







自然语言处理:数据集(一)
THUCNews中文数据集
THUCNews是根据新浪新闻RSS订阅频道2005~2011年间的历史数据筛选过滤生成,包含74万篇新闻文档(2.19 GB),均为UTF-8纯文本格式。清华大学THUCTC项目组.在原始新浪新闻分类体系的基础上,重新整合划分出14个候选分类类别:财经、彩票、房产、股票、家居、教育、科技、社会、时尚、时政、体育、星座、游戏、娱乐。

该数据集可在清华大学THUCTC项目组网页中下载。
填写完姓名、邮箱、等信息,遵守相关协议后,即可下载。
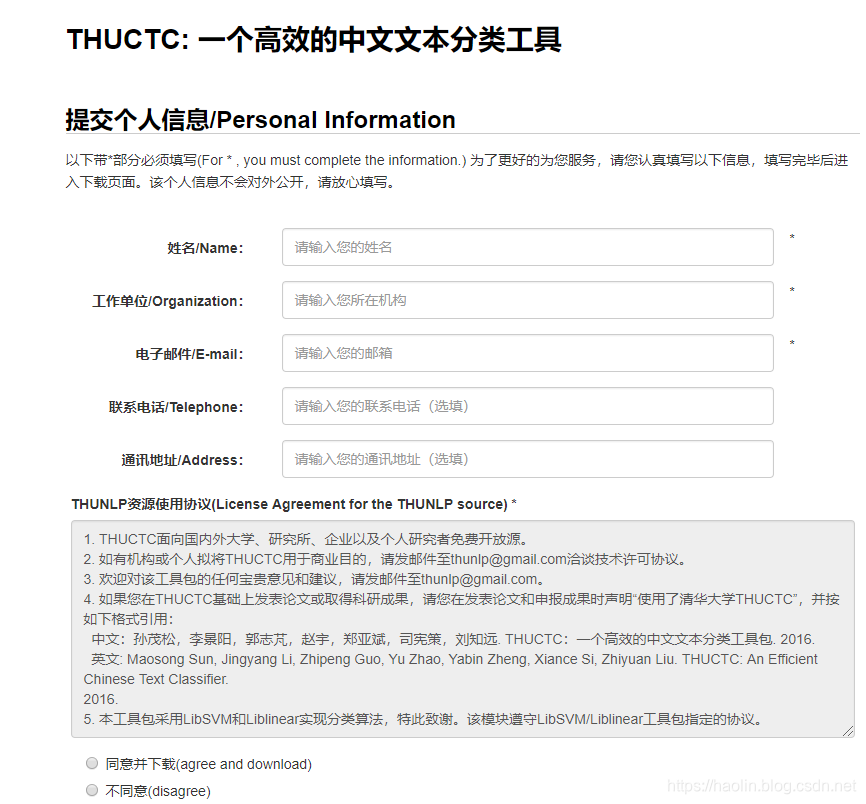
如果,你觉得这个数据集太大,还可以下载其数据子集:
https://pan.baidu.com/s/1hugrfRu 密码:qfud
“Github”.上也有相关的数据子集生成方法,以及基于CNN和RNN的文本分类。
IMDB英文数据集
IMDB是Internet Movie Database(互联网电影数据库)的缩写。IMDB也是美国的一个权威的电影网站,除了电影资料外,还给影片做了评分。

IMDB数据集,包含了25000条高极性的电影评论训练集,和25000条的测试集。是自然语言处理文本二分类问题的经典数据集。
该数据集可以从“相关网址”上直接下载,若用于科研等,请引用该作者的论文,遵守相关协议即可。
召回率、准确率、ROC曲线、AUC、PR曲线
对于这些概念的理解,我们首先来认识4个指标。
- TP(True Positive):将正类预测为正类
- TN(True Negative):将负类预测为负类
- False Positive(FP) : 将负类预测为了正类
- False Negative(FN) : 将正类预测为了负类
对于上述四个指标,我们可以建立混淆度矩阵来进行表示。

对于分类模型,我们希望越准越好。对应到混淆矩阵中,TP与TN的数量越大越好,而FP与FN的数量越小越好。当我们得到了模型的混淆矩阵后,就需要去看有多少观测值在第二、四象限对应的位置,这里的数值越多越好;反之,在第一、三四象限对应位置出现的观测值越少越好。
准确率(Accuracy)
准确率指,所有判断正确的结果占总观测值的比重。

精确率(Precision)
精确率指,在所有预测为positive的结果中,预测正确的比重。

召回率(Recall)
召回率指,在所有真实值为positive的结果中,预测正确的比重。

F1值
F1值是精确率和召回率的调和平均数(各变量倒数算术平均数的倒数)
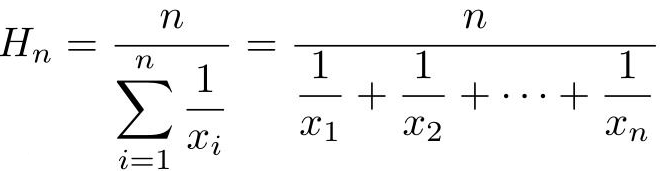
F1值的计算如下

ROC曲线、AUC、PR曲线
待续…














 2424
2424











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









