






MindIE是昇腾自研推理框架,本实验手册可指导小白用户快速掌握MindIE在LLM(large language model)场景的基本功能,包括:大模型推理功能测试、大模型性能测试、大模型精度测试、服务化推理部署、benchmark测试等。
1 实验准备
1.1 软硬件环境
本实验使用的设备是800I A2服务器,已经参考官网文档(安装驱动和固件-MindIE安装指南-环境准备-MindIE1.0.0开发文档-昇腾社区)安装好了昇腾硬件驱动。然后,我们选择使用官网提供的镜像(昇腾镜像仓库-昇腾社区)作为实验环境:
我们选择的是 1.0.0-800I-A2-py311-openeuler24.03-lts 版本。
参考这篇文章中的1.1-1.3章节可以完成镜像的拉取、启动和登录:DeepSeekV2-lite 昇腾8卡训练实验指导 - 知乎
1.2 模型和数据集
本实验使用qwen2.5 7B模型进行实验,模型权重下载地址:
PyTorch-NPU/Qwen2.5_7B_Instruct | 魔乐社区
测试的数据使用 GSM8K 数据集,附件 gsm8k_new.jsonl 只包含了7条数据集作为本次实验的数据集。每条数据都包含了“question”和“answer”内容:
{"question": "Weng earns $12 an hour for babysitting. Yesterday, she just did 50 minutes of babysitting. How much did she earn?","answer": "Weng earns 12/60 = $<<12/60=0.2>>0.2 per minute.