







使用 pydub 将各种音频格式相互转换
https://github.com/jiaaro/pydub/blob/master/API.markdown
1、pydub 安装使用
这里我们利用 pydub 库处理音频。
pydub 是 python 的高级一个音频处理库。
开发者的 github 地址:https://github.com/jiaaro/pydub
本文涉及的所有操作都是有 windows 下进行的。
pip install pydub
作者在 github 上说,依赖可以安装 libav 或 ffmpeg。
Mac (using homebrew):
# libav
brew install libav --with-libvorbis --with-sdl --with-theora
#### OR #####
# ffmpeg
brew install ffmpeg --with-libvorbis --with-sdl2 --with-theora
Linux (using aptitude):
# libav
apt-get install libav-tools libavcodec-extra-53
#### OR #####
# ffmpeg
apt-get install ffmpeg libavcodec-extra-53
由于开发环境用的是 windows 系统,对 libac 支持不大好,于是采用了 ffmpeg。
首先去 ffmpeg 官网下载:
https://ffmpeg.zeranoe.com/builds/
选择 Linking 下的 Static 下载,好了之后解压缩,然后将解压后的 bin 路径配置到环境变量 path 中:
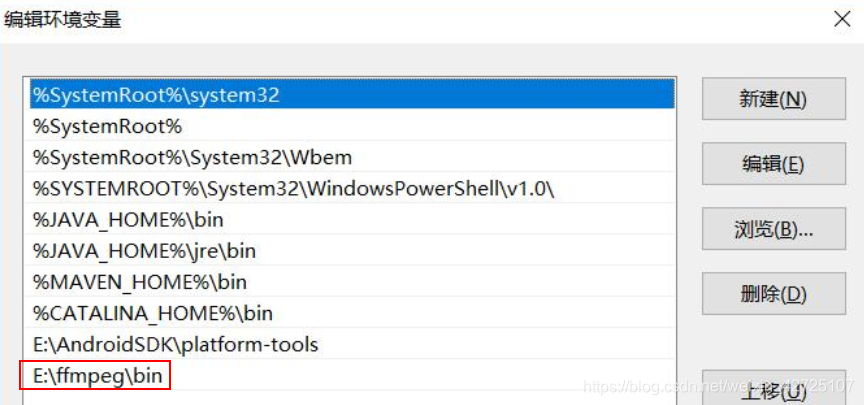
然后打开 IDE(注意:IDE 必须以管理员权限运行)。
2、mp3 转 wav
import os
from pydub import AudioSegment
rpath = os.getcwd()
s_path = os.path.join(rpath, 'fdir','01.mp3')
t_path = os.path.join(rpath, 'fdir','w01.wav')
# sound = AudioSegment.from_mp3(s_path)
sound = AudioSegment.from_file(s_path, format='mp3')
sound.export(t_path,format ='wav')
参考地址:https://blog.csdn.net/Lynn_coder/article/details/79436579?utm_source=blogxgwz2
3、将一个音频分割成多个音频
import os
from pydub import AudioSegment
rpath = os.getcwd()
s_path = os.path.join(rpath, 'fdir', 'sound-1.mp3')
sound = AudioSegment.from_file(s_path, format='mp3')
# 将输入分割成 5 秒的(多个)片段并导出
for i, chunk in enumerate(sound[::5000]):
with open("sound-%s.mp3" % i, "wb") as f:
chunk.export(f, format="mp3")
4、音频段中的通道数
1 表示单声道,2 表示立体声。
import os
from pydub import AudioSegment
rpath = os.getcwd()
s_path = os.path.join(rpath, 'fdir', 'part01.wav')
sound = AudioSegment.from_file(s_path)
channel_count = sound.channels
print(channel_count) # 2
5、采样中的字节数
每个采样中的字节数(1表示8位,2表示16位,等等)。CD音频为16位,(采样宽度为2字节)
import os
from pydub import AudioSegment
rpath = os.getcwd()
s_path = os.path.join(rpath, 'fdir', 'part01.wav')
sound = AudioSegment.from_file(s_path)
bytes_per_sample = sound.sample_width
print(bytes_per_sample) # 2
5、采样频率
CD 音频的采样率为44.1kHz,这意味着frame_rate将为44100(与采样率相同,请参见frame_width)。常见值为44100 (CD)、48000 (DVD)、22050、24000、12000和11025。
import os
from pydub import AudioSegment
rpath = os.getcwd()
s_path = os.path.join(rpath, 'fdir', 'part01.wav')
sound = AudioSegment.from_file(s_path)
frames_per_second = sound.frame_rate
print(frames_per_second) # 16000
6、每个帧的字节数
