







https://www.cnblogs.com/yamin/p/7111397.html
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple tensorflow
https://mirrors.tuna.tsinghua.edu.cn/tensorflow/
TensorFlow是一个采用数据流图(data flow graphs),用于数值计算的开源软件库。节点(Nodes)在图中表示数学操作,图中的线(edges)则表示在节点间相互联系的多维数据数组,即张量(tensor)。它灵活的架构让你可以在多种平台上展开计算,例如台式计算机中的一个或多个CPU(或GPU),服务器,移动设备等等。TensorFlow 最初由Google大脑小组(隶属于Google机器智能研究机构)的研究员和工程师们开发出来,用于机器学习和深度神经网络方面的研究,但这个系统的通用性使其也可广泛用于其他计算领域。
tensor:张量
operation(op):运算操作节点
graph:图
Session:会话
tensor:张量,相当于数组
tensorflow的前后端系统:定义程序的图的机构,后端系统:运算图结构
placeholder提供占位符,run时候通过feed_dict指定参数
张量的阶:

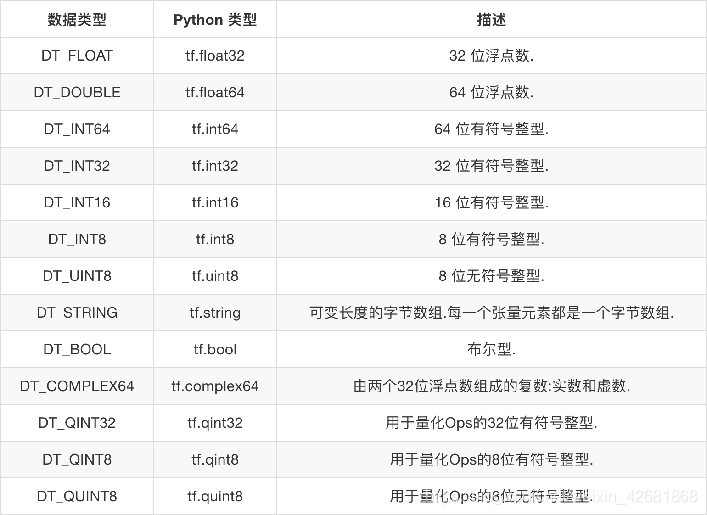
张量的数据类型:
张量属性:
graph 张量所属的默认图
op 张量的操作名
name 张量的字符串描述
shape 张量形状
op
计算图中的每个节点可以有任意多个输入和任意多个输出,每个节点描述了一种运算操作(operation, op),节点可以算作运算操作的实例化(instance)。一种运算操作代表了一种类型的抽象运算,比如矩阵乘法、加法。tensorflow内建了很多种运算操作,如下表所示:
| 类型 | 示例 |
|---|---|
| 标量运算 | Add、Sub、Mul、Div、Exp、Log、Greater、Less、Equal |
| 向量运算 | Concat、Slice、Splot、Constant、Rank、Shape、Shuffle |
| 矩阵运算 | Matmul、MatrixInverse、MatrixDeterminant |
| 带状态的运算 | Variable、Assign、AssignAdd |
| 神经网络组件 | SoftMax、Sigmoid、ReLU、Convolution2D、MaxPooling |
| 存储、恢复 | Save、Restore |
| 队列及同步运算 | Enqueue、Dequeue、MutexAcquire、MutexRelease |
| 控制流 | Merge、Switch、Enter、Leave、NextIteration |
x.initializer # 对x做初始化,即赋值为初始值[2, 3]
x.value() # 获取x的值
x.assign(...) # 赋值操作
x.assign_add(...) # 加法操作
TensorFlow中,张量具有静态形状和动态形状
静态形状:(把原来的改了)
创建一个张量或者由操作推导出一个张量时,初始状态的形状 tf.Tensor.get_shape:获取静态形状 tf.Tensor.set_shape():更新Tensor对象的静态形状,通常用于在不能直接推断的情况下。
对于静态来说,确定了形态之后就不能修改了。set_shape
动态形状:(新建一个张量)
一种描述原始张量在执行过程中的一种形状 tf.reshape:创建一个具有不同动态形状的新张量.tf.reshape(原数据,新形状) (这个reshape和numpy不一样,是生成一个新的张量,不改变原来的张量)(需要注意元素数量要匹配)
张量操作:生成张量
创建随机张量
创建随机张量:
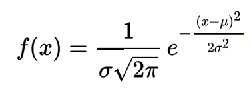
概率密度函数为正态分布的期望值μ决定了其位置,其标准差σ
决定了分布的幅度。当μ = 0,σ = 1时的正态分布是标准正态分布。
从截断的正态分布中输出随机值,和 tf.random_normal() 一样,但是所有数字都不超过两个标准差
