






作者:Woosuk Kwon1,∗ Zhuohan Li1,∗ Siyuan Zhuang1 Ying Sheng1,2 Lianmin Zheng1 Cody Hao Yu3 Joseph E. Gonzalez1 Hao Zhang4 Ion Stoica1
1. 序言
LLM高吞吐推理服务需要充分的Batching,由于单个请求的K-V Cache需求较大且动态伸缩,如果不能高效管理K-V Cache内存,会导致碎片化和冗余。为了解决这个问题,我们提出了基于操作系统中经典虚拟内存和内存页技术的PagedAttention算法。在这个基础上,我们构建了vLLM,实现如下目标:
1)K-V Cache零内存浪费
2)K-V Cache在请求内和请求间弹性共享以减少内存使用
评测结果表明在相同时延下,对比SOTA系统(如FasterTransformer/Orca),当前流行的LLM有2-4x的吞吐提升。并且在更长序列,更大模型,更复杂的decoding算法下,提升更明显。
LLM使能了许多新型应用,如编程助手、对话机器人等。许多云计算公司竞相通过托管服务形式提供这类应用。运行这些应用需要大量的硬件加速器如GPU,成本非常高。根据近期的估算,处理LLM的请求的成本是传统关键词查询请求的10x。因此降低每请求的推理成本变得愈发重要。
LLM的核心是一个自回归的Transformer模型,模型输入prompt,基于prompt和已经生成的token,以1次1个的方式输出token。这个昂贵的过程不断重复,直到模型输出终止token。序列生成过程是memory-bound的,未能充分利用GPU的运算能力,限制了服务的吞吐。可以通过Batching多个请求的方式提升吞吐,这种方式要求对内存空间进行高效管理。
图1展示了13B LLM在NVDIA A100 GPU(40GB RAM)上的内存占用分布:
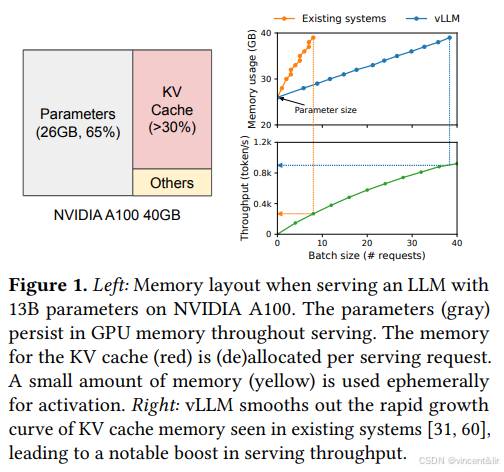
模型权重静态占用了大约65%的内存。服务请求的动态状态占用了30%的内存,Transformer中这部分内存主要是Attention机制中使用的K-V Cache,是生成序列中的新token所需的上下文。剩下的不到5%的内存是激活值和一些临时张量。
由于模型权重是静态的,激活值占用内存较少,所以K-V Cache的管理决定了Batch Size的上线。如图1所示,如果K-V Cache管理低效,会很大程度限制Batch Size,从而影响LLM的吞吐。
我们观察到现有的LLM推理系统未能有效管理K-V Cache的主要原因是将一个请求的K-V Cache在内存中连续存放。这种做法忽略了K-V Cache的特点:K-V Cache在推理过程中动态伸缩,生命周期和长度一开始是未知的。
K-V Cache的特点导致了现有系统实现方案的2大主要问题:
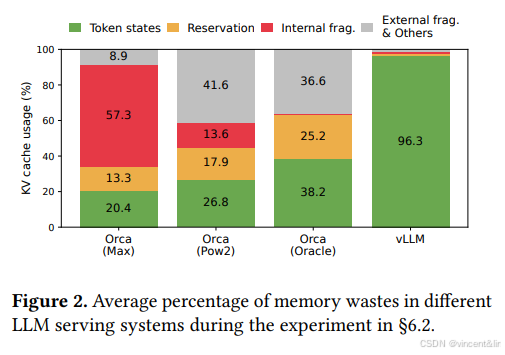
1、内部/外部内存碎片:为了将请求的K-V Cache存放到连续内存空间,预申请了最大长度的内存(比如2048个Token),这样导致了内部内存碎片,因为实际长度可能远小于最大长度。同时,不同的请求的预申请长度不同,导致了外部内存碎片。我们的性能分析结果显示K-V Cache只有20.4% - 38.2%的有效利用率,如图2所示。
2、不能共享内存:LLM推理通常使用的解码算法,如parallel sampling和beam search等。
parallel sampling:
beam search:
这些算法为每个请求生成多个输出,输出间可以部分共享K-V Cache。而现有系统由于将不同输出的K-V Cache存储到分离的连续空间,不能实现复用。
为了解决上述问题,我们提出了PagedAttention算法:虚拟内存和页。PagedAttention将请求的K-V Cache切分为block,每个block包含固定数量的token的K-V Cache,block间不需要内存连续。可以将block类比为page,token类比为bytes,request类比为process。这种设计使用按需分配的小块内存block,缓解了内部内存碎片;所有block的长度相同,消除了外部内存碎片。同时可以让不同的输出序列(请求内和请求间)以block的粒度共享K-V Cache。