每个“帧”的字节数。一个帧包含每个通道的一个样本(因此对于立体声,每帧有两个样本,同时播放)。frame_width等于通道* sample_width。对于CD音频,它将是4(2个通道乘以每个示例2个字节)。
import os
from pydub import AudioSegment
rpath = os.getcwd()
s_path = os.path.join(rpath, 'fdir', 'part01.wav')
sound = AudioSegment.from_file(s_path)
bytes_per_frame = sound.frame_width
print(bytes_per_frame) # 4
7、音频文件的原始音频数据
音频文件的原始音频数据。用于与其他需要字节串形式的音频数据的音频库或奇怪的api进行交互。如果您正在实现效果或其他直接信号处理,也可以派上用场。
import os
from pydub import AudioSegment
rpath = os.getcwd()
s_path = os.path.join(rpath, 'fdir', 'part01.wav')
sound = AudioSegment.from_file(s_path)
raw_audio_data = sound.raw_data
print(raw_audio_data)
8、交叉合并多个音频文件为一个
返回一个新的 AudioSegment,通过 append() 或 + 操作符,将一个 AudioSegment 加到另外一个 AudioSegment。
import os
from pydub import AudioSegment
rpath = os.getcwd()
s_path1 = os.path.join(rpath, 'fdir', '01.mp3')
s_path2 = os.path.join(rpath, 'fdir', 'sound-3.mp3')
t_path = os.path.join(rpath, 'fdir', 't-sound-2.mp3')
sound1 = AudioSegment.from_file(s_path1)
sound2 = AudioSegment.from_file(s_path2)
# default 100 ms crossfade
# 音频 1播放完的前 100ms时,播放音频 2,在这交叉的 100ms里,音频 1和音频 2都会同时播放
# 合并后的音频总时长为 音频1时长 + 音频2时长 - crossfade
# combined = sound1.append(sound2)
# combined.export(t_path, format='mp3')
# 2000 ms 交叉播放,音频 1 播放 2秒,再将音频 2 播放 2 秒,如此交替
# 音频 1播放完的前 3000ms时,播放音频 2,在这交叉的 3000ms里,音频 1和音频 2都会同时播放
# 如果音频 1的时长有 30000ms,音频 2的时长有 10000ms,则新全成的音频时长为 30000+10000-3000=37000ms=37秒
# combined_with_5_sec_crossfade = sound1.append(sound2, crossfade=3000)
# combined_with_5_sec_crossfade.export(t_path, format='mp3')
# 无缝衔接 1,音频 1播放完毕,立马播放音频 2
# 合并后的音频总时长为 音频1时长 + 音频2时长
# no_crossfade1 = sound1.append(sound2, crossfade=0)
# no_crossfade1.export(t_path, format='mp3')
# 无缝衔接 2,音频 1播放完毕,立马播放音频 2
no_crossfade2 = sound1 + sound2
no_crossfade2.export(t_path, format='mp3')
9、音频叠加
在一个音频上面叠加一个音频。在最终的音频剪辑中,他们将同时播放。如果覆盖的音频比这个长,结果将被截断(所以覆盖的声音的末尾将被切断)。即使在使用循环和times关键字参数时,结果也总是与这个AudioSegment相同的长度。
overlay() 方法参数说明:
def overlay(self, seg, position=0, loop=False, times=None, gain_during_overlay=None):
"""
将提供的段覆盖到从特定的位置和使用指定的循环beahvior
Overlay the provided segment on to this segment starting at the
specificed position and using the specfied looping beahvior.
seg (AudioSegment):
覆盖(音频)对象.
position (optional int):
开始覆盖的位置(ms).
loop (optional bool):
循环 seg(覆盖音频) 多次,重复覆盖.
times (optional int):
循环 seg(覆盖音频)指定的次数,音频 2覆盖音频 1 指定次数.
gain_during_overlay (optional int):
将 seg(覆盖音频) 以指定的音量叠加到原音频.