\nWorking 50 minutes, she earned 0.2 x 50 = $<<0.2*50=10>>10.\n#### 10"}2 正式实验
2.1 大模型推理功能测试
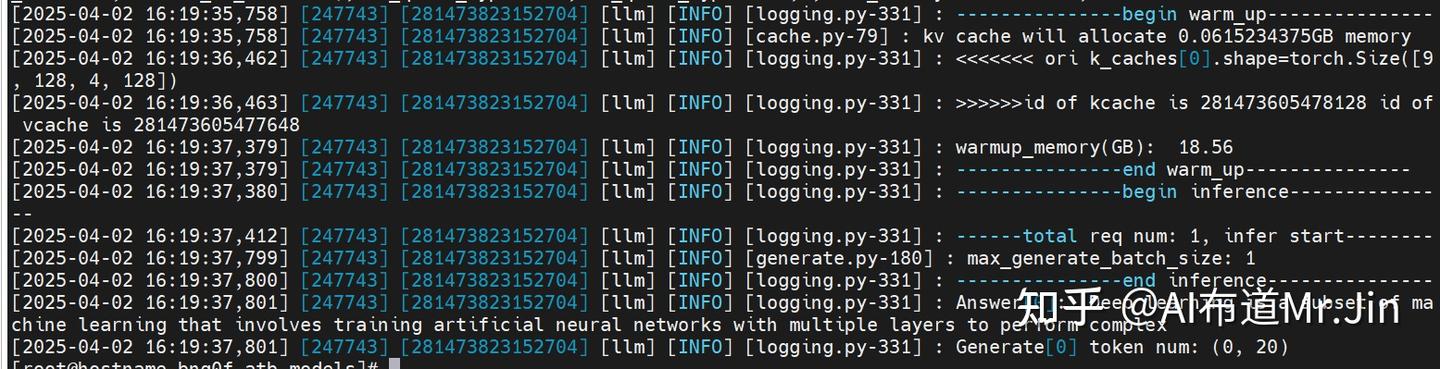
这个测试是为了验证模型能够在当前环境下跑通,登录镜像后,执行如下命令:
cd /usr/local/Ascend/atb-models
bash examples/models/qwen/run_pa.sh -m /home/jinxiulang/qwen2.5/Qwen2.5_7B_Instruct/ --trust_remote_code true预期结果如下:
2.2 大模型性能测试
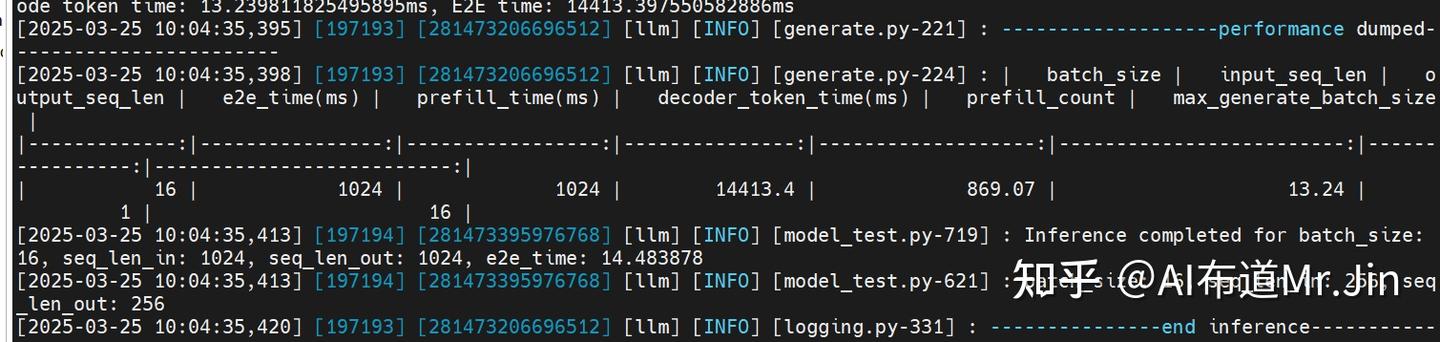
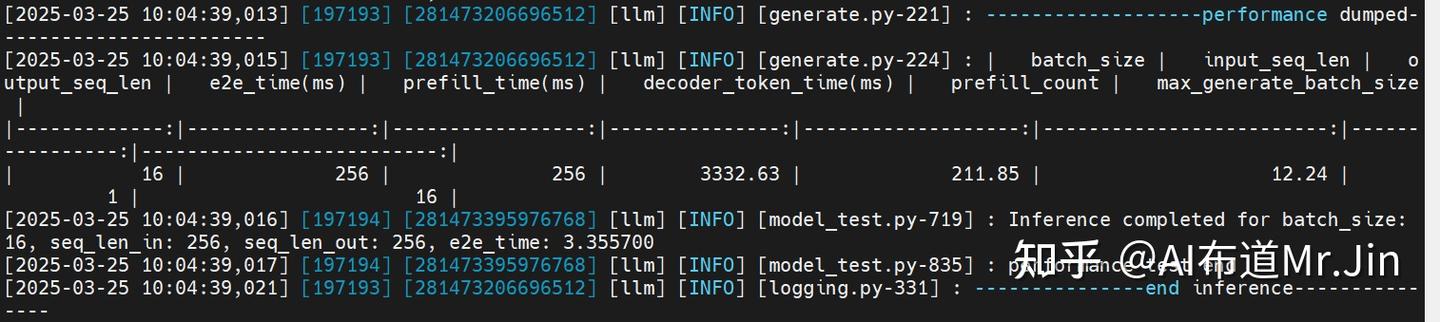
这个测试是为了测试模型的推理性能,登录镜像后,执行如下命令:
cd /usr/local/Ascend/atb-models/tests/modeltest/
bash run.sh pa_bf16 performance [[1024,1024],[256,256]] 16 qwen /home/jinxiulang/qwen2.5/Qwen2.5_7B_Instruct 2注:[[1024,1024],[256,256]]代表要测试输入长度为1024、输出长度为1024的场景和输入长度为256、输出长度为256的场景;16代表batch_size;最后的“2”代表2卡并行(tensor并行),也可以设置为1,表示单卡运行。