我们基于PagedAttention构建了vLLM,一个高吞吐的分布式LLM推理服务引擎,实现了几乎零浪费的K-V Cache内存,支持block粒度的内存管理和抢占调度。支持不同大小的GPT/OPT/LLaMA等主流模型。
总结来说,我做了如下贡献:
1、识别了LLM推理的内存分配挑战并量化了对推理性能的影响。
2、提出了PagedAttention算法,将K-V Cache存储到不连续的block中。
3、设计并实现了vLLM,一个基于PagedAttention的分布式的推理服务引擎。
4、评估了不同场景下的vLLM的性能,证明了vLLM性能总体优于SOTA的推理服务引擎如FasterTransformer和Orca。
2. 背景
2.1 基于Transformer的LLM
语言模型的任务是对token序列(𝑥1, . . . , 𝑥𝑛)的概率建模。因为语言有自然顺序关系属性,所以通常将整个句子的联合概率分解为条件概率的乘积,即自回归分解。
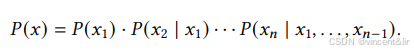
Transformers已经成为处理大规模语言建模任务的事实标准,其中最重要的组件是self-attention。对一个输入的隐状态序列:(𝑥1, . . . , 𝑥𝑛) ∈ R 𝑛×𝑑 ,self-attention对其中的每个位置进行线性变换,得到query,key,value向量:
![]()
然后,self-attention再计算每个位置i与位置j的attention score 𝑎𝑖𝑗,再求和得到value向量的权重𝑜𝑖:
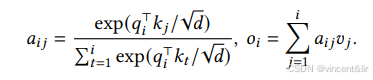
其他的模块还包括embedding,feed-forward,layer normalization,residual connection,output logit computation。
2.2 LLM服务 & 自回归生成
训练完成后,LLM被当做条件生成服务部署(比如续写API或者聊天机器人)。一个LLM服务的请求提供一串prompt tokens (𝑥1, . . . , 𝑥𝑛), LLM服务基于概率生成一串output token(𝑥𝑛+1, . . . , 𝑥𝑛+𝑇 ) 。我们将输入和输出连接起来叫做序列,LLM每次基于已经生成的tokens来生成下一个新的token。在序列生成过程中,已经生成的tokens的key、value向量通常会被缓存起来,用于后续的token生成,这个缓存被称为K-V Cache。K-V Cahe和token的位置相关,即在序列中的不同位置的相同Token的K-V Cache是不同的。给定请求的prompt,序列生成计算可以分解为2个阶段:
1、prompt phase:将用户的整个prompt (𝑥1, . . . , 𝑥𝑛)当作输入,计算第一个新token的概率:𝑃 (𝑥𝑛+1 | 𝑥1, . . . , 𝑥𝑛)。在这个过程中会生成key向量: 𝑘1, . . . , 𝑘𝑛和value向量:𝑣1, . . . , 𝑣𝑛.因为所有的prompt token是已知的,所以这个过程可以通过矩阵乘运算并行化,充分利用GPU的并行性。
2、autoregressive generation phase:串行生成剩下的token,直到遇到EOS Token或者达到长度限制。每轮迭代𝑡, 模型输入一个token 𝑥𝑛+𝑡,计算key向量𝑘1, . . . , 𝑘𝑛+𝑡,value向量𝑣1, . . . , 𝑣𝑛+𝑡 ,概率:𝑃 (𝑥𝑛+𝑡+1 | 𝑥1, . . . , 𝑥𝑛+𝑡)。基于K-V Cache机制,只有𝑘𝑛+𝑡和𝑣𝑛+𝑡需要计算。由于存在数据依赖,所以不同的迭代只能串行,导致GPU的算力利用严重不充分,是单个请求时延的主要部分。
2.3 LLM Batching技术
可以通过batching多个请求提升LLM服务的算力利用率。因为不同的请求共享相同的模型权重,所以模型权重的搬移开销被平摊到了batch中的多个请求,并且当batch足够大时,可以被计算开销掩盖。但是Batching有2个难点:
1、请求不同时到达。一个朴素的batching策略会显著增加排队时延。
2、不同请求之间的输入、输出长度差异大。
为了解决这2个问题,细粒度的batching机制,比如cellular batching和iteration-level scheduling。这些技术工作在迭代级别。每轮迭代结束后,已经完成的请求被移出batch,新请求被加入。这样一个新的请求不用等到整个batch完成后才得到处理。此外,通过定制的GPU kernel,可以消除输入和输出中的padding。细粒度的batching机制显著提升了LLM服务的吞吐。
3 LLM服务的内存挑战
尽管细粒度的batching减少了算力的浪费,使能了灵活的请求batch策略,但是batching请求的数量仍然被GPU的内存容量限制,特别是K-V Cache。换句话说,服务系统的吞吐是memory-bound的。解决这个问题需要增大K-V Cache的容量。K-V Cache大小会随着请求数量快速上涨,以13B的OPT模型为例,一个token需要800KB = 2(key + value)* 5120(隐状态长度)* 40(层)* 2(FP16) 的空间。因为OPT的序列长度最长为2048个Token,所以需要1.6G来存储K-V Cache。GPU有几十GB的内存容量,假设所有的内存都用于存放K-V Cache,也只能容纳几十个请求。低效的内存管理还会进一步减少batch大小。
此外根据当前的发展趋势,GPU的算力增长速度高于内存容量,比如NVDIA的A100到H100,FLOPS增加了2x,内存保持最高80GB不变,内存称为了关键瓶颈。LLM服务提供了一系列的decoding算法给用户选择,拥有不同的内存管理复杂度。举例来说,在编程建议应用中,1个输入prompt会生成多个输出序列,输入prompt的KV Cache可以被多个输出序列共享,而对于自回归生成阶段的K-V Cache又不能共享。K-V Cache的共享程度取决于decoding算法,比如beam search最多可以通过共享节省55%的内存。
LLM服务的请求的输入输出长度区别很大,要求内存管理系统支持一个大prompt长度区间。此外,请求的输入长度在decoding时不断增长,可能会耗尽内存,因此系统需要进行调度决策,比如从GPU内存中删除或者换出一些请求的K-V Cache。
3.1 现有系统的内存管理
现有的深度学习框架要求张量被存放到连续内存中,因此会使用最大的序列长度静态分配一块K-V Cache内存。如图3所示,请求A的最大长度为2048,请求B的最大长度为512。
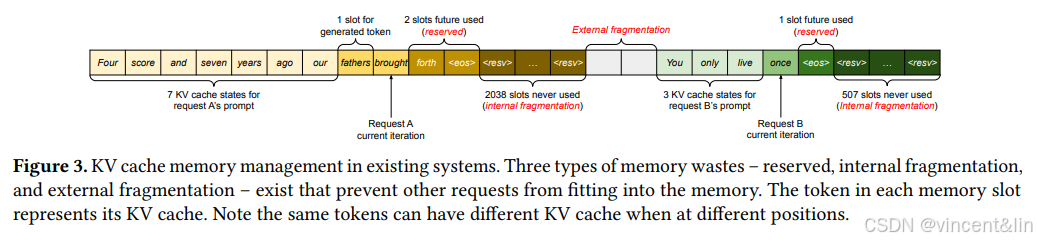
这种分配策略有3个主要的内存浪费:
1、为即将生成的token预留slot。
2、用最大序列长度申请内存产生的内部碎片。
3、内存分配器(如伙伴算法)产生的外部碎片。
我们可视化了实验中发现的内存浪费,如图2。揭示了实际的内存利用率仅仅只有20.4%。内存碎片的一个解决方案是内存整理,但这个方案在性能敏感的LLM服务中是不现实的,并且也不能实现内存共享。
4 方法
我们开发了一个新的attention算法:PagedAttention,构建了一个LLM服务引擎:vLLM,解决第3节提出的挑战。架构如图4所示:
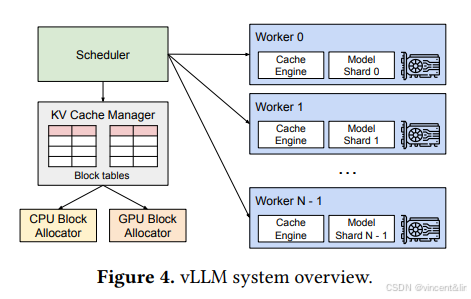
vLLM使用了集中式Scheduler协调分布式GPU Workr的执行。K-V Cache Manager按照Scheduler的指示,通过页的形式管理GPU上的物理K-V Cache内存。
4.1 PagedAttention
PagedAttention通过将K-V Cache分块成K-V Block的方式,允许将连续的key和value向量存储到不连续的内存中。每个K-V Block包含固定数量的token的key、value向量。意味着对key block 𝐾𝑗 = (𝑘(𝑗−1)𝐵+1, . . . , 𝑘𝑗𝐵)和value block 𝑉𝑗 = (𝑣(𝑗−1)𝐵+1, . . . , 𝑣𝑗𝐵). attention的计算可以被转换为如下的分块形式:
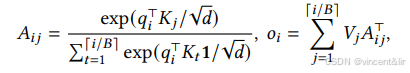
在attention计算过程中,PagedAttention kernel从离散内存中读取K-V block,如图5所示:
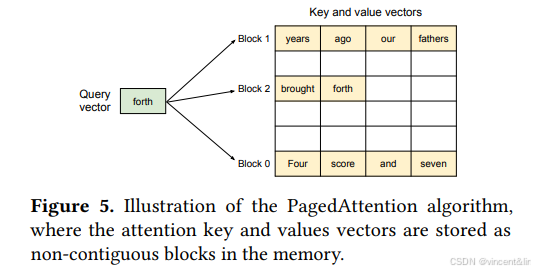
4.2 KV Cache Manager
vLLM内存管理借鉴了OS的方法,将内存分割为固定大小的Physical Page,将用户程序的Logical Page映射到Physical Page,这样连续的Logical Page就可以被映射到不连续的Physical Page上,并且物理内存空间不用提前预留。vLLM将一个请求的K-V Cache表示为一串Logical Block,在K-V Cache产生的过程中从左往右依次填充。在GPU Worker上,Block Engine申请一块连续的GPU RAM,并分割为Physical Block(在CPU上做相同的操作用于换入换出)。K-V Block Manager维护一个Block Table,Block Table中的每个Entry记录了Logical Block对应的Physical Block和已经填充的位置的数量。
4.3 Decoding with PagedAttention and vLLM
接下来,我们通过一个例子(如图6),展示vLLM处理单一请求的过程。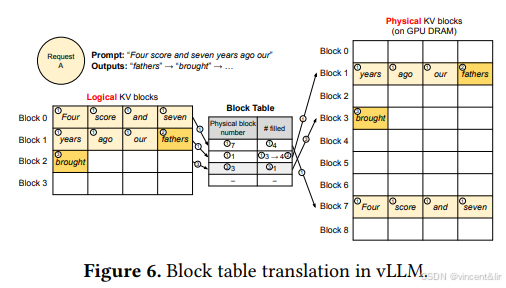
在这个例子中,prompt有7个token,所以vLLM映射了2个Logic Block(0,1)到Physical Block(7,1)。在prefill阶段,vLLM生成prompt的K-V Cache和第一个token。vLLM将前4个token的KV Cache存放到Logic Block0,将后3个token的KV Cache存放到Logic Block1。
第一个autoregressive decoding,vLLM使用PagedAttention算法和Logical Block0,1中的KV Cache计算新的token,因为Logical Block1中还有1个slot,所以新token的KV Cache被存放到Logical Block1中。
第二个autoregressive decoding,因为Logical Block1已经存满了,所以vLLM将token的KV Cache存到新的Logical Block2中,vLLM新分配1个对应的Physical Block 3。
总的来看,每轮decoding迭代,vLLM选取一个候选序列集合做batching,为新的Logical Block分配对应的Physical Block。接下来,vLLM将本轮迭代所有的输入token连成1个序列,输入进LLM。在LLM计算期间,通过PagedAttention从Logical Block中读取之前生成的KV Cache,并将新生成的KV Cache写入。
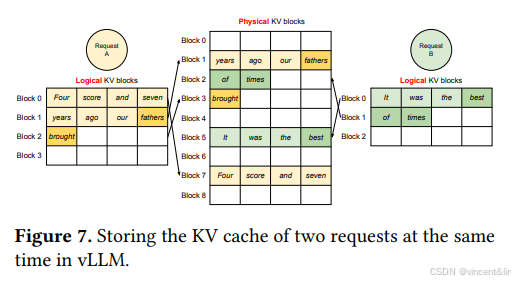
vLLM将1个请求的内存浪费限制到了1个Block内,所以内存利用率更高。这样可以将更多的请求batching到一起,提高了吞吐。当请求生成结束后,KV Block会被释放,用于存储新的请求。在图7中,我们展示了vLLM管理2个请求序列内存的例子。
4.4 其他decoding场景
4.3展示了vLLM处理基本的decoding算法的例子,如greedy decoding和sampling, 这些场景输入1个用户prompt,生成1个输出序列。在很多成功的LLM应用中,LLM服务需要提供更复杂的decoding场景。
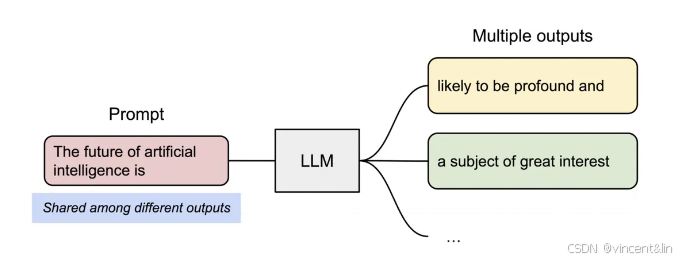
parallel sampling
基于LLM的编程助手输入1个用户prompt,会生成多个输出序列,用户可以从中选择,如图8所示。
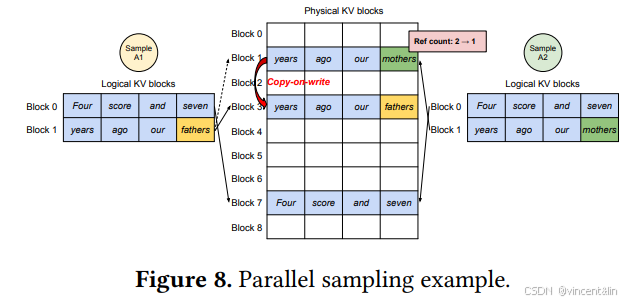
