









 本文探讨了深度学习中的关键概念,如critical point和saddle point,如何影响梯度行为。介绍了如何通过Adagrad和Adam方法避免二次微分成本,以及学习率更新策略,包括warmup的概念。特别提到了梯度爆炸问题及其解决方案。视频资源提供详细解释和实操演示。
本文探讨了深度学习中的关键概念,如critical point和saddle point,如何影响梯度行为。介绍了如何通过Adagrad和Adam方法避免二次微分成本,以及学习率更新策略,包括warmup的概念。特别提到了梯度爆炸问题及其解决方案。视频资源提供详细解释和实操演示。
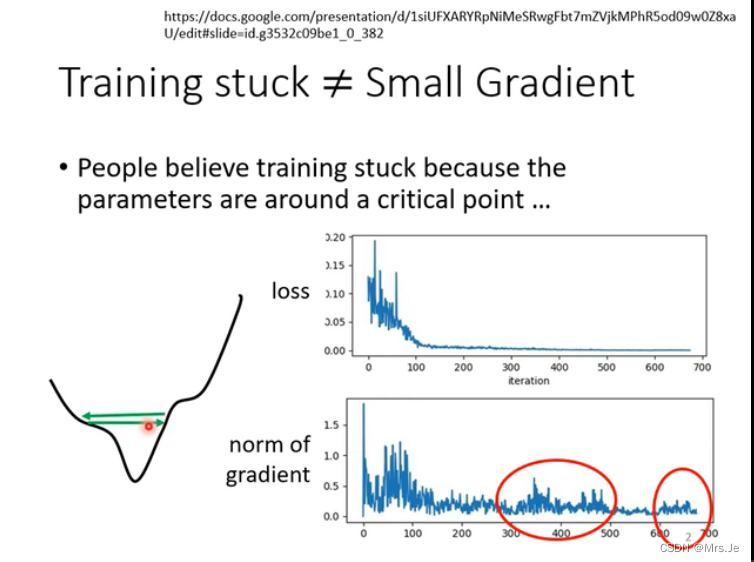
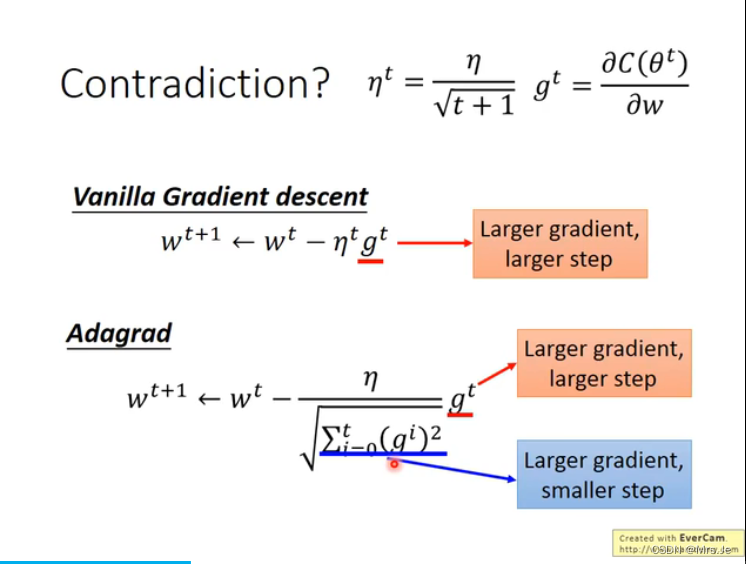
当到达critical point或者saddle point,loss不再下降时,gradient应该为0,但不为0
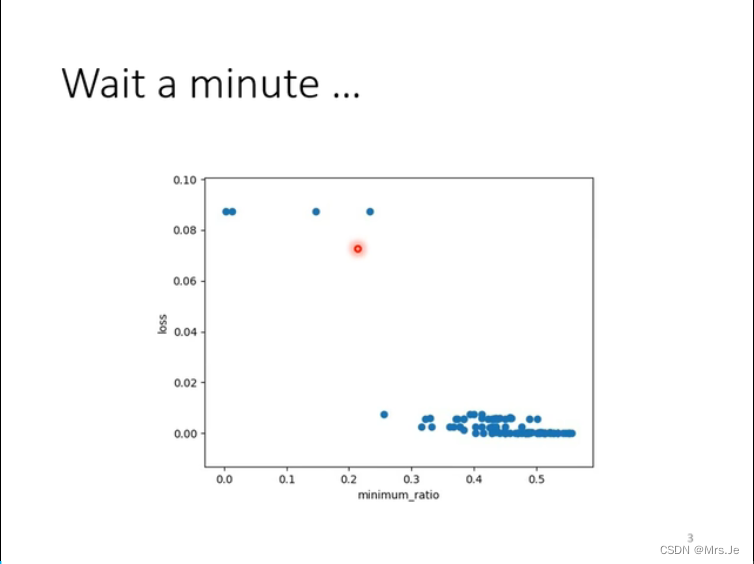
到达critical point或者saddle point很难
