







Kaggle猫狗大战——基于Pytorch的CNN网络分类:预测模型结果(4)
本文是Kaggle猫狗大战项目的最后一步了,写一个predict.py,在命令行输入随便找的猫狗图片,使用训练好的模型进行预测。这块比较简单,就话不多说,直接上代码。
predict.py
import sys
import torch
import os
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
from PIL import Image
def predict(dir):
model = torch.load('best_model.pt') # 载入模型
model.train(False) # 模型设定为train(false)模式
test_transforms = transforms.Compose([
transforms.Resize(224), # 图像短边长度变为input_size
transforms.CenterCrop(224), # 从正中间剪正方形
transforms.ToTensor(),
transforms.Normalize([0.4864, 0.4533, 0.4154], [0.2625, 0.2558, 0.2586])
])
img_PIL = Image.open(dir) # 打开文件路径
image_tensor = test_transforms(img_PIL) # 将图片文件转换为tensor文件
image_tensor.unsqueeze_(0)
image_tensor = image_tensor.to(device) # 由CPU.tensor文件转换为GPU.tensor文件
out = model(image_tensor) # 得到预测结果,并且从大到小排序
_,indices = torch.sort(out, descending=True) # 返回每个预测的百分数
print(['The given picture is '+(class_names[idx]) for idx in indices[0][:1]])
if __name__ == '__main__':
order = sys.argv[1] # 从命令行获取图片名
test_dir = ('../test/'+order) # 组合图片路径
class_names = ['cat','dog']
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
predict(test_dir)
unsqueeze函数
预测程序的代码非常简单,也很好理解,我就都已标注的形式写在了文件里。唯一让我比较迷惑的就是image_tensor.unsqueeze_(0)这一步,没有会报错,所以特意去查了一下。
unsqueeze()函数和squeeze()函数是一对函数,作用是对张量Tensor的维度进行压缩或者扩充。我对tensor的理解就是pytorch中的tensor张量与numpy中的数组相似,因此其维度也很好理解。
例如:a=torch.IntTensor([[1,2,3],[4,5,6]])其维度就是[2,3]。而b = torch.IntTensor([[[1,2,3],[4,5,6]]])其维度是[1,2,3]。(先是一个11的数组,然后是一个23的数组。)正是因为张量b其第0个维度是一维,所以可以对张量b进行压缩,将其压缩成[2,3]的张量。(注意,压缩只能对一维的维度进行,但是膨胀可以随便加在哪儿)。
c=torch.squeeze(b,0)
这样一来,张量c的维度就是[2,3]。同样地,也可以对a进行膨胀操作:
d=torch.unsqueeze(a,0)
如此一来,张量d的维度就是[1,2,3]。
注意,也可以对后面的维度进行操作,比如,e=torch.unsqueeze(a,1),则张量e的维度就是[2,1,3]。
e=([[[0,1,2]],[[3,4,5]]])
下面则是我个人对这里应用该函数的一些看法,因为我们在data.py里面进行数据打包时,每个数据包中都包含了多张图片的数据,而这里是对单张图片进行处理,所以需要在单张图片的张量外再套一层,使其与data.py中的数据包类型相同。
命令行操作
我们的目标是:
(1)将你想识别的图片存到和data同文件夹的test文件夹中;
(2)打开cmd;
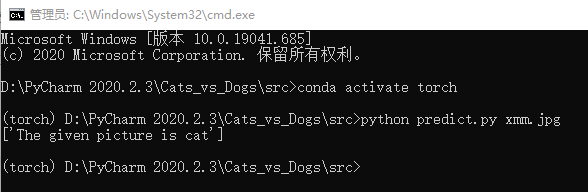
(3)在cmd中输入python predict.py XXX.jpg;(XXX.jpg是你要识别的图片的名字)
(4)cmd中回复:The given picture is cat/dog
操作非常简单,利用order = sys.argv[1]指令就能实现从cmd中读取代码,但是在实操时需要注意一些地方,好多博客中用到了sys.argv,但是直接打开cmd往往无法运行,这是由于位置与环境不对。
第一步,到程序所在文件夹里,在搜索栏(此电脑那一栏)删去其他的,输入cmd,回车;
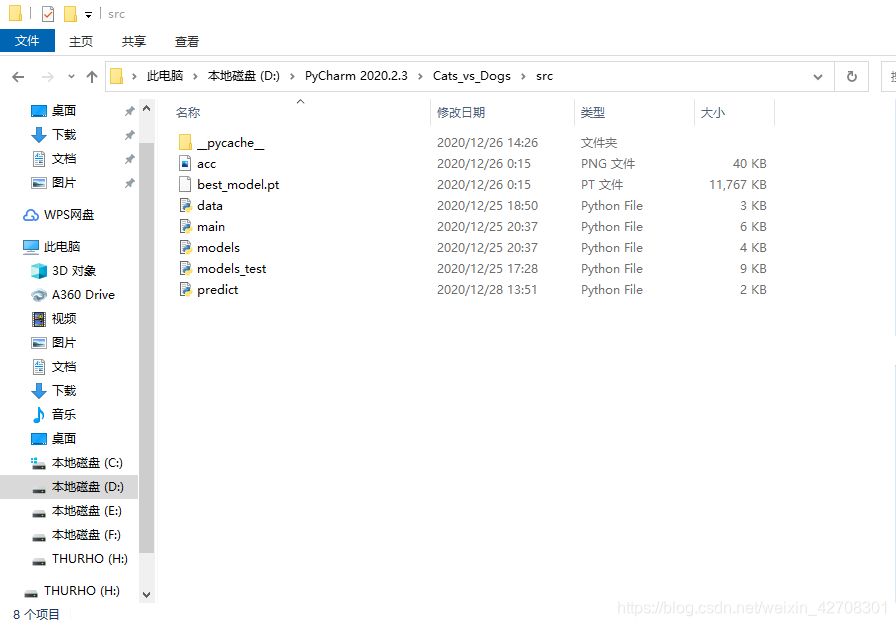 这样一来,跳出来的命令行界面就是这样的:
这样一来,跳出来的命令行界面就是这样的:
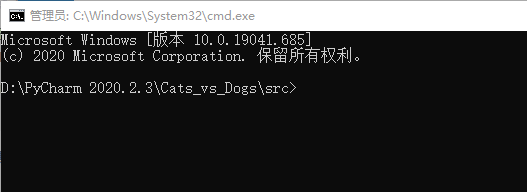
第二步,如果你使用了虚拟环境(基本都会用),激活虚拟环境
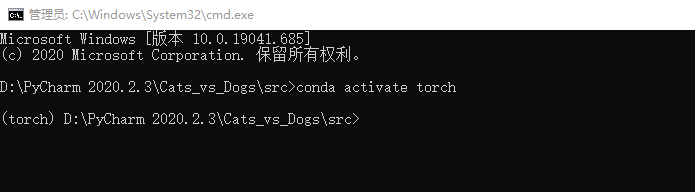
第三步,输入python predict.py XXX.jpg,前面的python predict.py是调用程序的,后面的XXX.jpg使用sys.argv可以直接读取成字符串。














 916
916











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