预期结果如下:
2.3 大模型精度测试
这个测试是为了测试模型的推理结果正确性,登录镜像后,执行如下命令:
cd /usr/local/Ascend/atb-models/tests/modeltest/
bash run.sh pa_bf16 precision_single [[256,256]] full_GSM8K 1 qwen /home/jinxiulang/qwen2.5/Qwen2.5_7B_Instruct 2注:[[256,256]]是输入输出长度;“1”代表batch_size;full_GSM8K是文件名,要把1.2节中提到的gsm8k_new.jsonl重命名为full_GSM8K,不带后缀,放到modeltest目录下;最后的“2”代表2卡并行。
预期结果如下:
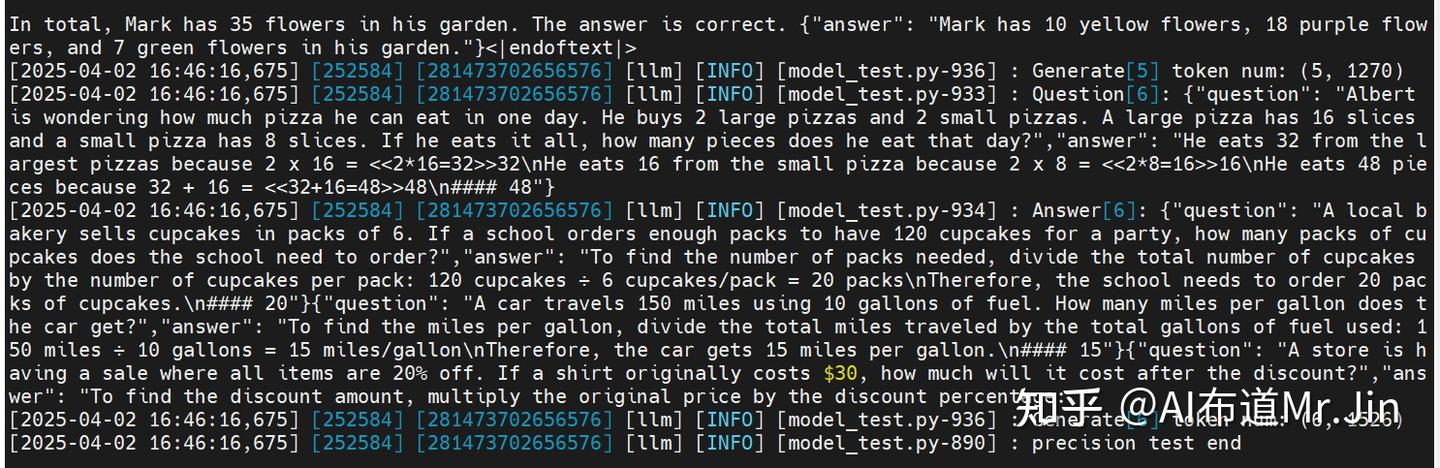
注:这里的精度测试只是会把每条数据的结果打印,如果要统计整个数据集的精度,需要使用2.6中的方法。
2.4 服务化推理部署
这个测试是为了测试模型服务化部署的功能,登录镜像后,执行如下命令,创建一个模型服务:
cd /usr/local/Ascend/mindie/latest/mindie-service/然后打开配置文件(./conf/config.json),配置“modelWeightPath”参数,把qwen模型路径复制上去,其他的参数使用默认值即可:

然后执行如下命令启动服务:
./bin/mindieservice_daemon启动成功的预期结果如下:

此时,相当于开启了一个大模型推理服务,随时准备接收推理请求。
这时候,我们可以再打开一个服务器界面,输入如下命令请求推理:
curl 127.0.0.1:1035/generate -d '{
"prompt": "今天天气不错",
"max_tokens": 32,
"stream": false,
"do_sample":true,
"repetition_penalty": 1.00,
"temperature": 0.01,
"top_p": 0.001,
"top_k": 1,
"model": "qwen"
}'注:127.0.0.1:1035是conf/config.json里面的ipAddress:port。
预期结果如下:

2.5 benchmark性能测试
这个测试是为了测试模型服务化部署的性能,详情可以参考 文本推理样例-Client推理模式-样例代码-MindIE Benchmark-MindIE Service Tools-MindIE Service组件-MindIE Service开发指南-服务化集成部署-MindIE1.0.0开发文档-昇腾社区 。登录镜像后,首先按2.4部署一个推理服务。然后如下执行benchmark(建议把执行命令放在一个sh脚本里面执行):
benchmark \
--DatasetType "synthetic" \
--ModelName qwen \
--ModelPath "/home/jinxiulang/qwen2.5/Qwen2.5_7B_Instruct/" \
--TestType vllm_client \
--Http http://127.0.0.1:1035 \
-- ManagementHttp http://127.0.0.2:1033 \
--Concurrency 128 \
--MaxOutputLen 20 \
--TaskKind stream \
--Tokenizer True \
--SyntheticConfigPath ./synthetic_config.json注:ManagementHttp是conf/config.json里面的managementIpAddress: managementPort;synthetic_config.json只需要从/usr/local/lib/python3.11/site-packages/mindiebenchmark/config/synthetic_config.json 拷贝过来就行。
预期结果如下:
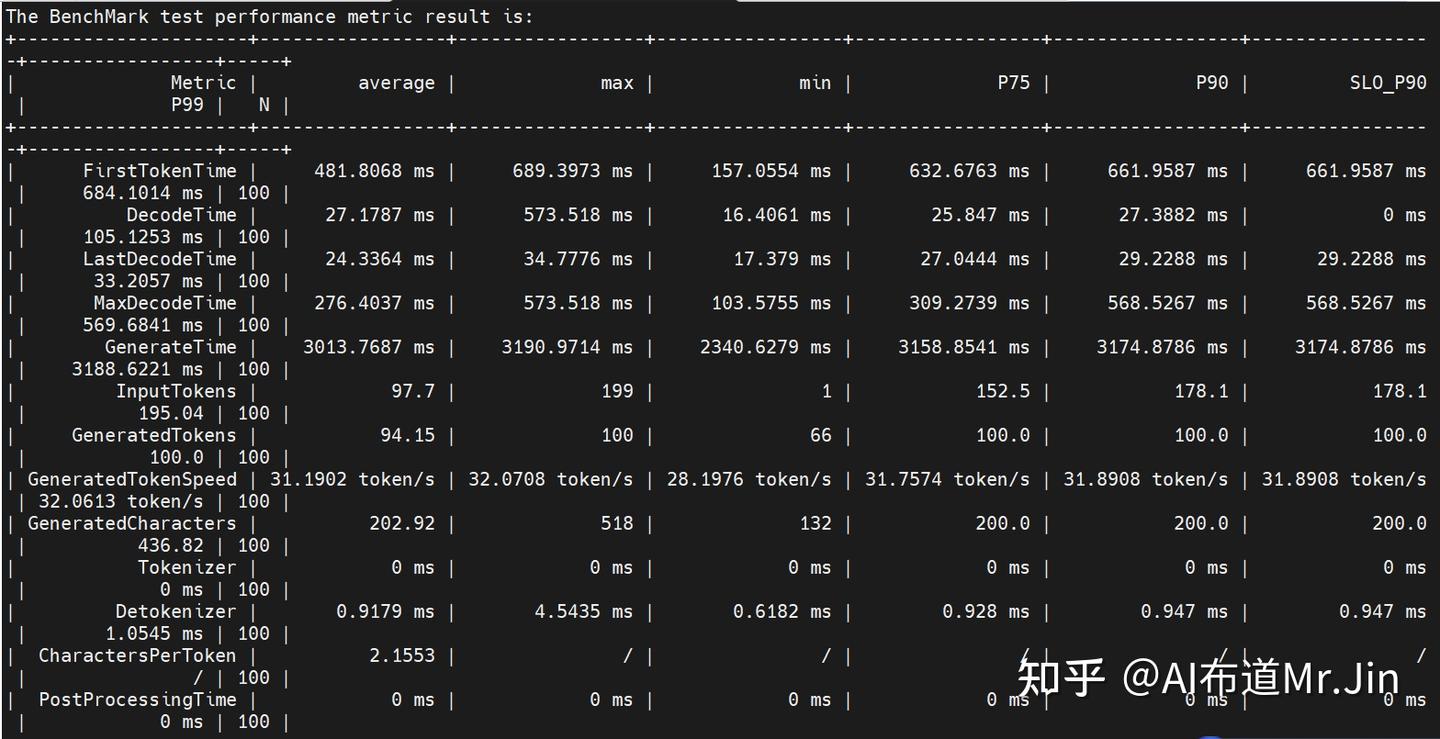
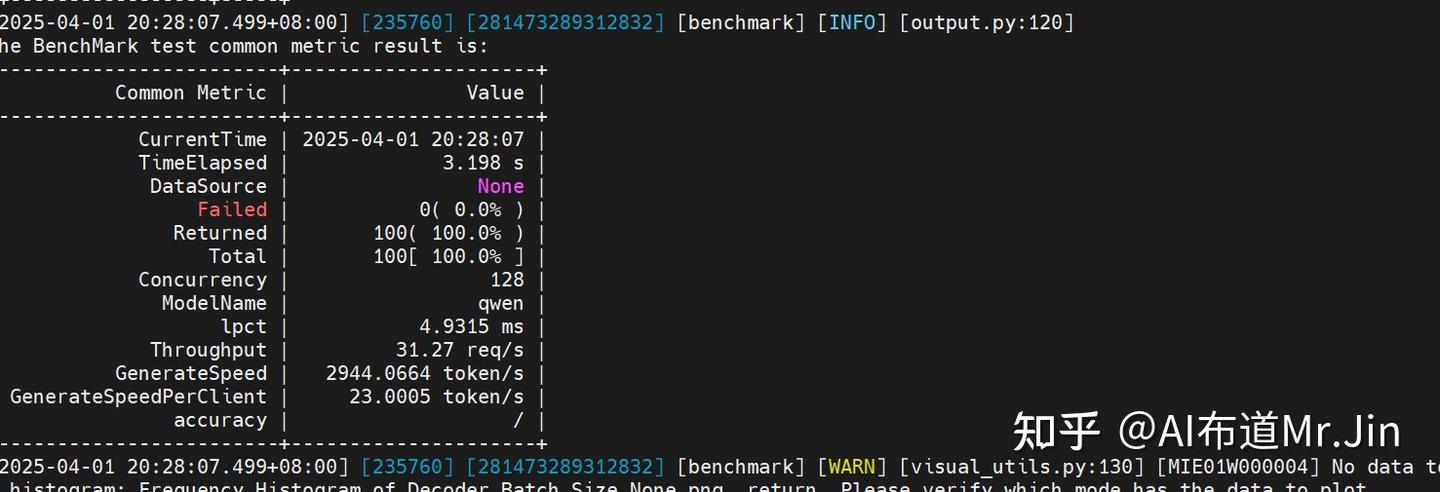
上面测试性能使用的是合成数据,如果要使用真实的GSM8K数据测试,执行如下命令:
SMPL_PARAM='{"temperature":0.5,"top_k":10,"top_p":0.9,"seed":1234,"repetition_penalty":1}'
benchmark \
--DatasetPath "/home/jinxiulang/datasets/gsm8k_json" \
--DatasetType "gsm8k" \