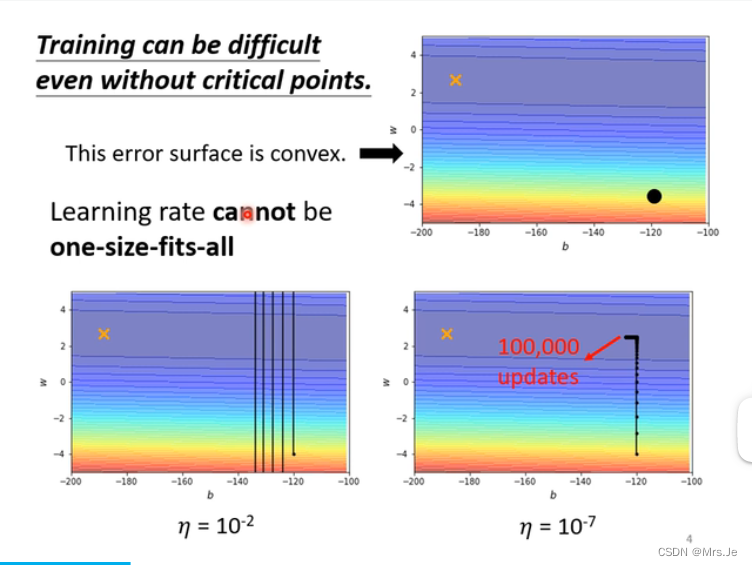
更新learning rate的一种方法:

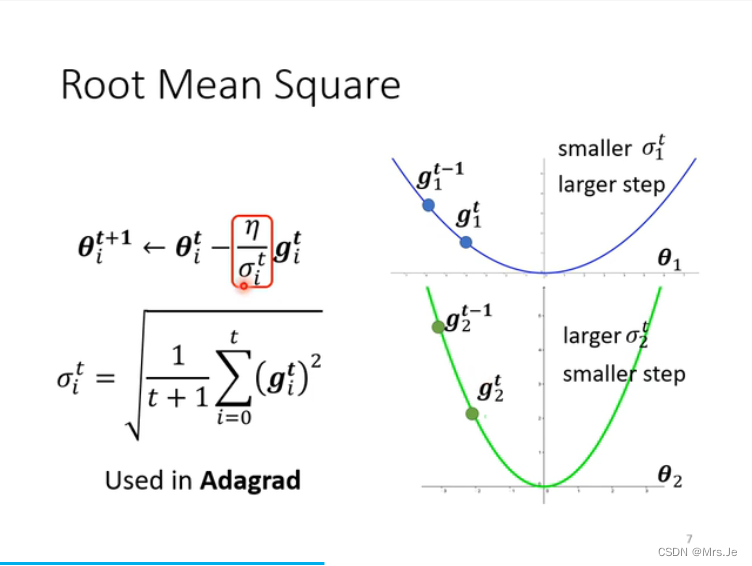
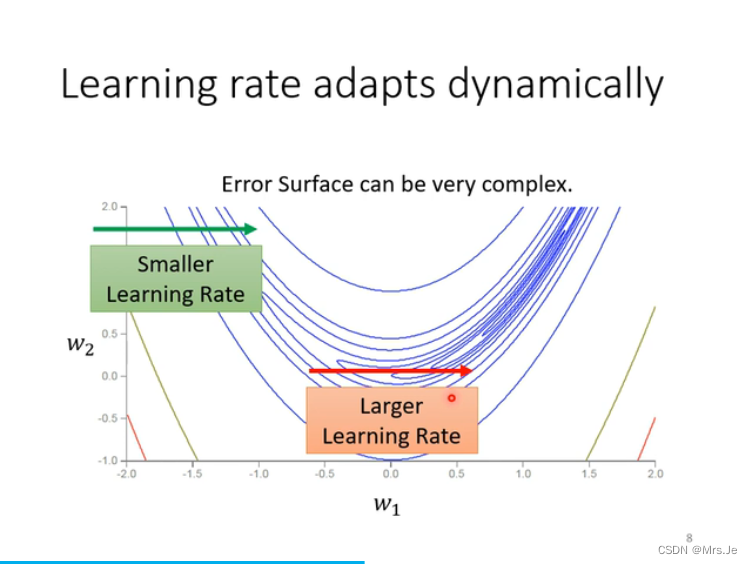
更新learning rate

视频:
https://www.bilibili.com/video/BV1Ht411g7Ef?p=6
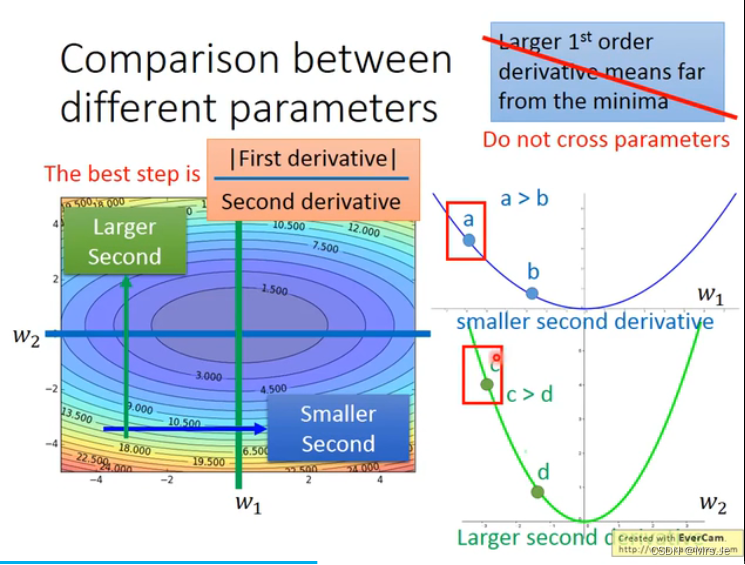
