






简介
粒子群优化算法(Particle Swarm optimization,PSO)又翻译为粒子群算法、微粒群算法、或微粒群优化算法。是通过模拟鸟群觅食行为而发展起来的一种基于群体协作的随机搜索算法。通常认为它是群集智能 (Swarm intelligence, SI) 的一种。它可以被纳入多主体优化系统(Multiagent Optimization System, MAOS).粒子群优化算法是由Eberhart博士和kennedy博士发明。
算法原理
PSO初始化为一群随机粒子(随机解),然后通过迭代找到最优解,在每一次叠代中,粒子通过跟踪两个“极值”来更新自己。第一个就是粒子本身所找到的最优解,这个解叫做个体极值pBest,另一个极值是整个种群找到的最优解,这个极值是全局极值gBest。另外也可以不用整个种群而只是用其中一部分最优粒子的邻居,那么在所有邻居中的极值就是局部极值。
在找到这两个最优值时,粒子根据如下的公式来更新自己的速度和新的位置
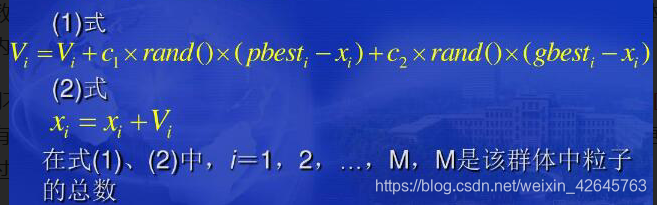
以上面两个公式为基础,形成了PSO的标准形式。

公式(2)和 公式(3)被视为标准PSO算法。
- 如果令c1=c2=0,粒子将一直以当前速度的飞行,直到边界。很难找到最优解。
- 如果=0,则速度只取决于当前位置和历史最好位置,速度本身没有记忆性。假设一个粒子处在全局最好位置,它将保持静止,其他粒子则飞向它的最好位置和全局最好位置的加权中心。粒子将收缩到当前全局最好位置。在加上第一部分后,粒子有扩展搜索空间的趋势,这也使得的作用表现为针对不同的搜索问题,调整算法的全局和局部搜索能力的平衡。较大时,具有较强的全局搜索能力;较小时,具有较强的局部搜索能力。
- 通常设c1=c2=2。Suganthan的实验表明:c1和c2为常数时可以得到较好的解,但不一定必须等于2。
基本流程
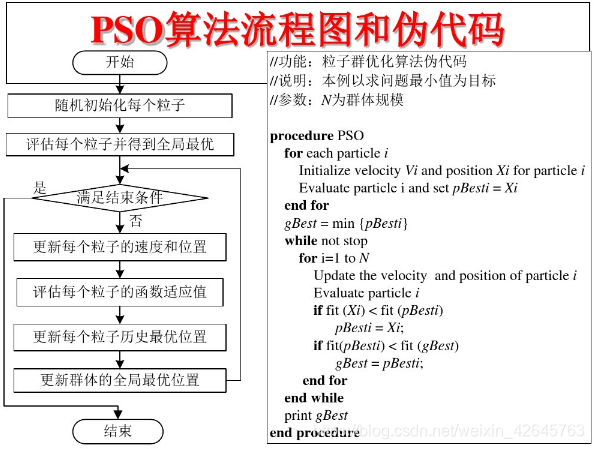
标准PSO算法的流程:
1)初始化一群微粒(群体规模为N),包括随机位置和速度;
2)评价每个微粒的适应度;
3)对每个微粒,将其适应值与其经过的最好位置pbest作比较,如果较好,则将其作为当前的最好位置pbest;
4)对每个微粒,将其适应值与其经过的最好位置gbest作比较,如果较好,则将其作为当前的最好位置gbest;
5)根据公式(2)、(3)调整微粒速度和位置;
6)未达到结束条件则转第2)步。
迭代终止条件根据具体问题一般选为最大迭代次数Gk或(和)微粒群迄今为止搜索到的最优位置满足预定最小适应阈值。
重要参数
c1、c2 %加速因子
w %惯性权重
sizepop %种群规模
dim %适应度函数维数
代码展示
wchange,c1change,c2change
%ws=0.9
%we=0.4
%c1s=2; c1e=1;
%c2s=2; c2e=1;
%c1=c1s-(c1s-c1e)*(i/maxgen);
%c2=c2s-(c2s-c2e)*(i/maxgen);
%w=ws-(ws-we)*(i/maxgen);
PSO.m
%% 清空环境
clc
clear
%% 参数初始化
%粒子群算法中的三个参数
c1 = 1.49445;%加速因子
c2 = 1.49445;
w=0.8 %惯性权重
maxgen=1000; % 进化次s数
sizepop=200; %种群规模
Vmax=1; %限制速度围
Vmin=-1;
popmax=5; %变量取值范围
popmin=-5;
dim=10; %适应度函数维数
func=1; %选择待优化的函数,1为Rastrigin,2为Schaffer,3为Griewank
Drawfunc(func);%画出待优化的函数,只画出二维情况作为可视化输出