tf.truncated_normal(shape, mean=0.0, stddev=1.0, dtype=tf.float32, seed=None, name=None)
从正态分布中输出随机值,由随机正态分布的数字组成的矩阵
tf.random_normal(shape, mean=0.0, stddev=1.0, dtype=tf.float32, seed=None, name=None)
例:
#正态分布的 4X4X4 三维矩阵,平均值 0, 标准差 1
normal = tf.truncated_normal([4, 4, 4], mean=0.0, stddev=1.0)
a = tf.Variable(tf.random_normal([2,2],seed=1)) #这里的Variable不是一个op,所以不能直接run,需要先初始化。(一般小写的动作是op,大写的是类)
b = tf.Variable(tf.truncated_normal([2,2],seed=2))
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
print(sess.run(a))
print(sess.run(b))
从均匀分布输出随机值。生成的值遵循该范围内的均匀分布 [minval, maxval)。下限minval包含在范围内,而maxval排除上限。tf.random_uniform(shape, minval=0.0, maxval=1.0, dtype=tf.float32, seed=None, name=None)
例:
a = tf.random_uniform([2,3],1,10)
with tf.Session() as sess:
print(sess.run(a))


切片与扩展
tf.concat(values, axis, name=‘concat’)
提供给Tensor运算的数学函数:
https://www.tensorflow.org/versions/r1.0/api_guides/python/math_ops
变量(变量也是op,是一种特殊的张量)
其实变量的作用在语言中相当,都有存储一些临时值的作用或者长久存储(普通张量不能长久储存)。在Tensorflow中当训练模型时,用变量来存储和更新参数。变量包含张量(Tensor)存放于内存的缓存区。建模时它们需要被明确地初始化,模型训练后它们必须被存储到磁盘。值可在之后模型训练和分析是被加载。
变量的创建:
x = tf.Variable(5.0,name=“x”)
在使用会话中使用变量之前,必须先在会话外初始化全局变量,并在会话中先run这个全局变量的初始化
属性:
assign(value) 为变量分配一个新值
x = tf.Variable(5.0,name="x")
w.assign(w + 1.0)
返回新值 eval(session=None) 计算并返回此变量的值
v = tf.Variable([1, 2])
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
# 指定会话
print(v.eval(sess))
# 使用默认会话
print(v.eval())
name属性表示变量名字
可视化
数据序列化-events文件
TensorBoard 通过读取 TensorFlow 的事件文件来运行
tf.summary.FileWriter(’/tmp/tensorflow/summary/test/’, graph=
default_graph)
返回filewriter,写入事件文件到指定目录(最好用绝对路径),以提供给tensorboard使用
在终端中输入tensorboard --logdir="路径" ,并在得到的本地网址用浏览器打开
图中的符号意义:

增加变量显示
观察模型的参数、损失值等变量值的变化
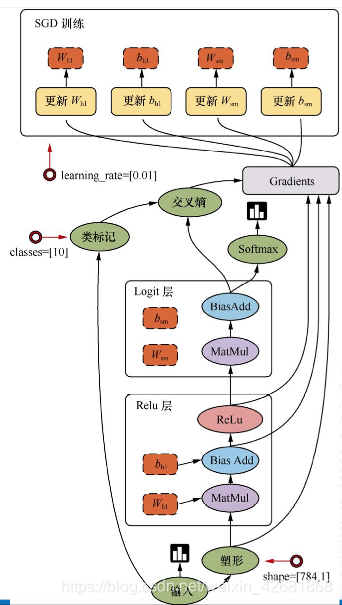
例:线性回归的过程显示
#算法:线性回归,策略:均方误差,优化:梯度下降
#1.准备数据:x为1-100 的100个数,y = 0.8x +0.7
#特征数量为1个,所以需要1个权重w和1个偏置b
