






 本文提出了一种使用最大熵模型进行英汉命名实体对齐的新方法,通过bootstrapping技术辅助监督学习。与传统方法不同,该方法在不进行分词的情况下对纯文本进行对齐,减少了错误传播,提高了性能。实验结果显示,该方法优于IBM Model 4和HMM模型。主要特征包括翻译得分、音译得分、共现分数和变形分数。
本文提出了一种使用最大熵模型进行英汉命名实体对齐的新方法,通过bootstrapping技术辅助监督学习。与传统方法不同,该方法在不进行分词的情况下对纯文本进行对齐,减少了错误传播,提高了性能。实验结果显示,该方法优于IBM Model 4和HMM模型。主要特征包括翻译得分、音译得分、共现分数和变形分数。
A New Approach for English-Chinese Named Entity Alignment(英汉实体对齐新方法)
0 Abstract
传统的词对齐方法不能为实体提供令人满意的结果。在本文中,我们提出了一种使用最大熵模型进行命名实体对齐的新方法。为了简化最大熵模型的训练,使用bootstrapping法来帮助监督学习。与以往文献报道的工作不同,我们的工作对中文进行了无分词的双语命名实体对齐,其性能比有分词的好得多。实验结果表明,与IBM模型和HMM对齐模型相比,我们的方法显著优于IBM模型4和HMM。
1 Introduction
本文讨论了双语语料库的命名实体对齐问题,即在目标语言中建立每个源语言NE与其翻译NE之间的对齐。研究表明,命名实体(NE)在人类语言中携带了必要的信息。对齐双语命名实体是提取实体翻译列表和翻译模板的有效方法。例如,在下面的句子对中,对齐NE,[Zhi Chun road]和[知春路] 能够正确生成翻译模板。
- Can I get to [LN Zhi Chun road] by eight o’clock?
- 八点我能到 [LN 知春路]吗?
此外,NE对齐对于统计机器翻译(SMT)和跨语言信息检索(CLIR)非常有用。
但是,命名实体对齐不容易获得。它要求正确处理命名实体识别(NER)和对齐。NE可能无法很好地识别,或者在NER期间只能识别其中的一部分。在用不同语言对齐双语NE时,我们需要处理多对多对齐。不同语言的NE翻译和NER的不一致也是一个大问题。具体而言,在中文NE处理中,由于中文不是标记化语言,以前的工作通常进行分词并依次识别命名实体。这涉及到中文NE的几个问题,例如分词错误、中文NE边界的识别以及中文NE的错误标记。例如,”国防部长” 在中文里,它实际上是一个单位,不应该被分割成[ON 国防部]/长。分词和NER产生的错误将传播到NE对齐。
本文提出了一种利用最大熵模型进行英汉命名实体对齐的新方法。NER工具首先识别英语中的NE。然后,我们研究NE翻译特征以识别中文中的NE,并确定最可能的对齐方式。为了简化最大熵模型的训练,使用 bootstrapping 技术来帮助监督学习。
另一方面,为了避免分词和NER的错误传播,我们直接提取中文NE,并在没有分词的情况下对纯文本进行对齐。这与文献中以前报道的工作不同。虽然这使任务变得更加困难,但它大大减少了前面步骤引入错误的机会,从而在任务中产生更好的性能。
为了证明我们的方法的合理性,我们采用了传统的对齐方法,特别是IBM Model 4和HMM,以执行NE对齐作为我们的基线系统。实验结果表明,在这个任务中,我们的方法明显优于IBM Model 4和HMM。此外,不使用分词的性能要比使用分词的性能好得多。
本文的其余部分组织如下:在第2节中,我们讨论了NE对齐的相关工作。第3节给出了NE校准的总体框架和我们的最大熵模型。本节还介绍了功能部件功能和引导过程。我们在第4节展示了实验结果,并将其与基线系统进行了比较。第5节总结了本文,并讨论了正在进行的未来工作。
2 相关工作
通过单词和短语对齐可以获得翻译知识。迄今为止,在机器翻译和知识获取领域进行了大量研究,包括统计方法和符号方法。