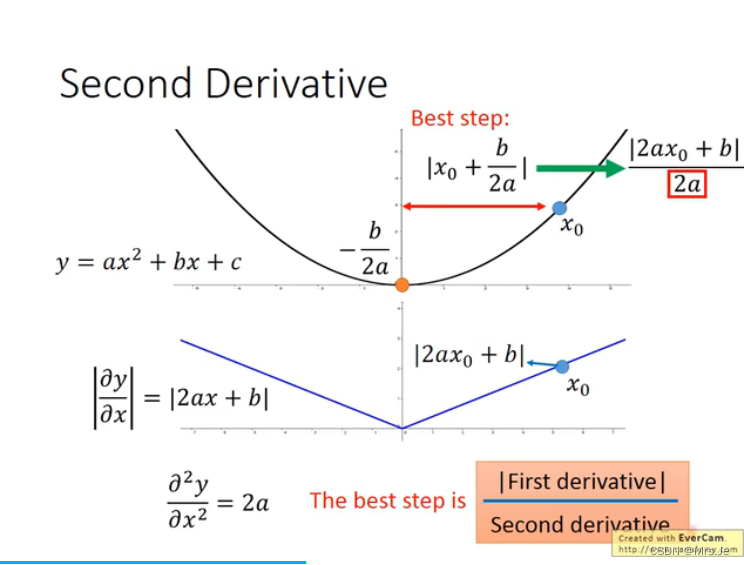
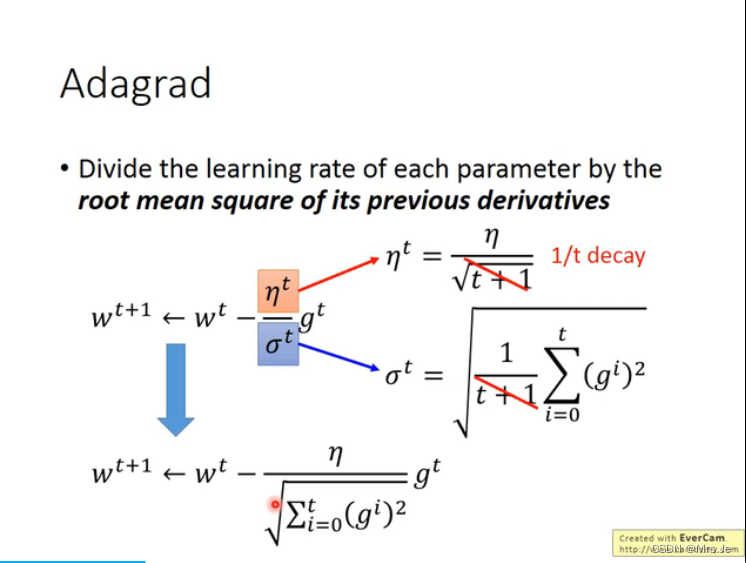
最好的step=(一次微分)/(二次微分),但因为求二次微分代价比较大,所以会有例如adagrad这样的梯度下降方法避免求二次微分
另一种方法:

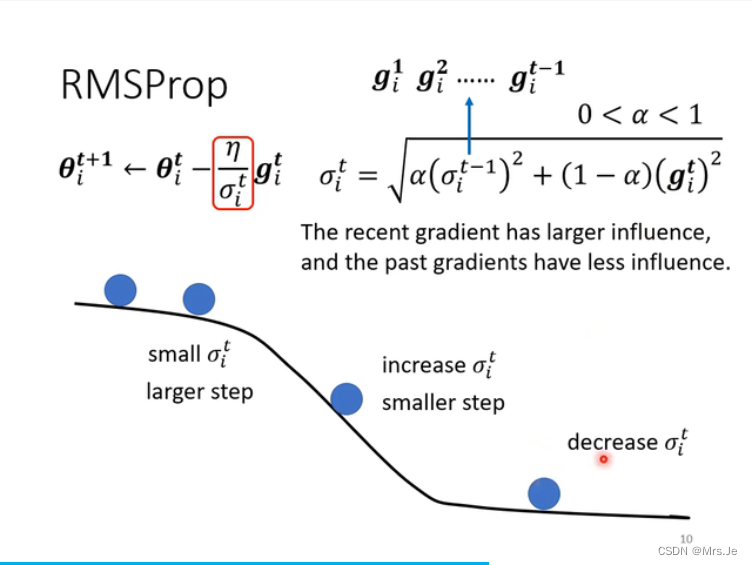
梯度下降的方法——Adam

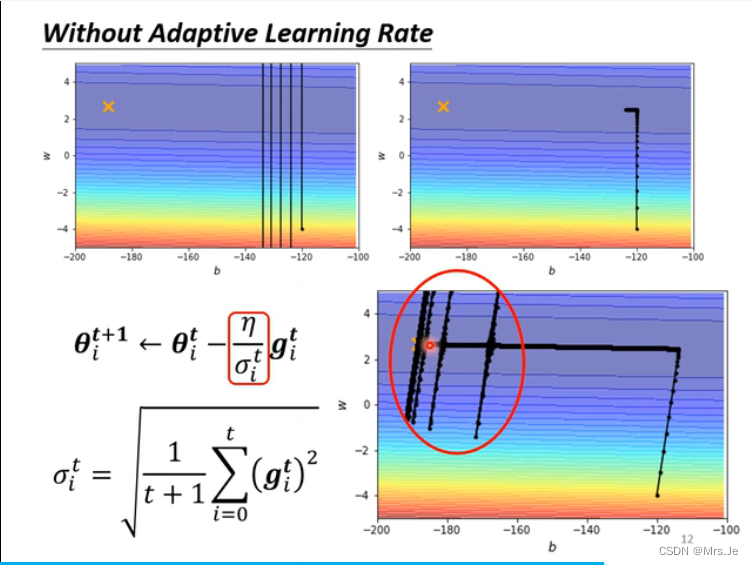