两个输出共享同一个prompt,所以我们在prefill阶段只保存1份prompt的KV Cache,两个输出序列的Logical Block映射到同一个Physical Block。Physical Block维护了1个引用计数,在这个阶段,Physical Block7,1的引用计数都是2。
在生成阶段,由于两个输出序列生成了2个不同的token,所以需要分离KV Cache,vLLM实现了Block粒度的copy-on-write,当Sample A1需要写入Logical Block1时,vLLM发现对应的Physical Block1的引用计数大于1,所以会新分配1个Physical Block3,并指示Block Manager将Physical Block1中的内容拷贝到Physical Block3,并减少Physical Block1的引用计数。这样当Sample A2写入Physical Block1时,因为引用计数已经减到1,直接写入即可。
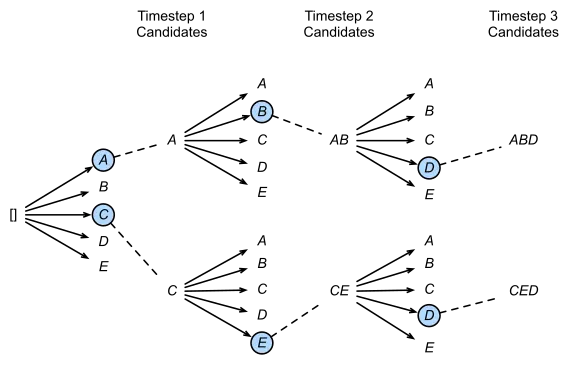
Beam Search
在机器翻译中,用户希望得到tok-k个输出,通常使用Beam Search算法,因为该算法减轻了全遍历采样空间的复杂度。算法通过beam width参数,决定每一步需要保留的候选采样数量。在decoding过程中,beam search扩展每一个beam中的候选序列,考虑所有可能的token,计算各自的概率,从 𝑘 · |𝑉 |个候选序列中,保留tok-k个最高概率的序列,其中 |𝑉 |是词表大小。
不同于并行parallel decoding,beam search不止共享prompt的block,还在多个候选序列中共享block,共享的模式随着decoding的过程改变,和OS中fork产生的进程树相似。图9展示了beam width=4的例子。本轮迭代前的状态在虚线的左边,每个候选序列占用4个完整block。后续的迭代,top-4的候选序列是候选序列1,2的后继,所以Block2,4,8,5的logical block被释放,physical block的引用计数清零,vLLM会释放这些physical block。之后会分配新的physical block 9-12。
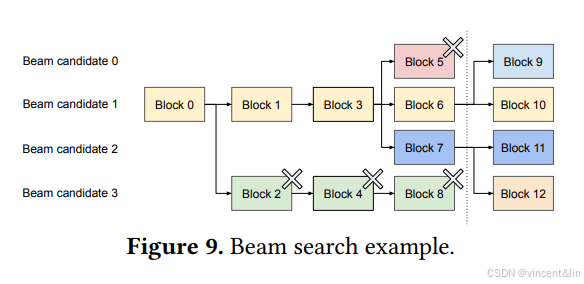
之前的LLM服务系统会经常在候选序列之间拷贝KV Cache,举例来说,在虚线右边,候选序列3需要拷贝候选序列2的前4个blcok来继续生成。
Shared prefix
通常LLM用户会提供一个任务描述,包含指令和输入输出样例,这个也叫做system prompt。这个prompt会和实际的任务输入拼接起来,形成请求的prompt。LLM基于这个prompt生成输出,如图10所示:
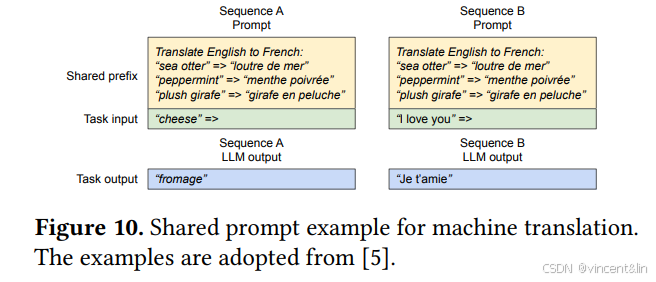
此外,共享前缀可以被调整,通过提示工程,去改进下游任务的精确度。对这种类型的应用,很多用户prompt会共享一个前缀,所以LLM服务可以将前缀的KV Cache提前存储下来,以减少前缀的冗余计算。在vLLM中,这个可以通过保留预定义共享前缀的KV physical block很方便的实现,就像OS处理进程间共享的库一样。用户共享相同前缀可以很方便地将logical block映射上去,这样只需要计算用户任务的输入token就可以了。
Mixed decoding methods
上述不同decoding请求的内存共享和访问模式各不相同。因为vLLM通过logical block到physical block的映射层,封装了不同decoding请求,不同序列之间复杂的内存共享。相比现有系统,vLLM可以更好地同时处理这些不同的请求,提升了batch的可能性,从而提升系统的吞吐。
4.5 Scheduling and Preemption
当请求流量超过系统的容量时,vLLM需要优先调度请求的一个子集。在vLLM中,我们使用了FCFS的调度策略,保证了公平并防止饿死。LLM服务面临一个独特的挑战:输入prompt的长度差异很大,输出的长度也不能预知。当请求数和输出序列增长时,vLLM可能会耗尽GPU的physical block。在这个场景下,vLLM需要回答如下问题:
1)应该驱逐哪些block?
