







4 非线性支持向量机与核函数
**4.1 非线性分类问题:**如下图所示,通过变换,将椭圆变为直线,非线性分类问题变为了线性分类问题
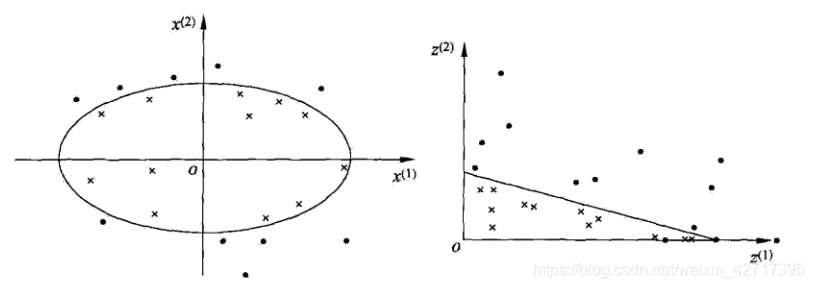
原空间为 X ⊂ R 2 , x = ( x ( 1 ) , x ( 2 ) ) T ∈ X \mathcal{X} \subset \mathbf{R}^{2}, x=\left(x^{(1)}, x^{(2)}\right)^{\mathrm{T}} \in \mathcal{X} X⊂R2,x=(x(1),x(2))T∈X,新空间为 Z ⊂ R 2 , z = ( z ( 1 ) , z ( 2 ) ) T ∈ Z \mathcal{Z} \subset \mathbf{R}^{2}, z=\left(z^{(1)}, z^{(2)}\right)^{\mathrm{T}} \in \mathcal{Z} Z⊂R2,z=(z(1),z(2))T∈Z,从原空间到新空间的变换(映射)为: z = ϕ ( x ) = ( ( x ( 1 ) ) 2 , ( x ( 2 ) ) 2 ) T z=\phi(x)=\left(\left(x^{(1)}\right)^{2},\left(x^{(2)}\right)^{2}\right)^{\mathrm{T}} z=ϕ(x)=((x(1))2,(x(2))2)T
原空间的椭圆 w 1 ( x ( 1 ) ) 2 + w 2 ( x ( 2 ) ) 2 + b = 0 w_{1}\left(x^{(1)}\right)^{2}+w_{2}\left(x^{(2)}\right)^{2}+b=0 w1(x(1))2+w2(x(2))2+b=0,变为新空间的直线 w 1 z ( 1 ) + w 2 z ( 2 ) + b = 0 w_{1} z^{(1)}+w_{2} z^{(2)}+b=0 w1z(1)+w2z(2)+b=0,在新空间中线性可分
4.2 核技巧:设 X \mathcal{X} X是输入空间(欧氏空间 R n \mathbf{R}^{n} Rn或者离散集合),对应于一个特征空间(希尔伯特空间 H \mathcal{H} H),如果存在一个 X \mathcal{X} X到 H \mathcal{H} H的映射: ϕ ( x ) : X → H \phi(x): \mathcal{X} \rightarrow \mathcal{H} ϕ(x):X→H,使得所有的 x , z ∈ X x, z \in \mathcal{X} x,z∈X,函数 K ( x , z ) K(x, z) K(x,z)满足条件: K ( x , z ) = ϕ ( x ) ⋅ ϕ ( z ) K(x, z)=\phi(x) \cdot \phi(z) K(x,z)=ϕ(x)⋅ϕ(z),则称 K ( x , z ) K(x, z) K(x,z)为核函数, ϕ ( x ) \phi(x) ϕ(x)为映射函数,式中 ϕ ( x ) ⋅ ϕ ( z ) \phi(x) \cdot \phi(z) ϕ(x)⋅ϕ(z)为两者的内积
在学习和预测时只定义核函数 K ( x , z ) K(x, z) K(x,z),不显式定义映射函数 ϕ \phi ϕ,直接计算 K ( x , z ) K(x, z) K(x,z)比较容易,通过 ϕ ( x ) \phi(x) ϕ(x)和 ϕ ( z ) \phi(z) ϕ(z)计算 K ( x , z ) K(x, z) K(x,z)并不容易。对于给定核函数 K ( x , z ) K(x, z) K(x,z),特征空间 H \mathcal{H} H和映射函数 ϕ ( x ) \phi(x) ϕ(x)的取法不唯一
将支持向量机对偶问题目标函数中的内积
x
i
⋅
x
j
x_{i} \cdot x_{j}
xi⋅xj替换为核函数
K
(
x
i
,
x
j
)
=
ϕ
(
x
i
)
⋅
ϕ
(
x
j
)
K\left(x_{i}, x_{j}\right)=\phi\left(x_{i}\right) \cdot \phi\left(x_{j}\right)
K(xi,xj)=ϕ(xi)⋅ϕ(xj),新的目标函数为:
W
(
α
)
=
1
2
∑
i
=
1
N
∑
j
=
1
N
α
i
α
j
y
i
y
j
K
(
x
i
,
x
j
)
−
∑
i
=
1
N
α
i