然而,这些方法不能很好地用于NE对齐任务。遵循IBM模型的传统方法无法产生令人满意的结果,因为它们本身无法处理多对多对齐。他们只执行单词之间的对齐,不考虑复杂词组的情况,比如一些多词NE。另一方面,IBM模型允许源语言中最多有一个单词对应目标语言中的一个单词。因此,它们不能很好地处理NE中的多对多单词对齐。另一种众所周知的单词对齐方法HMM使得对齐概率取决于前一个单词的对齐位置。它也没有明确地考虑多对多的对齐方式。
Huang等人提出了基于线性组合多特征代价最小化的命名实体跨语言等价性提取方法。但是,它们需要在源端和目标端识别命名实体。Moore的方法基于一系列成本模型,然而,这种方法在很大程度上依赖于语言信息,例如两侧重复的字符串,以及来自大写字母的线索,这些线索不适用于不具备同一属性的语言对。此外,目标端已经确定了完整的词汇复合词,它们代表了最终结果的很大一部分。在对齐过程中,Moore没有假设短语的翻译需要在目标集上拆分预定的词汇复合词。
这些方法不适合我们的任务,因为我们只在源端识别了NE,而目标端没有额外的知识。考虑到NE翻译的固有特征,我们可以找到几个有助于NE对齐的特征;因此,我们使用最大熵模型来整合这些特征并进行NE对齐。
3 最大熵模型的NE对齐
在不依赖英文或中文的语法知识的情况下,我们发现有几个有价值的特性可以用于命名实体对齐。考虑到最大熵模型在整合不同类型特征方面的优势,我们使用该框架来处理我们的问题。
假设源英语NE
n
e
e
ne_e
nee,
n
e
e
=
{
e
1
,
e
2
,
⋯
,
e
n
}
ne_e = \{ e_1, e_2, \cdots, e_n\}
nee={e1,e2,⋯,en},包含
n
n
n 个英文单词,候选中文NE
n
e
c
ne_c
nec,
n
e
c
=
{
c
1
,
c
2
,
⋯
,
c
n
}
ne_c = \{ c_1, c_2, \cdots, c_n \}
nec={c1,c2,⋯,cn} 由
m
m
m 个汉字组成。假设我们有
M
M
M 个特征函数
h
m
(
n
e
e
,
n
e
c
)
,
m
=
1
,
⋯
,
M
h_m(ne_e, ne_c), m = 1, \cdots, M
hm(nee,nec),m=1,⋯,M,对于每个特征函数,我们有一个模型参数
λ
m
,
m
=
1
,
⋯
,
M
\lambda_m, m = 1, \cdots, M
λm,m=1,⋯,M,对齐概率定义如下:
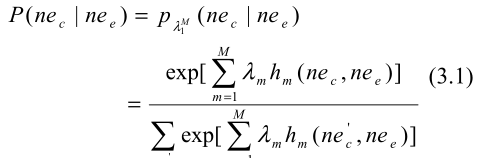
选择英文NE中最可能对齐的目标NE的决策规则为:
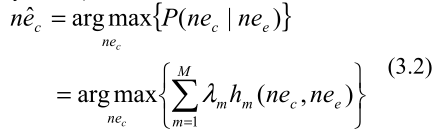
在我们的方法中,考虑到NE翻译的特点,我们采用4个特征:翻译得分、音译分数、源NE和目标NE的共现分数、区分同一句子中相同NE的失真分数。接下来,我们将详细讨论这四个特性。
3.1 功能函数
3.1.1 翻译得分
考虑英语NE中单词与汉语NE中字符之间的翻译概率是很重要的。在处理无分割的汉语句子时,这里的词是指单个汉字。
此处的翻译分数用于表示基于翻译概率的实体对的接近程度。假设源英语NE
n
e
e
ne_e
nee 由
n
n
n 个英语单词组成:
n
e
e
=
{
e
1
,
e
2
,
⋯
,
e
n
}
ne_e = \{ e_1, e_2, \cdots, e_n\}
nee={e1,e2,⋯,en},候选中文NE
n
e
c
ne_c
nec,
n
e
c
=
{
c
1
,
c
2
,
⋯
,
c
n
}
ne_c = \{ c_1, c_2, \cdots, c_n \}
nec={c1,c2,⋯,cn} 由
m
m
m个汉字组成,我们可以根据
e
i
e_i
ei 和
c
j
c_j
cj 之间的翻译概率得到这两个双语NE的翻译分数:
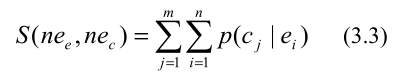
给定一个在句子层面对齐的平行语料库,我们可以获得每个英语单词和每个汉字之间的翻译概率
p
(
c
j
∣
e
i
)
p(c_j | e_i )
p(cj∣ei)(通过与IBM Model 1的单词对齐)。在没有分词的情况下,我们必须计算每个可能的候选词来确定最可能的对齐,这将使搜索空间非常大。因此,我们对整个搜索空间进行修剪。如果在两个相邻字符之间有一个分数跳变,候选字符将被丢弃。通过该公式计算候选中文NE与源英文NE之间的分数,作为该特征的值。