%% 产生初始粒子和速度
for i=1:sizepop
%随机产生一个种群
pop(i,:)=popmax*rands(1,dim); %初始种群
V(i,:)=Vmax*rands(1,dim); %初始化速度
%计算适应度
fitness(i)=fun(pop(i,:),func); %粒子的适应度
end
%% 个体极值和群体极值
[bestfitness bestindex]=min(fitness);
gbest=pop(bestindex,:); %全局最佳
pbest=pop; %个体最佳
fitnesspbest=fitness; %个体最佳适应度值
fitnessgbest=bestfitness; %全局最佳适应度值
%% 迭代寻优
for i=1:maxgen
fprintf('第%d代,',i);
fprintf('最优适应度%f\n',fitnessgbest);
for j=1:sizepop
%速度更新
V(j,:) = w*V(j,:) + c1*rand*(pbest(j,:) - pop(j,:)) + c2*rand*(gbest - pop(j,:)); %根据个体最优pbest和群体最优gbest计算下一时刻速度
V(j,find(V(j,:)>Vmax))=Vmax; %限制速度不能太大
V(j,find(V(j,:)<Vmin))=Vmin;
%种群更新
pop(j,:)=pop(j,:)+0.5*V(j,:); %位置更新
pop(j,find(pop(j,:)>popmax))=popmax;%坐标不能超出范围
pop(j,find(pop(j,:)<popmin))=popmin;
if rand>0.98 %加入变异种子,用于跳出局部最优值
pop(j,:)=rands(1,dim);
end
%更新第j个粒子的适应度值
fitness(j)=fun(pop(j,:),func);
end
for j=1:sizepop
%个体最优更新
if fitness(j) < fitnesspbest(j)
pbest(j,:) = pop(j,:);
fitnesspbest(j) = fitness(j);
end
%群体最优更新
if fitness(j) < fitnessgbest
gbest = pop(j,:);
fitnessgbest = fitness(j);
end
end
yy(i)=fitnessgbest;
end
%% 结果分析
figure;
plot(yy)
title('最优个体适应度','fontsize',12);
xlabel('进化代数','fontsize',12);ylabel('适应度','fontsize',12);
Rastrigin.m
function y = Rastrigin(x)
% Rastrigin函数
% 输入x,给出相应的y值,在x = ( 0 , 0 ,…, 0 )处有全局极小点0.
% 编制人:
% 编制日期:
[row,col] = size(x);
if row > 1
error( ' 输入的参数错误 ' );
end
y =sum(x.^2-10*cos(2*pi*x)+10);
%y =-y;
Schaffer.m
function y=Schaffer(x)
[row,col]=size(x);
if row>1
error('输入的参数错误');
end
y1=x(1,1);
y2=x(1,2);
temp=y1^2+y2^2;
y=0.5-(sin(sqrt(temp))^2-0.5)/(1+0.001*temp)^2;
y=-y;
Griewank.m
function y=Griewank(x)
%Griewan函数
%输入x,给出相应的y值,在x=(0,0,…,0)处有全局极小点0.