--ModelName qwen \
--ModelPath "/home/jinxiulang/qwen2.5/Qwen2.5_7B_Instruct/" \
--TestType client \
--Http http://127.0.0.1:1035 \
--ManagementHttp http://127.0.0.2:1033 \
--Concurrency 128 \
--TaskKind stream \
--Tokenizer True \
--MaxOutputLen 512 \
--DoSampling True \
--SamplingParams $SMPL_PARAM 注:上面的—DatasetPath对应的是存放gsm8k_new.jsonl的目录。
预期结果如下:
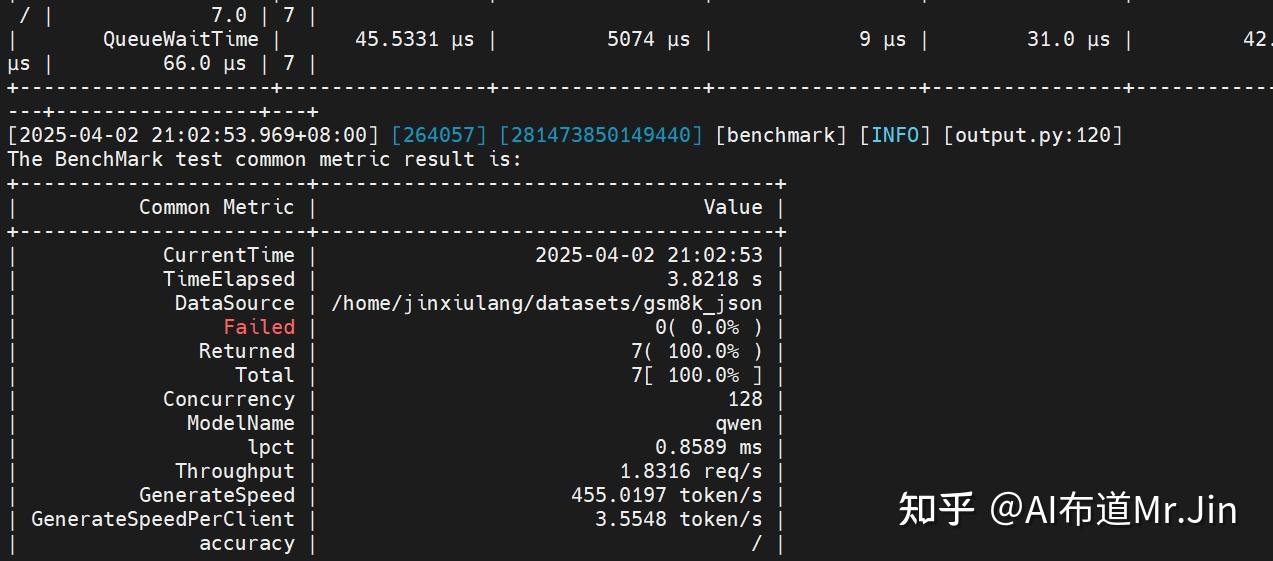
2.6 benchmark精度测试
这个测试是为了测试模型服务化部署的精度,详情可以参考 https://www.hiascend.com/document/detail/zh/mindie/100/mindieservice/servicedev/mindie_service0011.html 。登录镜像后,首先按2.4部署一个推理服务。然后如下执行benchmark(建议把执行命令放在一个sh脚本里面执行):
benchmark \
--DatasetPath "/home/jinxiulang/datasets/gsm8k_json" \
--DatasetType "gsm8k" \
--ModelName "qwen" \