3.1.2 音译得分
虽然在理论上,翻译分数可以在正确的NE对齐中建立关系,但在实践中并非总是如此,这是由于语料库的特点。当我们有稀疏的数据时,这一点更加明显。例如,“命名实体”中的大多数人名在语料库中分布很稀疏,没有规律地重复。除此之外,一些英文NE也通过音译翻译而不是语义翻译。因此,建立音译模型是非常重要的。
给定一个英文实体
e
e
e,
e
=
{
e
1
,
e
2
,
⋯
,
e
n
}
e = \{ e_1, e_2, \cdots, e_n\}
e={e1,e2,⋯,en},将
e
e
e 音译为中文命名实体
c
c
c ,
c
=
{
c
1
,
c
2
,
⋯
,
c
n
}
c = \{ c_1, c_2, \cdots, c_n \}
c={c1,c2,⋯,cn} 的过程,可以用式(3.4)来描述(为便于表示,这里用
e
e
e 和
c
c
c 代替
n
e
e
ne_e
nee 和
n
e
c
ne_c
nec 来表示英文NE和中文NE)。

根据贝叶斯规则,可将其转换为:
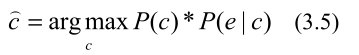
由于有超过6k个常用汉字,我们需要一个非常大的训练语料库来直接建立英语单词和汉字之间的映射。我们采用了古罗马化系统,汉语拼音,以便于转换。每个汉字对应一个汉语拼音字符串。从汉字到拼音字符串的概率为
P
(
r
∣
c
)
≈
1
P(r | c) ≈ 1
P(r∣c)≈1,除了多音字。因此,我们:
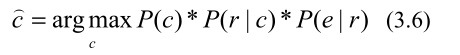
我们的问题是:给定英文NE和候选中文NE,找到最可能的对齐,而不是找到最可能的英文NE的中文翻译。因此,与以前的英汉音译模型工作不同,我们将每个候选的中文NE转换为汉语拼音串,并直接训练一个基于拼音的语言模型,该语言模型包含由1258个名字对组成的独立英汉名单,从英文NE中解码出最可能的拼音串。
为了从英文NE中找到最可能的拼音串,我们将公式(3.5)改写如下:
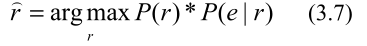
其中r表示罗马拼音(拼音字符串),
r
=
{
r
1
,
r
2
,
⋯
,
r
m
}
r = \{ r_1, r_2, \cdots, r_m\}
r={r1,r2,⋯,rm}。对于每一个因子,有:
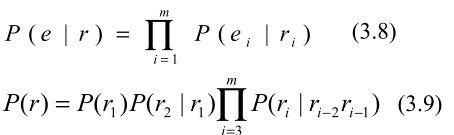
其中
e
i
e_i
ei 是一个英语音节,
r
i
r_i
ri 是一个汉语拼音子串。
例如,我们有英文NE “Richard” 和其候选中文NE ”理查德” 。由于通道模型和语言模型都是基于拼音的,维特比解码的结果是从“Ri char d”到“Li Cha De”。我们将“理查德” 转换为拼音串“Li Cha De”。然后,我们基于拼音字符串而不是直接与汉字进行相似度比较。这是因为在将英语NE音译为汉语时,可以非常灵活地选择哪个字符来模拟发音,但拼音字符串相对固定。
对于每个英语单词,有几种方法可以将其划分为音节,因此本文采用动态规划算法将英语单词解码为汉语拼音序列。基于英文NE的音译字符串和原始候选中文NE的拼音字符串,我们可以计算它们与XDice系数的相似性。这是Dice系数的一个变体,它允许“扩展的二元图”。扩展双字元(xbig)是在原有双字元的基础上,从单词的任何三个字母子串中删除中间字母而形成的。
假设英语NE的音译字符串和候选汉语NE的拼音字符串分别为
e
t
l
e_{tl}
etl 和
c
p
y
c_{py}
cpy。XDice系数通过以下公式计算:
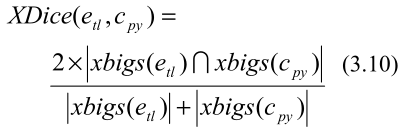
另一点需要注意的是,外国人名和中国人名有不同的翻译策略。上述音译框架仅适用于外国名称。对于中文人名翻译,表面的英文字符串就是中文人名的拼音字符串。为了处理这两种情况,请确保表示表层英语字符串,通过取两个XDice系数的最大值来定义最终的音译分数:

此公式不区分外国人姓名和中国人姓名,外国人姓名的音译字符串或中国人姓名的拼音字符串可以适当处理。此外,由于英文字符串和拼音字符串共享同一个字符集,如果音译解码失败,我们的方法也可以作为替代方法。
例如,对于英文名称“Cuba”,与中文NE的对齐应为“古巴”。如果音译解码失败,其拼音串“Guba”仍然通过XDice系数与表面串“Cuba”有很强的关系。这可以使系统更强大。
3.1.3 共现分数
另一种方法是在整个语料库中找到源和目标NE的共现。如果两个NE经常同时出现,那么它们很有可能相互对齐。从整个语料库中获取的知识对于NE对齐来说是一个额外且有价值的特征。我们使用以下公式计算源英语NE和候选汉语NE的共现分数:
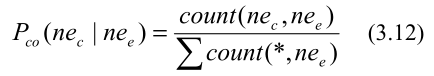
式中,
c
o
u
n
t
(
n
e
c
,
n
e
e
)
count(ne_c, ne_e)
count(nec,nee) 是
n
e
c
ne_c
nec 和
n
e
e
ne_e
nee 同时出现的次数,
c
o
u
n
t
(
∗
,
n
e
e
)
count(*,ne_e)
count(∗,nee),是
n
e
e
ne_e
nee 出现的次数。这一概率是一个很好的指示,用于确定是否对齐。
3.1.4 变形分数
当跨语言翻译NE时,我们注意到它们位置的差异也是确定它们关系的一个很好的指示,当目标语言中有相同的候选者时,这是必须的。差异越大,它们相互翻译的可能性就越小。因此,我们将源英语NE和候选汉语NE之间的变形分数定义为另一个特征。
假设英语NE的起始位置的索引为
i
i
i,英语句子的长度为
m
m
m。然后我们得到了源英语NE 的相对位置
p
o
s
e
=
i
m
pos_e=\dfrac{i}{m}
pose=mi ,以及候选中文NE的相对位置
p
o
s
c
pos_c
posc,
0
≤
p
o
s
c
,
p
o
s
c
≤
1
0≤pos_c,pos_c ≤1
0≤posc,posc≤1。变形分数由以下公式定义:
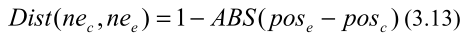
式中,
A
B
S
ABS
ABS 表示绝对值。如果目标语言中的不同位置有多个相同的候选中文NE,则变形分数最大的将获胜。
3.2 使用最大熵模型进行bootstrapping训练
为了将最大熵模型应用于NE对齐,我们分两步进行:选择NE候选对象和训练最大熵模型参数。
3.2.1 NE候选者选择
为了与我们的最大熵模型保持一致,我们首先使用NLPWIN识别英语中的命名实体。对于识别出的NE中的每个单词,我们通过从IBM Model 1获取的翻译表找到所有可能的中文翻译字符。最后,我们将所有选择的字符作为“种子”数据。由于每个种子都有一个开放的窗口,因此窗口内的所有可能序列都被视为NE比对的可能候选序列。它们的长度范围从1到根据经验确定的窗口长度。在候选选择过程中,采用上述剪枝策略来减少搜索空间。
例如,在图1中,如果“China”的翻译概率仅超过阈值,则为“中”, 这两个种子数据位于索引为0和4的位置。假设窗口长度为3,则种子数据周围的所有长度范围为1到3的候选项,包括“中国”,将被选择为候选项。

3.2.2 最大熵模型参数训练
利用第3.1节中定义的四个特征函数,我们计算了所有选定的中文NE候选者的特征分数。
为了获得最可能对齐的汉语NE,我们使用已发布的包YASMET对所有NE候选进行参数训练和重新排序。YASMET需要监督学习来训练最大熵模型。然而,获得一个大的带注释的训练集并不容易。在这里,bootstrapping 用于帮助该过程。图2给出了参数训练的整个过程。
- 将系数 λ i \lambda_i λi 设置为均匀分布;
- 计算所有特征得分,得到汉语NE候选的N-best列表;
- 认为得分超过给定阈值的候选词是正确的,并将其放入重新排序的训练集中;
- 使用YASMET重新训练参数 λ i \lambda_i λi;
- 重复步骤2,直到 λ i \lambda_i λi 收敛,并将当前排名作为最终结果。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