%编制人:
%编制日期:
[row,col]=size(x);
if row>1
error('输入的参数错误');
end
y1=1/4000*sum(x.^2);
y2=1;
for h=1:col
y2=y2*cos(x(h)/sqrt(h));
end
y=y1-y2+1;
%y=-y;
fun.m
function y = fun(x,label)
%函数用于计算粒子适应度值
%x input 输入粒子
%y output 粒子适应度值
if label==1
y=Rastrigin(x);
elseif label==2
y=Schaffer(x);
else
y= Griewank(x);
end
fun1
function y = fun(x)
%函数用于计算粒子适应度值
%x input 输入粒子
%y output 粒子适应度值
y=-20*exp(-0.2*sqrt((x(1)^2+x(2)^2)/2))-exp((cos(2*pi*x(1))+cos(2*pi*x(2)))/2)+20+exp(1);
%y=x(1)^2-10*cos(2*pi*x(1))+10+x(2)^2-10*cos(2*pi*x(2))+10;
Drawfunc.m
function Drawfunc(label)
x=-5:0.05:5;%41列的向量
if label==1
y = x;
[X,Y] = meshgrid(x,y);
[row,col] = size(X);
for l = 1 :col
for h = 1 :row
z(h,l) = Rastrigin([X(h,l),Y(h,l)]);
end
end
surf(X,Y,z);
shading interp
xlabel('x1-axis'),ylabel('x2-axis'),zlabel('f-axis');
title('mesh');
end
if label==2
y = x;
[X,Y] = meshgrid(x,y);
[row,col] = size(X);
for l = 1 :col
for h = 1 :row
z(h,l) = Schaffer([X(h,l),Y(h,l)]);
end
end
surf(X,Y,z);
shading interp
xlabel('x1-axis'),ylabel('x2-axis'),zlabel('f-axis');
title('mesh');
end
if label==3
y = x;
[X,Y] = meshgrid(x,y);
[row,col] = size(X);
for l = 1 :col
for h = 1 :row
z(h,l) = Griewank([X(h,l),Y(h,l)]);
end
end
surf(X,Y,z);
shading interp
xlabel('x1-axis'),ylabel('x2-axis'),zlabel('f-axis');
title('mesh');
end
测试数据及运行结果分析
1.c1,c2,w为一组做控制变量法
(1)c1=1.49445,c2=1.49445,w∈[0.9,0.4]
收集十次收敛完后的最优适应度数据
2.984877
1.989918
0.000000
4.974795
3.982830
5.969754
5.969754
2.259348
6.964713
0.000000
取平均值得 3.509598
(2)c1=1.49445,c2=1.49445,w∈[0.8,0.3]
收集十次收敛完后的最优适应度数据
2.137438
0.994959
0.994959
6.964713
2.984877
0.000000
1.322127
0.000000
0.994959
1.989918
取平均值得1.838395
(3)c1=1.49445,c2=1.49445,w∈[0.7,0.2]
收集十次收敛完后的最优适应度数据
0.101236
0.056257
0.994959
0.000015
0.000000
4.974795
7.959672
4.974795
6.964713
0.000000
取平均值 2.6026442
| w | 最优适应度 |
|---|---|
| [0.9,0.4] | 3.509598 |
| [0.8,0.3] | 1.838395 |
| [0.7,0.2] | 2.6026442 |
从实验结果可以看出,当c1,c2不变时,w呈线性变化时,w不是越大越好或者越小越好,而是当w取于某个范围时,最优适应度最低,实验数据为[0.8,0.3]时找到最优解。
(4)c1∈[2,0.5],c2∈[2,0.5],w=0.8
收集十次收敛完后的最优适应度数据
1.060720
5.969754
4.974795
6.964713
0.000000
3.979836
0.994959
0.000001
0.994959
0.994959
取平均值 2.5929737
(5)c1∈[1.5,0.5],c2∈[1.5,0.5],w=0.8
收集十次收敛完后的最优适应度数据
5.969754
0.994959
4.974795
0.000000
1.995288
5.969754
5.969754
0.000048
0.000000
0.000000
取平均值2.5874352
(6)c1∈[2,1],c2∈[2,1],w=0.8
收集十次收敛完后的最优适应度数据
4.974795
0.000000
3.979836
3.979838
1.989918
2.984877
0.000000
3.979836
1.989918
5.969754
取平均值 2.9839018
| c1 | c2 | 最优适应度 |
|---|---|---|
| [2,0.5] | [2,0.5] | 2.5929737 |
| [1.5,0.5] | [1.5,0.5] | 2.5874352 |
| [2,1] | [2,1] | 2.9839018 |