W(\alpha)=\frac{1}{2} \sum_{i=1}^{N} \sum_{j=1}^{N} \alpha_{i} \alpha_{j} y_{i} y_{j} K\left(x_{i}, x_{j}\right)-\sum_{i=1}^{N} \alpha_{i}
W(α)=21i=1∑Nj=1∑NαiαjyiyjK(xi,xj)−i=1∑Nαi
新的分类决策函数为:
f
(
x
)
=
sign
(
∑
i
=
1
N
s
a
i
∗
y
i
ϕ
(
x
i
)
⋅
ϕ
(
x
)
+
b
∗
)
=
sign
(
∑
i
=
1
N
s
a
i
∗
y
i
K
(
x
i
,
x
)
+
b
∗
)
f(x)=\operatorname{sign}\left(\sum_{i=1}^{N_{s}} a_{i}^{*} y_{i} \phi\left(x_{i}\right) \cdot \phi(x)+b^{*}\right)=\operatorname{sign}\left(\sum_{i=1}^{N_{s}} a_{i}^{*} y_{i} K\left(x_{i}, x\right)+b^{*}\right)
f(x)=sign(i=1∑Nsai∗yiϕ(xi)⋅ϕ(x)+b∗)=sign(i=1∑Nsai∗yiK(xi,x)+b∗)
这样,不需显式定义特征空间和映射函数,隐式地在特征空间中学习;通过线性分类器学习和核函数解决非线性问题
核函数是正定核函数,正定核函数的定义是:设
X
⊂
R
n
\mathcal{X} \subset \mathbf{R}^{n}
X⊂Rn,
K
(
x
,
z
)
K(x, z)
K(x,z)是定义在
X
×
X
\mathcal{X} \times \mathcal{X}
X×X上的对称函数,如果对任意
x
i
∈
X
x_{i} \in \mathcal{X}
xi∈X,
i
=
1
,
2
,
⋯
,
m
i=1,2, \cdots, m
i=1,2,⋯,m,
K
(
x
,
z
)
K(x, z)
K(x,z)对应的Gram矩阵:
K
=
[
K
(
x
i
,
x
j
)
]
m
×
m
K=\left[K\left(x_{i}, x_{j}\right)\right]_{m \times m}
K=[K(xi,xj)]m×m
是半正定矩阵,则称
K
(
x
,
z
)
K(x, z)
K(x,z)是正定核
常用核函数:
-
多项式核函数:
K ( x , z ) = ( x ⋅ z + 1 ) p f ( x ) = sign ( ∑ i = 1 N i a i ∗ y i ( x i ⋅ x + 1 ) p + b ∗ ) K(x, z)=(x \cdot z+1)^{p}\\ f(x)=\operatorname{sign}\left(\sum_{i=1}^{N_{i}} a_{i}^{*} y_{i}\left(x_{i} \cdot x+1\right)^{p}+b^{*}\right) K(x,z)=(x⋅z+1)pf(x)=sign(i=1∑Niai∗yi(xi⋅x+1)p+b∗) -
高斯核函数:
K ( x , z ) = exp ( − ∥ x − z ∥ 2 2 σ 2 ) f ( x ) = sign ( ∑ i = 1 N i a i ∗ y i exp ( − ∥ x − z ∥ 2 2 σ 2 ) + b ∗ ) K(x, z)=\exp \left(-\frac{\|x-z\|^{2}}{2 \sigma^{2}}\right)\\ f(x)=\operatorname{sign}\left(\sum_{i=1}^{N_{i}} a_{i}^{*} y_{i} \exp \left(-\frac{\|x-z\|^{2}}{2 \sigma^{2}}\right)+b^{*}\right) K(x,z)=exp(−2σ2∥x−z∥2)f(x)=sign(i=1∑Niai∗yiexp(−2σ2∥x−z∥2)+b∗) -
字符串核函数:
k n ( s , t ) = ∑ u ∈ Σ n [ ϕ n ( s ) ] u [ ϕ n ( t ) ] u = ∑ u ∈ Σ n ∑ ( i , j ) : s ( i ) = t ( j ) = u λ l ( i ) λ l ( j ) k_{n}(s, t)=\sum_{u \in \Sigma^{n}}\left[\phi_{n}(s)\right]_{u}\left[\phi_{n}(t)\right]_{u}=\sum_{u \in \Sigma^{n}}\sum_{(i, j): s(i)=t(j)=u} \lambda^{l(i)} \lambda^{l(j)} kn(s,t)=u∈Σn∑[ϕn(s)]u[ϕn(t)]u=u∈Σn∑(i,j):s(i)=t(j)=u∑λl(i)λl(j)