在垂直方向上gradient很小,垂直方向上step近似等于0,累积一段时间后,很小的σ被除,产生梯度爆炸
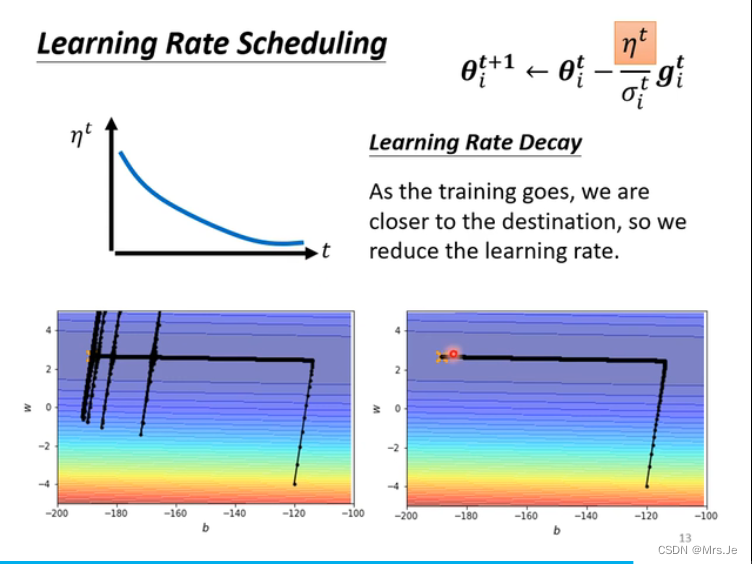
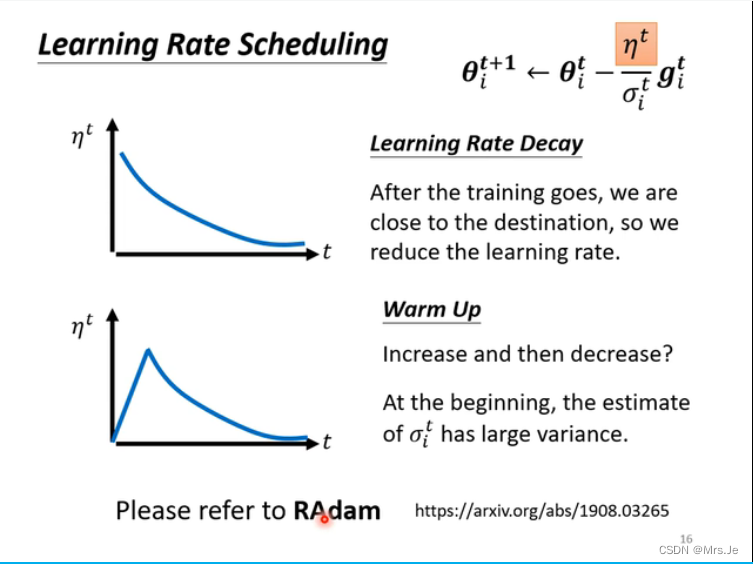
为什么要用warm up?
因为刚开始不知道用多大比较好,所以需要从小的learning rate学起

总结:

















 146
146

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