#2建立模型 随机初始化一个权重w,一个偏置b , y_predict =mx + b
#3求损失函数 [(y1-y1’)^2 …(y100-y100’)2]0.5/100
#4梯度下降法求损失过程,指定学习率
def mylineregress():
#算法:线性回归,策略:均方误差,优化:梯度下降
with tf.variable_scope("data"):
#1.准备数据:x为1-100 的100个数,y = 0.8x +0.7
x = tf.random_normal([100,1],mean=0,stddev=1,name='x_data')
#特征数量为1个,所以需要1个权重w和1个偏置b
y_true = tf.matmul(x, [[0.7]]) + 0.8
with tf.variable_scope("model"):
#2建立模型 随机初始化一个权重w,一个偏置b , y_predict =mx + b
weight = tf.Variable(tf.random_normal([1,1],mean=0,stddev=1),name='w')
bias = tf.Variable(0.0,name='b')
y_predict = tf.matmul(x,weight) +bias
with tf.variable_scope("optimizer"):
#3求损失函数 [(y1-y1')^2 ......(y100-y100')^2]^0.5/100
loss = tf.reduce_mean(tf.square(y_predict-y_true))
#4梯度下降法求损失过程,指定学习率
train_op = tf.train.GradientDescentOptimizer(0.1).minimize(loss)
#定义一个初始化变量的op
op_init = tf.global_variables_initializer()
#通过会话运行程序
with tf.Session() as sess:
#初始化变量
sess.run(op_init)
#打印随机初始化的变量的权重和偏执
print("随机初始化的权重为:%f ,偏置为%f"%(weight.eval(),bias.eval()))
#建立实践文件
filwriter = tf.summary.FileWriter("D:\\pycharm\\program\pro\\tensorflow\\summary",graph=sess.graph)
#循环训练
for i in range(100):
#运行优化op
sess.run(train_op)
print("梯度下降后第%d的权重为:%f ,偏置为%f" % (i,weight.eval(), bias.eval()))
return None
Tensorflow运算API:
矩阵运算tf.matmul(x, w)
平方tf.square(error)
均值tf.reduce_mean(error)
tf.train.GradientDescentOptimizer(learning_rate)
梯度下降优化
learning_rate:学习率,一般为
method:
return:梯度下降op
作用域:让模型的图片更加清晰简单with tf.variable_scope("data")
收集变量
tf.summary.scalar(name=’’,tensor) 收集对于损失函数和准确率
等单值变量,name为变量的名字,tensor为值
tf.summary.histogram(name=‘’,tensor) 收集高维度的变量参数
tf.summary.image(name=‘’,tensor) 收集输入的图片张量能显示图片
合并变量写入事件文件
merged = tf.summary.merge_all()
运行合并:summary = sess.run(merged),每次迭代都需运行
添加:FileWriter.add_summary(summary,i),i表示第几次的值
模型保存和加载:
tf.train.Saver(var_list=None,max_to_keep=5)
var_list:指定将要保存和还原的变量。它可以作为一个
dict或一个列表传递.