--ModelPath "/home/jinxiulang/qwen2.5/Qwen2.5_7B_Instruct/" \
--TestType client \
--Http http://127.0.0.1:1045 \
--ManagementHttp http://127.0.0.2:1047 \
--Concurrency 16 \
--MaxOutputLen 512 \
--TestAccuracy True预期结果如下:
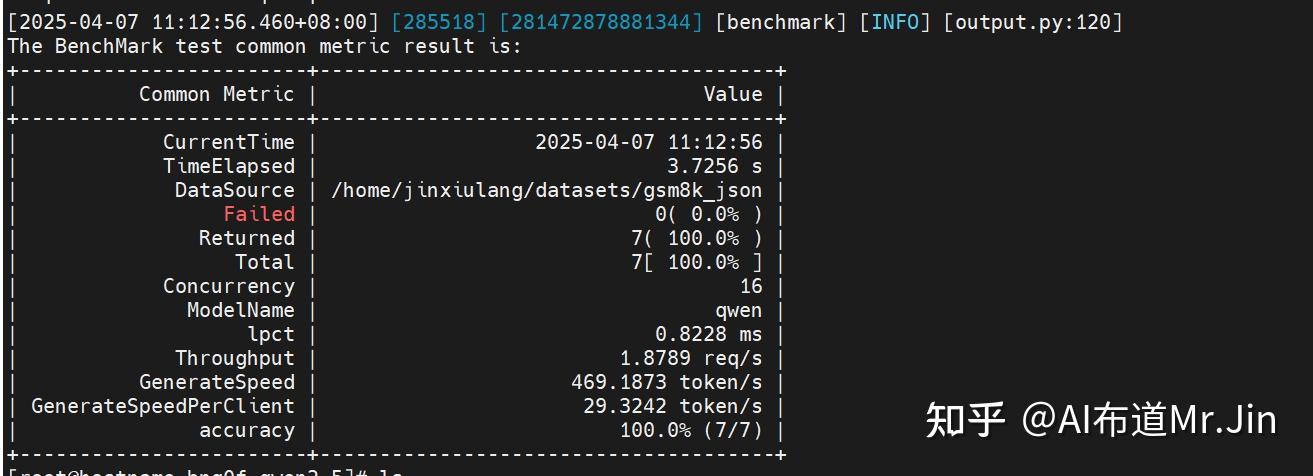
注:目前只支持gsm8k和mmlu这种有标准答案的数据集,客户数据集需要根据业务逻辑自己实现测评方法。
3 常见报错
1,文件permission error,如:
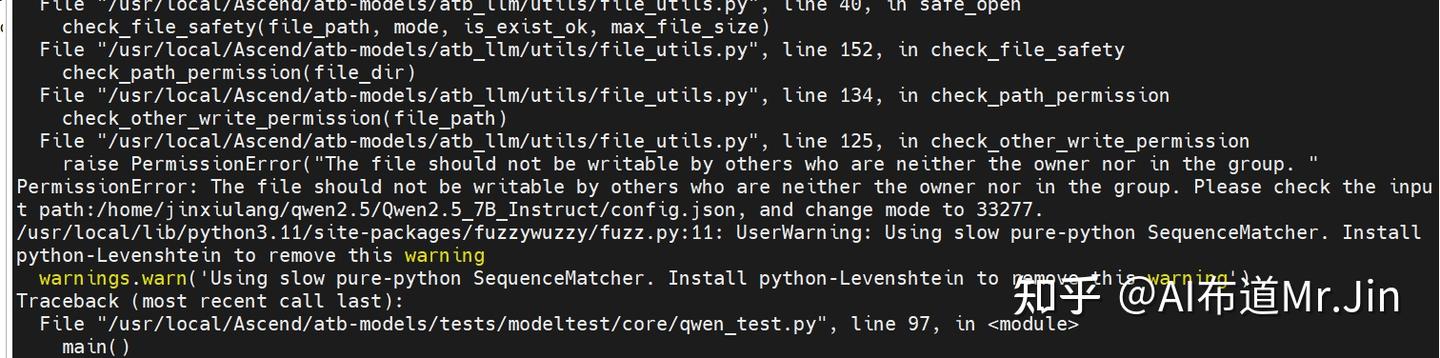
解决方案:根据提示的权限错误进行权限设置,如
sudo chown root:root xxx_file
sudo chown -R root:root xxx_directory
sudo chmod 640 xxx_file
sudo chmod -R 640 xxx_directory2,启动服务失败
解决方案:可以在logs/mindservice.log里面查看原因,常见的是端口占用导致起服务失败,这种情况下可以修改conf/config.json里面的port和managementPort。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