2)怎么样恢复被驱逐的block?一个序列的所有block是同时被访问的,vLLM使用了驱逐整个序列的所有block的策略。此外,一个请求产生的多个序列使用组调度,这些序列会被同时抢占或者重调度,因为他们之间存在共享内存。
为恢复被驱逐的block,使用了2个技术:
1. 交换(swapping):这是大多数虚拟内存使用的经典技术,将驱逐的页拷贝到磁盘上的交换空间。在vLLM里,我们将block驱逐到CPU内存。如图4所示,除了GPU block分配器,vLLM还包含了CPU block分配器,用于管理交换到CPU RAM的block。当vLLM耗尽了空闲的physical block时,会选择一组序列,将KV Cache交换到CPU。当抢占和block换出发生时,vLLM会停止接收新的请求,直到所有抢占的序列处理完成。再将被抢占的序列的KV Cache换入,继续之前的处理。这种设计下,CPU RAM的交换空间大小不会超过GPU分配给KV Cache的空间大小。
2. 重计算(recomputation):被抢占序列得到重调度时,重新计算KV Cache。注意到重计算的时延会低于原始时延,因为已经生成的token会和prompt连接起来当做新的prompt计算,只需要一个迭代就可以生成所有token的KV Cache。
交换和重计算的性能取决于CPU RAM和GPU内存之间的带宽和GPU的算力。
4.6 分布式执行
许多LLM的参数大小会超过单GPU的内存容量,需要将模型切分到多个GPU上。这就需要内存管理具备管理分布式内存的能力。vLLM支持广泛使用的Megatron-LM风格的张量并行策略。这个策略遵从SPMD的执行调度,线性层被切分为分块矩阵乘,GPU间不断通过allreduce操作同步中间结果。特别的,attention操作按照attention head的维度切分,每一个SPMD进程处理attention head的一个子集。我们观察到即使是模型并行执行下,每个模型切片仍然处理相同的输入token,即相同位置的KV Cache相同。vLLM其中央调度器内集成了一个KV缓存管理器单例,如图4所示。不同的GPU worker共享一个manager。这种设计让GPU Worker可以通过相同的Physical block ID访问各自的KV Cache切片。
每一步的处理过程:
1. 调度器将batch中的请求消息转换为tokens,并分配block table。
2. 调度器将控制消息广播到所有的GPU Worker。
3. GPU Worker开始运行模型处理输入tokens。在attention layer中,GPU Worker读取控制消息中的block table,找到对应的KV block。
4. 在执行过程中,通过all-reduce集合通信同步中间结果,不需要scheduler的协调。
5. 最后,GPU Worker将本轮迭代采样的token发送给scheduler。
总结一下,GPU Worker在内存管理中不需要scheduler进行同步,只需要在每轮迭代一开始接收全部的内存管理信息即可。
5 实现
vLLM是一个基于GPU的端到端的服务系统,前端是FastAPI。前段扩展了OpenAI的API,允许用户定制化每个请求的采样参数,如最大序列长度,beam width等。vLLM engine一共有8.5K的Python和2K的C++/CUDA代码。控制相关的组件,包括scheduler,block manager等使用Python实现,自定义CUDA kernel如PagedAttention使用C++/CUDA实现。我们基于PyTorch和Transformers库实现了主流的LLM,包括GPT,OPT,LLaMA,使用NCCL作为集合通信库。
5.1 Kernel级优化
因为PagedAttention的内存访问方式不能被现有系统有效支持,所以我们开发了几个GPU kernel进行优化:
1)融合reshape和写block:在Transformer每一层,新生成的KV Cache被分块放入block,reshape成block读友好的布局,再存入block。
2)融合读block和attention:适配了FastTransformer中的attention kernel的读KV Cache操作,并且在读block的过程中同时进行attention操作。为了保证内存合并访问,我们单独分配了1个GPU warp去读KV block。此外,我们增加了对一个请求batch中不同序列可变长度的支持。
(3) 融合block拷贝。copy-on-write触发的block拷贝操作,可能会操作不连续的block。这样会导致大量的拷贝小块内存的cudaMemcpyAsync API调用。为了减轻这个开销,我们实现了一个kernel批处理不同的block拷贝。
5.2 Supporting Various Decoding Algorithms
vLLM实现了多种decoding算法,有3个关键方法:fork,append,free。
1)fork方法基于已有的序列创建1个新序列。
2)append方法将1个新token追加到序列。
3)free方法删除序列。
以parallel sampling为例,vLLM先基于输入序列fork出多个输出序列,然后每轮迭代使用append方法将新token追加到输出序列,遇到终止条件后使用delete删除序列。同样的策略可以被应用到beam search和prefix sharing算法。并且我们相信未来的decoding算法也可以通过组合这些方法支持。
6 Evaluation
我们评估了vLLM在多种工作负载下的性能。
6.1 实验设置
模型和配置
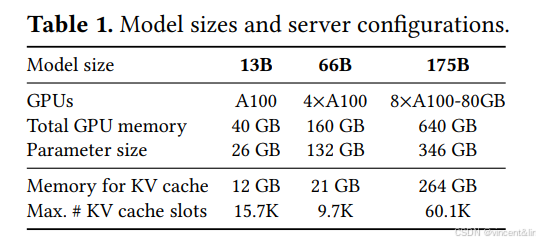