max_to_keep:指示要保留的最近检查点文件的最大数量。
创建新文件时,会删除较旧的文件。如果无或0,则保留所有
检查点文件。默认为5(即保留最新的5个检查点文件。)
例如:saver.save(sess, ‘/tmp/ckpt/test/model’) (保存)
saver.restore(sess, ‘/tmp/ckpt/test/model’) (加载,覆盖模型中的训练参数)
自定义命令行参数
 tf.app.flags.,在flags有一个FLAGS标志,它在程序中可以调用到我们
tf.app.flags.,在flags有一个FLAGS标志,它在程序中可以调用到我们
前面具体定义的flag_name
通过tf.app.run()启动main(argv)函数
IO操作和线程队列:
Tensorflow队列:
1.在训练样本的时候,希望读入的训练样本时有序的
2.tf.FIFOQueue 先进先出队列,按顺序出队列
3.tf.RandomShuffleQueue 随机出队列
tf.FIFOQueue
FIFOQueue(capacity, dtypes, name=‘fifo_queue’) 创建一个以先进先出的顺序对元素进行排队的队列
capacity:整数。可能存储在此队列中的元素数量的上限
dtypes:DType对象列表。长度dtypes必须等于每个队列元
素中的张量数,dtype的类型形状,决定了后面进队列元素形状
method
dequeue(name=None)
enqueue(vals, name=None):
enqueue_many(vals, name=None):vals列表或者元组
返回一个进队列操作
size(name=None)
文件读取:
FIFOQueue 队列
tf.QueueRunner:
QueueRunner类会创建一组线程, 这些线程可以重复的执行Enquene操作, 他们使用同一个Coordinator来处理线程同步终止。此外,一个QueueRunner会运行一个closer thread,当Coordinator收到异常报告时,这个closer thread会自动关闭队列。
tf.train.QueueRunner(queue, enqueue_ops=None)
创建一个QueueRunner
queue:A Queue
enqueue_ops:添加线程的队列操作列表,[]*2,指定两个线程
create_threads(sess, coord=None,start=False)
创建线程来运行给定会话的入队操作
start:布尔值,如果True启动线程;如果为False调用者
必须调用start()启动线程
coord:线程协调器,后面线程管理需要用到
return:
tf.Coordinator:
Coordinator类用来帮助多个线程协同工作,多个线程同步终止。 其主要方法有:
should_stop():如果线程应该停止则返回True。
request_stop(): 请求该线程停止。
join():等待被指定的线程终止。
首先创建一个Coordinator对象,然后建立一些使用Coordinator对象的线程。这些线程通常一直循环运行,一直到should_stop()返回True时停止。 任何线程都可以决定计算什么时候应该停止。它只需要调用request_stop(),同时其他线程的should_stop()将会返回True,然后都停下来。
例:
def queue():
#主线程,不断去取数据
#主线程结束了,队列线程还没有结束,就会抛出异常
#主线程没有结束,需要将队列线程关闭,防止主线程等待
Q = tf.FIFOQueue(1000,dtypes=tf.float32)
#定义操作
var = tf.Variable(0.0)
increment_op = tf.assign_add(var,tf.constant(1.0))
en_op = Q.enqueue(increment_op)
#创建一个队列管理器,指定线程数,执行队列操作
qr =tf.train.QueueRunner(Q,enqueue_ops=[en_op,increment_op]*3)
with tf.Session() as sess:
tf.global_variables_initializer().run()
#生成一个线程协调器
coord = tf.train.Coordinator()
#启动线程执行操作
threading_list = qr.create_threads(sess,coord=coord,start=True)
print(len(threading_list), "----------")
#主线程去除数据
for i in range(20):
print(sess.run(Q.dequeue()))
#请求其他线程终止
coord.request_stop()
#关闭线程
coord.join(threading_list)
读取少量数据:
存储在常数中:
training_data = ...
training_labels = ...
with tf.Session():
input_data = tf.constant(training_data)
input_labels = tf.constant(training_labels)
存储在变量中:需要在数据流图建立后初始化这个变量
training_data = ...
training_labels = ...
with tf.Session() as sess:
data_initializer = tf.placeholder(dtype=training_data.dtype,
shape=training_data.shape)
label_initializer = tf.placeholder(dtype=training_labels.dtype,
shape=training_labels.shape)
input_data = tf.Variable(data_initalizer, trainable=False, collections=[])
input_labels = tf.Variable(label_initalizer, trainable=False, collections=[])
...