"""
示例:
import os
from pydub import AudioSegment
rpath = os.getcwd()
s_path1 = os.path.join(rpath, 'fdir', '03.mp3')
s_path2 = os.path.join(rpath, 'fdir', 'sound-1.mp3')
t_path = os.path.join(rpath, 'fdir', 't-sound-17.mp3')
sound1 = AudioSegment.from_file(s_path1)
sound2 = AudioSegment.from_file(s_path2)
# 将音频 2叠加到音频 1,从头开始叠加
# played_togther = sound1.overlay(sound2)
# played_togther.export(t_path,format='mp3')
# 将音频 2叠加到音频 1,从2秒开始叠加
# sound2_starts_after_delay = sound1.overlay(sound2, position=2000)
# sound2_starts_after_delay.export(t_path,format='mp3')
# 循环 seg(音频2) 多次,重复叠加
# sound2_repeats_until_sound1_ends = sound1.overlay(sound2, loop=True)
# sound2_repeats_until_sound1_ends.export(t_path,format='mp3')
# 循环 seg(覆盖音频)指定的次数,音频 2叠加到音频 1 指定次数
# sound2_plays_twice = sound1.overlay(sound2, times=2)
# sound2_plays_twice.export(t_path,format='mp3')
# 将 seg(覆盖音频) 以指定的音量叠加到原音频
volume_of_sound1_reduced_during_overlay = sound1.overlay(sound2, gain_during_overlay=30)
volume_of_sound1_reduced_during_overlay.export(t_path,format='mp3')
10、改变音频音量
import os
from pydub import AudioSegment
rpath = os.getcwd()
s_path2 = os.path.join(rpath, 'fdir', 'sound-1.mp3')
t_path = os.path.join(rpath, 'fdir', 'a-sound-02.mp3')
sound1 = AudioSegment.from_file(s_path2)
# 把声音提高 13.5 dB
louder_via_method = sound1.apply_gain(+13.5)
louder_via_operator = sound1 + 13.5
louder_via_operator.export(t_path,format='mp3')
# 把声音降低 5.7 dB
# quieter_via_method = sound1.apply_gain(-5.7)
# quieter_via_operator = sound1 - 5.7
# louder_via_operator.export(t_path,format='mp3')
11、改变指定音频段音量
一个更通用(更灵活)的淡入方法。您可以指定开始和结束,或者其中之一以及持续时间(例如,开始和持续时间)。
方法参数说明:
def fade(self, to_gain=0, from_gain=0, start=None, end=None,
duration=None):
"""
to_gain (float):
resulting volume_change in db
start (int):
default = beginning of the segment
when in this segment to start fading in milliseconds
end (int):
default = end of the segment
when in this segment to start fading in milliseconds
duration (int):
default = until the end of the audio segment
the duration of the fade
"""
12、同时调节音频左右音道的增益
apply_gain_stereo(left_dB, right_dB):
将增益应用于立体声音响的左右声道。如果音频是单声道的,在应用增益之前,它将被转换成立体声。
两个增益参数都在dB中指定。
import os
from pydub import AudioSegment
rpath = os.getcwd()
s_path = os.path.join(rpath, 'fdir', 'splitFile', 'sp-8.mp3')
t_path = os.path.join(rpath, 'fdir', 'mk1', 'fade09.mp3')
sound1 = AudioSegment.from_file(s_path)
# 将左通道降低 10dB 更安静,右通道增设 20dB 更大声
stereo_balance_adjusted = sound1.apply_gain_stereo(-10, +20)
stereo_balance_adjusted.export(t_path,format='mp3')














 776
776











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