我们使用了13B,66B,175B的OPT模型和13B的 LLaMA模型用于评估。在LLM leaderboard上,13B和66B模型是LLM的主流大小,而175B是GPT-3的模型大小。我们使用带NVDIA A100 GPU的Google Cloud的A2实例完成所有的实验。模型大小和服务器配置细节如表1所示:
工作负载
我们使用ShareGPT和Alpaca 数据集,合成了工作负载。ShareGPT数据集是用户共享的与用户与ChatGPT的对话记录,Alpaca数据集是GPT-3.5通过self-instruct生成的指令数据集。我们将数据集进行分词,并利用其输入和输出的长度来合成客户端请求。如图11所示:

因为数据集中没有包含时戳,我们使用泊松分布(Poisson distribution)和不同的请求率生成请求的到达时间。
基线1: FasterTransformer
FasterTransformer是一个时延高度优化的分布式推理引擎。因为FasterTransformer没有自己的调度器,我们参考Triton实现了一个自定义动态批调度器。特别的,我们根据GPU的内存容量最大化了batch size B。调度器取出最早到达的前B个请求,将其送入FasterTransformer处理。
基线2: Orca
Orca是一个SOTA的LLM服务系统。 因为Orca当前并不能公开获取使用,我们实现了自己的Orca版本,我们假设Orca使用了伙伴算法来分配KV Cache。我们实现了3个版本的Orca:
1. Orca (Oracle):假设系统预先知道请求的输出长度。展示了Orca性能的上界,在真实实践中是不可行的。
2. Orca (Pow2):假设系统为输出预留最多2^x的内存。比如输出长度是25,就会预留32。
3. Orca (Max):假设系统按照最大序列长度来预留内存,比如2048。
关键指标
我们聚焦服务的吞吐,使用不同的请求率的工作负载,我们测量系统的归一化时延 - 每个请求的平均端到端时延除以输出长度。高吞吐率的系统在高请求率下应该保持更低的归一化时延。大部分实验评估了系统1个小时的跟踪数据。对OPT-175B模型,因为算力限制,只使用了15分钟的跟踪数据。
6.2 Basic Sampling
在3个模型和2个数据集上评估了basic sampling(样本/请求)的性能。图12第一行是ShareGPT数据集的结果。曲线展示了当请求率提升时,时延一开始逐渐上升,然后突然爆炸,即请求率超过了服务系统的能力,队列长度和时延会继续无限增加。在ShareGPT数据集上,vLLM在相同时延的前提下,能处理的请求率相比Orca(Oracle)高1.7x-2.7x,相比Orca (Max)高2.7x-8x。原因是PagedAttention可以更有效地管理内存,使能了更大的请求batch size。如图13a所示,OPT-13B vLLM相同时间可以处理的请求数是Orca (Oracle)的2.2x,是Orca (Max)的4.3x。vLLM能处理的请求率是FasterTransformer的22x,因为FasterTransformer没有一个细粒度的调度机制,且内存管理和Orca (Max)一样低效。
如图12的第2行和图13b所示,Alpaca数据集上实验结果的趋势和ShareGPT类似。一个例外是图12f,vLLM相比Orca (Oracle) 和Orca (Pow2)的优势并不明显。这是因为OPT-175B拥有大量的GPU内存空间用于存放KV Cache,并且Alpaca数据集的序列长度短。在这种设定下,虽然Orca (Oracle) 和Orca (Pow2)的内存管理低效,但是也可以batch大量的请求。因此,系统的性能更多是compute-bound的。
6.3 Parallel Sampling和Beam Search
我们评估了PagedAttentiion在2种主流的采样方法:parallel sampling和beam search上的内存管理效率。parallel sampling的结果如图14第一行所示。相似的,图14的第二行展示了不同beam width的beam search的结果。因为beam search可以更多地共享内存,所以vLLM展示了更多的性能收益。vLLM在OPT-13B和Alpaca数据集上,在beam width 6的配置下相比Orca (Oracle)有2.3x的提升,高于basic sampling的1.3x。
图15绘制了内存优化量,用共享节省的block数除以不共享的block总数。Alpaca数据集在parallel sampling上节省了6.1% - 9.8%的内存,在beam search上节省了37.6% - 55.2%的内存。ShareGPT数据集在parallel sampling节省了16.2% - 30.5%的内存,在beam search上节省了44.3% - 66.3%的内存。
6.4 Shared prefix
模型使用LLaMA-13B,数据集使用WMT16 English-to-German translation,并合成了2个prefix,第一个prefix包含了1条指令和1个样例(one-shot),第二个prefix包含了1条指令和5个样例(few-shot)。如图16a所示,第一个prefix,vLLM的吞吐是Orca (Oracle)的1.67x;第二个prefix,vLLM的吞吐量是Orca (Oracle)的3.58x。
6.5 Chatbot
聊天机器人会拼接聊天历史记录和最新的用户prompt,输入给模型生成响应。我们基于ShareGPT数据集合成了这个数据。由于OPT-13B上下文长度的限制,我们取数据的最后1024个token作为Prompt,让模型最多生成1024个token。不保存不同对话轮次的KV Cache。图17显示vLLM相比3个Orca基线,可以处理超过2x请求率。ShareGPT包含了很多长对话。输入prompt大部分都是1024 token,因此3个Orca基线表现类似。作为对比,vLLM可以有效处理长prompt, 因为PagedAttention解决了内存碎片化和保留的问题。