从实验结果可以看出,当w=0.8不变时,c1,c2同步变化,并不是越大越好,而是越小越好,当c1,c2越取越小时,最优适应度越来越小,实验得出当c1,c2取[1.5,0.5]时,得到最优解。
(7)c1∈[2,0.5],c2∈[0.5,2],w=0.8
收集十次收敛完后的最优适应度数据
3.979836
6.964713
0.994959
0.000000
0.000000
2.984877
0.000000
5.969754
3.979836
0.000000
取平均值2.4873975
(8)c1∈[1.5,0.5],c2∈[0.5,1.5],w=0.8
收集十次收敛完后的最优适应度数据
0.994959
6.964713
4.974809
7.959672
1.989918
0.000000
4.974795
0.994959
0.000000
1.989918
取平均值3.0843743
(9)c1∈[2,1],c2∈[1,2],w=0.8
收集十次收敛完后的最优适应度数据
4.974795
4.974795
0.995117
0.994959
1.989918
0.000061
3.979836
4.974795
5.969754
4.974795
取平均值2.8844276
| c1 | c2 | 最优适应度 |
|---|---|---|
| [2,0.5] | [0.5,2] | 2.4873975 |
| [1.5,0.5] | [0.5,1.5] | 3.0843743 |
| [2,1] | [1,2] | 2.8844276 |
从实验结果可以看出,当w=0.8不变时,c1,c2异步变化时,当c1,c2的变化幅度越大的时候,最优适应度越小,越容易找到最优解,本次实验当c1∈[2,0.5],c2∈[0.5,2]时取得最优解。
2.sizepop,dim为一组做控制变量法
(1)sizepop=200,dim=10
收集十次收敛完后的最优适应度数据
2.984877
5.969754
2.984877
3.979836
3.580741
1.989918
0.142237
2.984877
2.984877
4.974795
、取平均值2.7597117
(2)sizepop=300,dim=10
收集十次收敛完后的最优适应度数据
0.994959
3.979836
1.989918
0.994959
0.000000
1.989918
1.989918
0.000000
7.959672
0.000002
取平均值1.989918
(3)sizepop=400,dim=10
收集十次收敛完后的最优适应度数据
0.994959
0.994959
1.989918
0.994959
3.979836
0.000000
3.979836
3.979836
5.969754
4.974795
取平均值2.7854057
| sizepop | 最优适应度 |
|---|---|
| 200 | 2.7597117 |
| 300 | 1.989918 |
| 400 | 2.7854057 |
%从实验结果可以看出,当dim=10不变时,sizepop并不是越大越好或者越小越好,而是取得相应的最优值的时候更容易找到最优解,本次实验当sizepop=300的时候,取得实验最优解。
(4)sizepop=200,dim=20
收集十次收敛完后的最优适应度数据
9.949591
6.964713
8.954632
17.909253
3.979836
6.964713
4.974795
9.949591
9.949591
13.929427
取平均值7.9547124
(5)sizepop=200,dim=30
收集十次收敛完后的最优适应度数据
12.934468
10.944550
17.909258
10.944550
13.929427
0.994960
13.929427
9.949591
22.884053
6.964713
取平均值9.153623
(6)sizepop=200,dim=40
收集十次收敛完后的最优适应度数据
25.868926
13.929427
15.919345
27.858854
6.964714
3.979836
11.939509
10.944550
23.879013
7.959673
取平均值11.7405161
| dim | 最优适应度 |
|---|---|
| 20 | 7.9547124 |
| 30 | 9.153623 |
| 40 | 11.7405161 |
从实验结果可以看出,当sizepop=200不变时,dim的值越变越大,而最优适应度越变越大,这说明当dim也就是当问题维度越大的时候,这个算法越不容易找到最优解。
实验结论
与遗传算法相比,他们的共同之处在于
1、都属于全局优化算法,属于随机搜索算法。
2、但是因为高维复杂问题,往往会遇到早熟收敛和收敛性能差的缺点,经常无法保证收敛到最优点。
而两者的不同点在于:
1、PSO有记忆,好的解都会被保存,而GA的解都会随着种群的改变而改变。
2、PSO是一种单共享项信息机制,而GA中的染色体之间会相互共享信息,使得整个种群都向最优区域移动。
3、GA的编码技术和遗传操作比较简单,而PSO相对于GA没有交叉和变异操作,例子只是通过内部速度进行更新,因此原理更简单、参数更少、实现更容易。
从实验可以看出
1、w(惯性权重)的值并不会是越大越好,或者是越小越好,而是当取到一个合适的值的时候,对于算法帮助越大。
2、c1、c2(加速因子),当两者同步变化时,两者越小越好,对于找到最优解帮助越大。而当两者异步变化时,两者变化幅度越大,找到最优解的可能越大。
3.sizepop(种群规模)的值也是当取得最合适的值的时候,越容易找到最优解。
4.dim(适应度函数维度),也就是问题的维度,可以看出,当问题的维度越大也就是越难的时候,这个算法越容易陷入局部最优解,越难找到问题的最优解。














 1823
1823











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