sess.run(input_data.initializer,
feed_dict={data_initializer: training_data})
sess.run(input_labels.initializer,
feed_dict={label_initializer: training_lables})
文件读取
将文件名列表交给tf.train.string_input_producer函数。string_input_producer来生成一个先入先出的队列,文件阅读器会需要它们来取数据。string_input_producer提供的可配置参数来设置文件名乱序和最大的训练迭代数,QueueRunner会为每次迭代(epoch)将所有的文件名加入文件名队列中,如果shuffle=True的话,会对文件名进行乱序处理。一过程是比较均匀的,因此它可以产生均衡的文件名队列
这个QueueRunner工作线程是独立于文件阅读器的线程,因此乱序和将文件名推入到文件名队列这些过程不会阻塞文件阅读器运行。根据你的文件格式,选择对应的文件阅读器,然后将文件名队列提供给阅读器的 read 方法。阅读器的read方法会输出一个键来表征输入的文件和其中纪录(对于调试非常有用),同时得到一个字符串标量,这个字符串标量可以被一个或多个解析器,或者转换操作将其解码为张量并且构造成为样本。
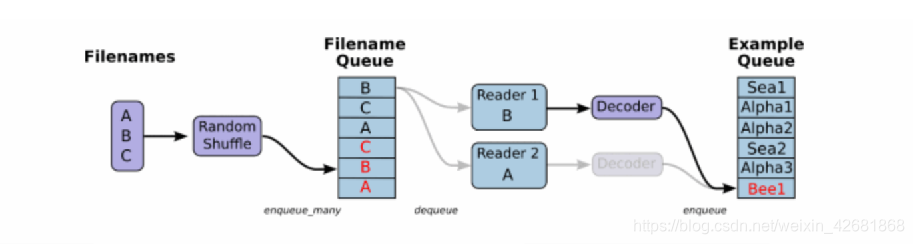
1.文件读取API-文件队列构造:
tf.train.string_input_producer(string_tensor,shuffle=True)将输出字符串(例如文件名)输入到管道队列
string_tensor :含有文件名的1阶张量
num_epochs :过几遍数据,默认无限过数据
return : 具有输出字符串的队列
2.文件读取API-文件阅读器(读取一行)
根据文件格式,选择对应的文件阅读器
class tf.TextLineReader
阅读文本文件逗号分隔值(CSV)格式,默认按行读取
return:读取器实例
tf.FixedLengthRecordReader(record_bytes) (指定一个样本的bites读取)
要读取每个记录是固定数量字节的二进制文件
record_bytes:整型,指定每次读取的字节数
return:读取器实例
tf.TFRecordReader
读取TfRecords文件
3.文件读取API-文件内容解码器:(按一张一张的读取)
由于从文件中读取的是字符串,需要函数去解析这些字符串到张量
tf.decode_csv(records,record_defaults=None,field_delim = None,name = None)
将CSV转换为张量,与tf.TextLineReader搭配使用
records:tensor型字符串,每个字符串是csv中的记录行
field_delim:默认分割符”,”
record_defaults:参数决定了所得张量的类型,并设置一个值在输入字符串中缺少使用默认值,如
tf.decode_raw(bytes,out_type,little_endian = None,name = None)
将字节转换为一个数字向量表示,字节为一字符串类型的张量,与函数tf.FixedLengthRecordReader搭配使用,二进制读取为uint8格式
4.批处理
tf.train.batch(tensors,batch_size,num_threads = 1,capacity = 32,name=None)
读取指定大小(个数)的张量
tensors:可以是包含张量的列表
batch_size:从队列中读取的批处理大小
num_threads:进入队列的线程数
capacity:整数,队列中元素的最大数量
return:tensors
tf.train.shuffle_batch(tensors,batch_size,capacity,min_after_dequeue, num_threads=1,)
乱序读取指定大小(个数)的张量
min_after_dequeue:留下队列里的张量个数,能够保持随机打乱
例:
def csv_read(file_list):
'''
#读取csv文件
#1.构建文件读取队列
#2.构建读取器,读取内容
#3.解码内容
#4.现处理一个内容,如果需要就批处理内容
'''
#1:构造文件队列:# tf.train.string_input_producer(string_tensor,,shuffle=True)
file_queue = tf.train.string_input_producer(file_list) #这里返回的是一个队列
#2:读取class tf.TextLineReader 等。(返回值是key(文件名),value(一个样本))
reader = tf.TextLineReader() #先构造一个阅读器
key,value = reader.read(file_queue) #这里的key是文件名,value是第一个样本数据
#3解码文件,tf.decode_csv(records,record_defaults=None,field_delim = None,name = None) 将csv文件转化为张量
q,w,e =tf.decode_csv(value,record_defaults=[[1],[1],[1]]) #record_defaults指定每一个样本的每一列的类型(默认值的类型),并指定默认值
#4批处理 管道读端批处理tf.train.batch(tensors,batch_size=一批次的样本数量,num_threads =1,capacity =10(无影响),name=None) tensors可以是列表
q_batch,w_batch,e_batch = tf.train.batch([q,w,e],batch_size=10,num_threads=1,capacity=5)
#开启会话运行结果
with tf.Session() as sess:
coord = tf.train.Coordinator() #建立线程协调器
thread = tf.train.start_queue_runners(sess,coord=coord) #开启线程
#打印读取的内容
print(sess.run([q,w,e]))
print(sess.run([q_batch,w_batch,e_batch]))
#回收子线程
coord.request_stop()
coord.join(thread)
pass
if __name__ == '__main__':
file_name = os.listdir('./csvdata')
file_list = [os.path.join('./csvdata',file) for file in file_name]
csv_read(file_list)
读取图片
在图像数字化表示当中,分为黑白和彩色两种。在数字化表示图片的时候,有三个因素。分别是图片的长、图片的宽、图片的颜色通道数。那么黑白图片的颜色通道数为1,它只需要一个数字就可以表示一个像素位;而彩色照片就不一样了,它有三个颜色通道,分别为RGB,通过三个数字表示一个像素位。TensorFlow支持JPG、PNG图像格式,RGB、RGBA颜色空间。图像用与图像尺寸相同(heightwidthchnanel)张量表示。图像所有像素存在磁盘文件,需要被加载到内存。
图像基本操作:
目的:
1、增加图片数据的统一性
2、所有图片转换成指定大小
3、缩小图片数据量,防止增加开销
操作:
1、缩小图片大小
tf.image.resize_images(images, size)
缩小图片
images:4-D形状[batch, height, width, channels]或3-D形状的张
量[height, width, channels]的图片数据
size:1-D int32张量:new_height, new_width,图像的新尺寸
返回4-D格式或者3-D格式图片
图像读取API:
图像读取器
tf.WholeFileReader 将文件的全部内容作为值输出的读取器
return:读取器实例
read(file_queue):输出将是一个文件名(key)和该文件的内容(值)
图像解码器:
tf.image.decode_jpeg(contents)
将JPEG编码的图像解码为uint8张量
return:uint8张量,3-D形状[height, width, channels]
tf.image.decode_png(contents)
将PNG编码的图像解码为uint8或uint16张量
return:张量类型,3-D形状[height, width, channels]
例:
import tensorflow as tf
import os
def read_iamge(filenamelist):
# 读取jpg文件
# 1.构建文件读取队列
# 2.构建读取器,读取图片内容,默认是一张
# 3.解码内容
# 4.现处理一个内容,如果需要就批处理内容。如统一大小
#创建文件队列:
file_queue = tf.train.string_input_producer(filenamelist,shuffle=False)
#构建阅读器,读取图片内容
reader = tf.WholeFileReader() #实例化阅读器 ,
key,value = reader.read(file_queue) #默认读取一张图片
#解码内容
image = tf.image.decode_jpeg(value) #解码得到unit8格式的三阶张量
#统一图片大小:
image_resize = tf.image.resize_images(image,[200,200])
print(image_resize)
#注意:一定要把样本形状固定 (批处理要求所有数据形状统一)
image_resize.set_shape([200,200,3])
print(image_resize)
#通过tf.tarin.batch来批处理数据
# image_batch = tf.train.batch([image_resize], batch_size=4, num_threads=1, capacity=9)
with tf.Session() as sess:
#线程协调员
coord = tf.train.Coordinator()
#启动工作线程
thread = tf.train.start_queue_runners(sess,coord=coord)
print(sess.run([image_resize]))
#打印批处理数据
# print(sess.run([example_batch,label_batch]))
coord.request_stop()
coord.join(thread)
pass
if __name__ == '__main__':
filename = os.listdir('./dog_images')
filenamelist = [os.path.join('./dog_images',file) for file in filename]
read_iamge(filenamelist)
二进制文件的读取
TFRecords是Tensorflow设计的一种内置文件格式,是一种二进制文件,
它能更好的利用内存,更方便复制和移动
CIFAR-10 文件下载
https://www.cs.toronto.edu/~kriz/cifar.html
该文件格式:
二进制版
二进制版本包含文件data_batch_1.bin,data_batch_2.bin,…,data_batch_5.bin以及test_batch.bin。每个文件的格式如下:<1 x label> <3072 x pixel>
…<1 x label> <3072 x pixel>
换句话说,第一个字节是第一个图像的标签,它是0-9范围内的数字。接下来的3072个字节是图像像素的值。前1024个字节是红色通道值,下一个1024是绿色,最后1024个是蓝色。值以行主顺序存储,因此前32个字节是图像第一行的红色通道值。