7 消融分析
在这个章节,我们研究vLLM的多个方面,并通过消融实验评估这些设计选择。
7.1 Kernel Microbenchmark
PagedAttention中的动态block映射影响GPU性能的方面主要和KV Cache相关,如block的读写和attention。和现有系统对比,GPU kernel包括了访问block table,执行额外的分支,处理变长的序列长度的额外开销。如图18a所示,这个导致了attention kernel的时延相比高度优化的FasterTransformer实现高了20%-26%,这个额外的开销只和attention操作相关。尽管这里有额外的开销,vLLM的端到端的性能依然高于FasterTransformer。
7.2 Block大小的影响
block大小的选择对vLLM性能影响巨大。如果block太小,vLLM不能有效利用GPU读取和处理KV Cache的并行性。如果block太大,内部碎片会增加,block共享的概率降低。如图18,使用ShareGPT 和 Alpaca数据集,basic sampling采样方法,固定的请求率,评估了不同block大小下vLLM的性能。对ShareGPT数据集,block大小从16到128时有最好的性能。对Alpaca数据集,block大小是16个32时性能好,再大就会显著降低性能,因为序列长度小于block大小。在实践中,我们发现block大小为16,已经可以充分利用GPU的算力,并且能避免较大的内部碎片。因此,vLLM的默认block大小是16。
7.3 对比重计算和交换
vLLM支持2种KV Cache恢复机制:重计算和置换。为了搞清楚这两种方法的利弊,我们评估了他们的端到到性能,并对开销进行了基准测试。如图19所示,结果揭示了当block较小时,交换的开销较大,因为CPU和GPU之间要进行大量的小块数据传输,不能有效的利用PCIe带宽。重计算在不同block大小下,性能差异不大,因为重计算并未利用KV block。对中等的block大小16-64,这两种机制的端到端性能差异不大。
8 讨论
将虚拟内存和页机制应用到其他GPU负载
将这种机制应用到KV Cache,是因为这部分GPU负载需要动态内存申请,且性能受限于GPU的内存容量。但是这个对其他GPU负载并不一定成立。举例来说,对DNN训练,tensor shape都是静态的,所以内存分配可以使用AOT的方式优化。对非LLM的例子,内存利用率提升可能并不会导致性能提升,因为是compute-bound的。在这些场景中,引入vLLM的技术可能反而会降低性能。
LLM对虚拟内存和页机制的特定优化
vLLM利用应用特定语义重新诠释了虚拟内存和页机制。一个例子是all-or-nothing的换出策略,利用了处理一个请求需要所有相关的token状态存储在GPU内存中的事实。另一个例子是利用重计算恢复驱逐的block。此外,vLLM通过kernel融合内存访问操作和运算操作,减少了内存间接访问的额外开销。
9 相关工作
通用模型服务系统
模型服务是近年的热点研究领域,有大量的解决深度学习模型部署各方面问题的系统涌现。Clipper, TensorFlow Serving, Nexus, InferLine, 和Clockwork都是早期的通用模型服务系统。他们研究了batching,caching,placement和scheduling等技术。近期,DVABatch引入了multi-entry multi-exit batching,Shepherd提出了抢占。AlpaServe利用模型并行做统计复用。但是,这些通用系统都没有考虑LLM推理的自回归特性和token状态,错失了这方面的优化点。
Transformer专用服务系统
因为Transformer的重要性,业界研发了大量的Transformer专用服务系统。这些系统利用了GPU kernel优化,进阶的batching机制,模型并行,参数共享高效提供服务。在这些系统中,Orca和我们的做法最类似。Orca的迭代级调度和vLLM的PagedAttention是互补的技术:两个系统都致力于通过增加GPU的利用率来增加LLM服务的吞吐,Orca通过调度和交织请求来增加可以并行调度的请求数,vLLM通过提升内存利用率来将更多的请求放入内存。通过减少内存碎片和使能共享,vLLM相比Orca可以获得2-4x的提速。事实上,Orca的细粒度调度和请求交织让内存管理变得更具挑战,也让vLLM提出的技术显得更关键。
内存优化
加速器的算力和内存容量的差距导致内存成为了训练和推理的瓶颈。交换,重计算还有二者的组合被用于减少训练的内存峰值。值得注意的是,FlexGen研究了LLM推理的weights和token状态交换机制,但并未瞄准在线服务的场景。OLLA优化了张量的生命周期和位置,用于减少碎片,但并未实现细粒度的block粒度的管理。FlashAttention应用了tiling和kernel优化,用于减少attention计算的峰值内存,减少IO开销。
10 结论
本文提出了PagedAttention,一种新的attention算法,允许将attention的key和value存储到不连续的页内存中。同时提出了vLLM,一个高吞吐的LLM服务系统,利用了PagedAttention使能的高效内存管理。受操作系统的启发,我们将虚拟内存和copy-on-write机制适配解决KV cache管理,支持多种decoding算法。实验表明vLLM相比SOTA的系统,可以获得2-4x的吞吐提升。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