给出了字符串 s s s和 t t t中长度等于 n n n的所有子串组成的特征向量的余弦相似度。直觉上,相同的子串越多,越相似,字符串核函数值越大。
4.3 非线性支持向量机学习算法:
输入: T = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , ⋯ , ( x N , y N ) } T=\left\{\left(x_{1}, y_{1}\right),\left(x_{2}, y_{2}\right), \cdots,\left(x_{N}, y_{N}\right)\right\} T={(x1,y1),(x2,y2),⋯,(xN,yN)},其中 x i ∈ X = R n , y i ∈ Y = { + 1 , − 1 } x_{i} \in \mathcal{X}=\mathbf{R}^{n},y_{i} \in \mathcal{Y}=\{+1,-1\} xi∈X=Rn,yi∈Y={+1,−1}, i = 1 , 2 , ⋯ , N i=1,2, \cdots, N i=1,2,⋯,N, x i x_i xi是第 i i i个特征向量,也称为实例, y i y_i yi为 x i x_i xi的类别标记
**输出:**分类决策函数
-
选取适当的核函数 K ( x , z ) K(x, z) K(x,z)和适当的参数 C C C,构造并求解最优化问题:
min α 1 2 ∑ i = 1 N ∑ j = 1 N α i α j y i y j K ( x i , x j ) − ∑ i = 1 N α i s.t. ∑ i = 1 N α i y i = 0 0 ⩽ α i ⩽ C , i = 1 , 2 , ⋯ , N \begin{array}{ll}{\min _{\alpha}} & {\frac{1}{2} \sum_{i=1}^{N} \sum_{j=1}^{N} \alpha_{i} \alpha_{j} y_{i} y_{j} K\left(x_{i}, x_{j}\right)-\sum_{i=1}^{N} \alpha_{i}} \\ {\text { s.t. }} & {\sum_{i=1}^{N} \alpha_{i} y_{i}=0} \\ {} & {0 \leqslant \alpha_{i} \leqslant C, \quad i=1,2, \cdots, N}\end{array} minα s.t. 21∑i=1N∑j=1NαiαjyiyjK(xi,xj)−∑i=1Nαi∑i=1Nαiyi=00⩽αi⩽C,i=1,2,⋯,N
求得最优解: α ∗ = ( α 1 ∗ , α 2 ∗ , ⋯ , α N ∗ ) T \alpha^{*}=\left(\alpha_{1}^{*}, \alpha_{2}^{*}, \cdots, \alpha_{N}^{*}\right)^{\mathrm{T}} α∗=(α1∗,α2∗,⋯,αN∗)T -
选择 α ∗ \alpha^{*} α∗的一个正向量 0 < α j ∗ < C 0<\alpha_{j}^{*}<C 0<αj∗<C,计算 b ∗ = y j − ∑ i = l N α i ∗ y i K ( x i ⋅ x j ) b^{*}=y_{j}-\sum_{i=l}^{N} \alpha_{i}^{*} y_{i} K\left(x_{i} \cdot x_{j}\right) b∗=yj−∑i=lNαi∗yiK(xi⋅xj)
-
构造决策函数: f ( x ) = sign ( ∑ i = 1 N α i ∗ y i K ( x ⋅ x i ) + b ∗ ) f(x)=\operatorname{sign}\left(\sum_{i=1}^{N} \alpha_{i}^{*} y_{i} K\left(x \cdot x_{i}\right)+b^{*}\right) f(x)=sign(∑i=1Nαi∗yiK(x⋅xi)+b∗)
当 K ( x , z ) K(x, z) K(x,z)是正定核函数时,待求解的最优化问题为凸二次规划问题,解存在














 993
993











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