每个文件包含10000个这样的3073字节“行”图像,尽管没有划分行的任何内容。因此,每个文件应该是30730000字节长。
还有另一个名为batches.meta.txt的文件。这是一个ASCII文件,它将0-9范围内的数字标签映射到有意义的类名。它只是10个类名的列表,每行一个。第i行上的类名对应于数字标签i。
例:
import tensorflow as tf
import os
# #定义cifar的数据的命令行参数
# FLAGS = tf.app.flags.run
# tf.app.flags.DEFINE_string('cifar_dir','./dog_bin/','解释:这个是文件目录')
class read_cifar(object):
"""完成读取二进制文件,写进tfrecords,读取tfrecords"""
def __init__(self,filelist):
self.file_list = filelist
#定义读取图片的属性
self.height = 32
self.width = 32
self.channel = 3
#每张图片的字节数
self.label = 1
self.image = self.height * self.width * self.channel
self.bites = self.label + self.image
def read_and_decode(self):
'''
1构造文件队列
2建立读取器,读取内容
3解码内容
'''
#1构建文件队列
file_queue = tf.train.string_input_producer(self.file_list)
#2建立阅读器,每个样本的字节数
reader = tf.FixedLengthRecordReader(self.bites) #输入一个图片的字节数作为读取的一行(一个样本)
#3读取文件
key,value = reader.read(file_queue)
#4解码内容
label_image = tf.decode_raw(value,tf.uint8)
#5分割出图片和标签数据
label = tf.slice(label_image,[0],[self.label])
image = tf.slice(label_image,[self.label],[self.image])
#5 对图片特征数据进行形状改变 [3072] --> [32,32,3]
image_reshape = tf.reshape(image,[self.height,self.width,self.channel])
#6 批处理数据
image_batch,label_batch = tf.train.batch([image_reshape,label],batch_size=10 , num_threads=1,capacity=10)
#开启会话运行结果
with tf.Session() as sess:
#开启线程
coord = tf.train.Coordinator()
thread = tf.train.start_queue_runners(sess,coord=coord)
#打印读取内容
print(sess.run(image_batch))
print(sess.run(label_batch))
#回收线程
coord.request_stop()
coord.join(thread)
pass
if __name__ == '__main__':
#1找到文件,放入列表
filename = os.listdir('./cifar-10\cifar-10-batches-py')
filelist = [os.path.join('cifar-10\cifar-10-batches-py',file) for file in filename if file[-3:] == 'bin']
print(filelist)
rc = read_cifar(filelist)
rc.read_and_decode()
TFrecords文件的存储
TFRecords存储:
1、建立TFRecord存储器 tf.python_io.TFRecordWriter(path) 写入tfrecords文件
path: TFRecords文件的路径
return:写文件 method write(record):向文件中写入一个字符串记录
close():关闭文件写入器 注:字符串为一个序列化的Example,Example.SerializeToString()
2、构造每个样本的Example协议块 tf.train.Example(features=None) 写入tfrecords文件
tf.train.Example(features=None) :
写入tfrecords文件
features:tf.train.Features类型的特征实例
return:example格式协议块
tf.train.Features(feature=None) :
构建每个样本的信息键值对
feature:字典数据,key为要保存的名字,
value为tf.train.Feature实例
return:Features类型
tf.train.Feature(options) :
**options:例如
bytes_list=tf.train. BytesList(value=[Bytes])
int64_list=tf.train. Int64List(value=[Value])
tf.train. Int64List(value=[Value])
tf.train. BytesList(value=[Bytes])
tf.train. FloatList(value=[value])














 426
426











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









