




 博客指出使用Canal-Adapter全量同步大数据量时,会导致内存、CPU过载,ES被docker关闭,其他容器也无法提供服务。解决方案一是对ES进行限制,设置单节点模式等参数;二是对Canal-Adapter进行限制,修改docker canal-adapter内部的start.sh脚本,调整内存配置。
博客指出使用Canal-Adapter全量同步大数据量时,会导致内存、CPU过载,ES被docker关闭,其他容器也无法提供服务。解决方案一是对ES进行限制,设置单节点模式等参数;二是对Canal-Adapter进行限制,修改docker canal-adapter内部的start.sh脚本,调整内存配置。
问题
使用canal-adapter全量同步(参考Canal Adapter1.1.5版本API操作服务,手动同步数据(4))的时候
- 小批量数据可以正常运行(几千条)
- 只要数据量一大(上万条),就会内存、CPU双线爆炸,ES自动被docker关闭。
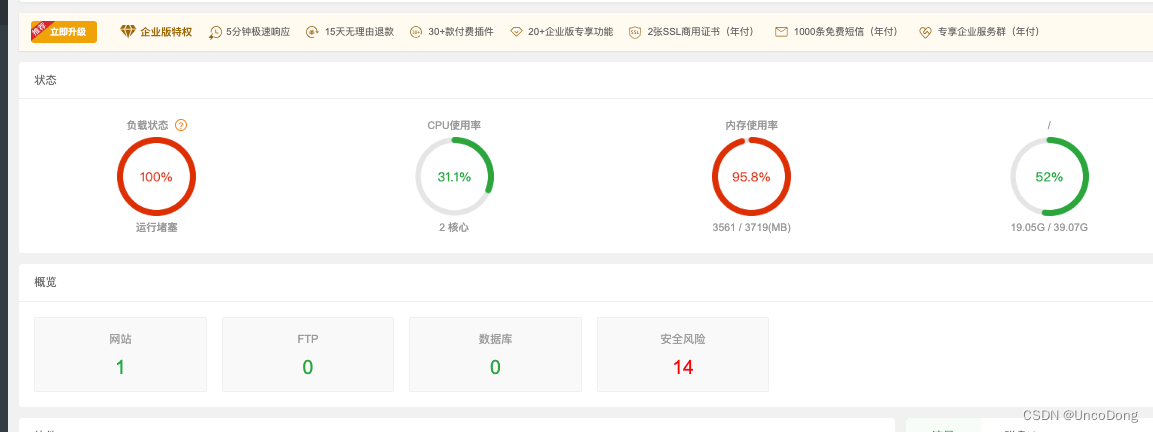
数据量大的时候系统负荷如下所示(用宝塔监控)
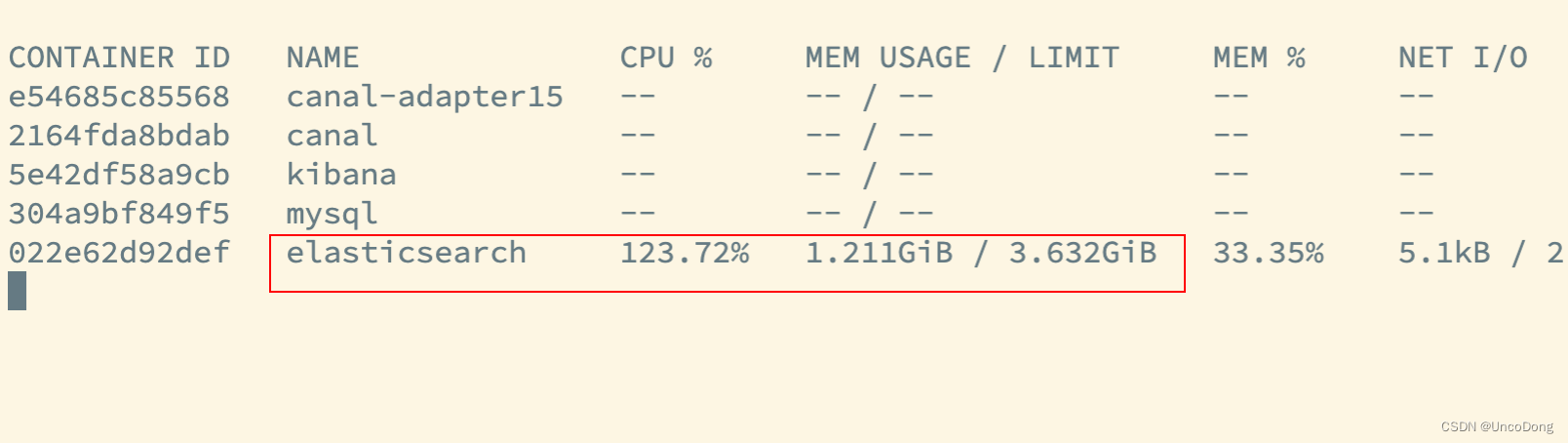
docker stats监控如下所示,很快其他容器全都变成--,完全无法提供服务
解决方案
1. 对ES的限制
最关键的一句话:启动的时候按照如下参数启动。必须得先设置single-node单节点模式,然后设置ES_JAVA_OPTS="-Xms64m -Xmx512m" 才会成功。
docker run -d --name limit_es -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" -e ES_JAVA_OPTS="-Xms64m -Xmx512m" elasticsearch:7.6.2
ES_JAVA_OPTS的意思是设置ES中Java虚拟机环境的上下限
discovery.type=single-node是单节点模式的意思。和集群有关的配置可以参考ElasticSearch 设置-配置(一)发现和集群形成设置
-
