #继承Dataset类
def __init__(self):
pass
def __getitem__(self, index):
pass
def __len__(self):
pass
dataset = DiabetesDataset() #实例化
train_loader = DataLoader(dataset = dataset, batch_size = 32, shuffle = True, num_workers = 2) #再使用ataLoader来加载数据集
其中__getitem__函数用于返回第index个数据,__len__函数用于返回整个数据集的大小,这两个函数通常都会进行重写。
· DataLoader类的介绍
DataLoder则是直接通过torch.utils.data.DataLoader来调用的,不需要继承。它会通过Dataset中的__getitem__来获取对应的数据条并将其组合成batch进行训练。
参数介绍:
- dataset:需要加载的数据集
- batch_size:一个mini_batch的大小
- shuffle:是否打乱顺序
- num_workers:表示是多线程or单线程加载数据
- drop_last:表示是否删除最后一个分配不完整的batch
如果是采用多线程,需要把迭代的过程用if __name__ == '__main__':封装起来,防止代码多次执行。


Tips:在if __name__ == '__main__':下的代码只有在它所处的文件作为脚本直接执行时才会被执行,而 import 到其他python脚本中是不会被执行的。
完整代码及结果
# -*- coding: utf-8 -*-
"""
Created on Mon Aug 15 15:53:02 2022
@author: lg
"""
import numpy as np
import torch
from torch.utils.data import Dataset, DataLoader
class DiabetesDataset(Dataset):
def __init__(self, filepath):
xy = np.loadtxt(filepath, delimiter = ' ', dtype = np.float32)
self.len = xy.shape[0]
self.x_data = torch.from_numpy(xy[:, :-1])
self.y_data = torch.from_numpy(xy[:, [-1]])
def __getitem__(self, index):
return self.x_data[index], self.y_data[index]
def __len__(self):
return self.len
dataset = DiabetesDataset('C:/Users/lg/Anaconda3/Lib/site-packages/sklearn/datasets/data/diabetes_data.csv.gz')
train_loader = DataLoader(dataset,
batch_size = 32,
shuffle = True,
num_workers = 2)
class Model(torch.nn.Module):
def __init__(self):
super(Model,self).__init__()
self.linear1 = torch.nn.Linear(9, 6)
self.linear2 = torch.nn.Linear(6, 4)
self.linear3 = torch.nn.Linear(4, 1)
self.sigmoid = torch.nn.Sigmoid()
def forward(self, x):
x = self.sigmoid(self.linear1(x))
x = self.sigmoid(self.linear2(x))
x = self.sigmoid(self.linear3(x))
return x
model = Model()
criterion = torch.nn.BCELoss(size_average = 'mean')
optimizer = torch.optim.SGD(model.parameters(), lr = 0.01)
if __name__ == '__main__':
for epoch in range(100):
for i, data in enumerate(train_loader, 0):
#1.prepare data
inputs, label = data
#2.forward
y_pred = model(inputs)
loss = criterion(y_pred, label)
print(epoch, i, loss.item())
#3.backward
optimizer.zero_grad()
loss.backward()
#4.update
optimizer.step()
运行结果:
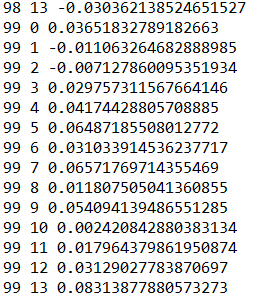














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