discovery.seed_hosts:提供集群中符合主节点条件的节点列表。也可以是以逗号分隔的单个字符串。每个节点都是host:port或者host格式。host是由DNS解析出来的任意主机名称。IPV6必须用方括号括起来。如果一个主机名通过DNS解析出来多个地址,ElasticSearch会使用所有被解析出来的地址。
-
discovery.seed_providers:指定种子主机提供程序的类型来获取用于启动发现进程的种子节点的地址。默认情况下,它是基于设置的种子主机提供程序,它从 discovery.seed_hosts 设置中获取种子节点地址。此设置以前称为 discovery.zen.hosts_provider。
-
discovery.type:指定 Elasticsearch 是否应形成多节点集群。默认情况下,Elasticsearch 在形成集群时会发现其他节点,并允许其他节点稍后加入集群。如果discovery.type 设置为single-node,Elasticsearch 会形成一个单节点集群并不支持cluster.publish.timeout 设置的超时。
-
cluster.initial_master_nodes:设置全新群集中符合条件的主节点的初始集。默认情况下,此列表为空,表示此节点希望加入已引导的集群。请参阅cluster.initial_master_nodes。
ES的内存占用显著小了很多,并且可以直接同步大批量数据
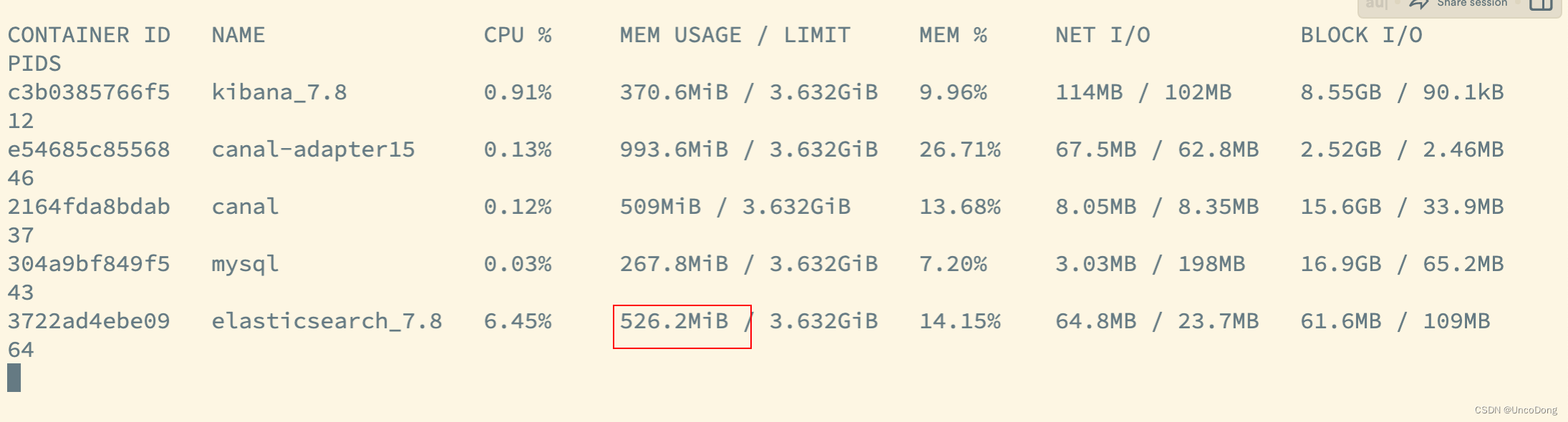
2. 对Canal-Adapter的限制
我在canal-adapter中也提了一个issue,并尝试自己解决
我对docker canal-adapter内部的start.sh进行了修改,似乎好像解决了这个问题?但是只是本地部署没有看出问题,不知道线上如何。先记录一下修改方案
以下修改方案基于slpcat/canal-adapter:v1.1.5-jdk8修改
首先docker exec进入到容器内部,修改启动脚本vi bin/startup.sh
我修改了两个地方
- if else判断的地方,我直接指定JAVA_OPTS为
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 734
734

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









