







本文将会介绍图像识别中涉及的一些概念和专业名词
图像识别的三大任务
●目标识别:对图片进行分类,确定图片中的目标是什么。
如下图要分类图中的水杯和水瓶,方体。

●目标检测:定位目标,确定目标在图片中的具体位置

●目标分割:对图片进行像素级的分类前景和背景,剔除背景并描述目标的形状
不剔除背景:
剔除背景:
这里着重介绍目标检测
目标检测的定义
●识别图中有哪些物体以及定位物体的位置,这里的位置的表现形式是坐标。

位置的表现形式:坐标
●极坐标:(Xmin,Xmax,Ymin,Ymax)
检测框BBox(bounding box)四个角对应的坐标
以图片的左上角为原点建立坐标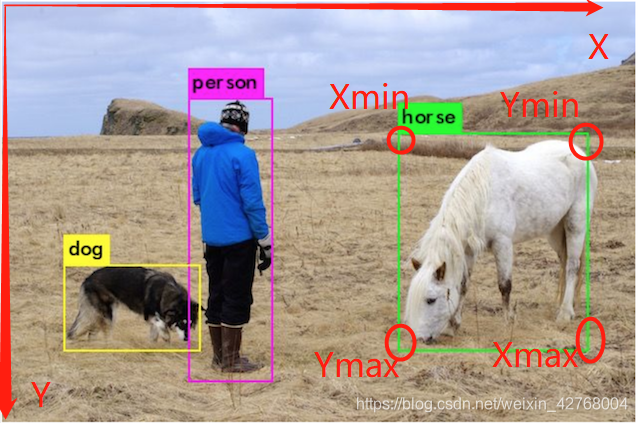
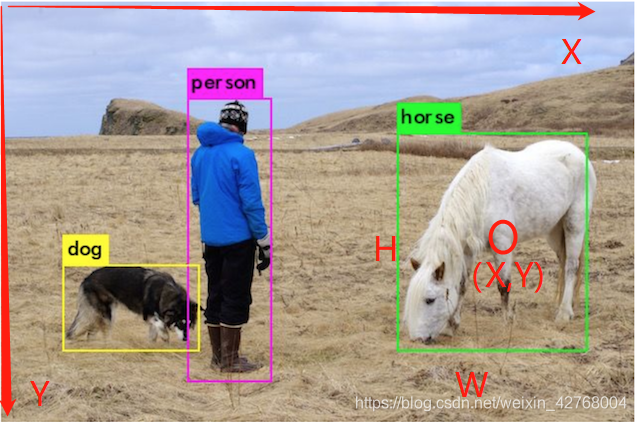
●中心坐标:(X,Y,W,H)
同样以图片左上角为原点建立坐标。
这里X,Y表达的是中心点的坐标,即检测框的中心处
W,H则是检测框的宽和高。
目标检测细分:
●目标检测:图片中有多个目标
●分类+定位:图片中只有一个目标
目标检测的发展与分类
1、传统目标检测方法:手工提取特征,候选区,分类器
2、CNN提取分类的目标检测框架:R-CNN,Fast-CNN,Faster-CNN
3、端到端的目标检测框架:YOLO,SSD
其中除了传统的检测方式,CNN与端到端刚好分为两类。
●两步走:先进行区域推荐,再进行目标检测的判断。
●端到端:一个网络一步到位
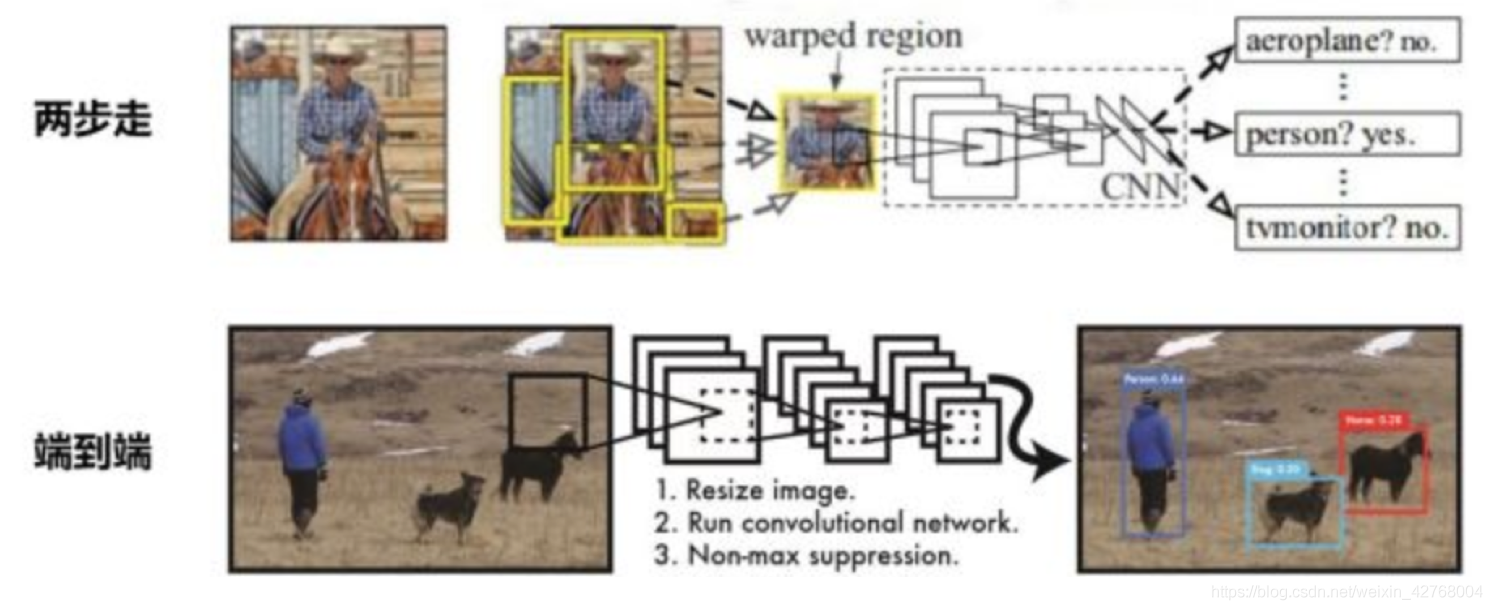
两步走是随机在图片中推荐区域,然后进入网络判断是否为要检测的目标。
端到端则直接定位图片中的目标,可以说后者的效率会更高一点。
目标检测的准确率评估
在用CNN做图像分类中会有softmax函数进行结果计算。而在目标检测中IoU(交并比)来计算结果。
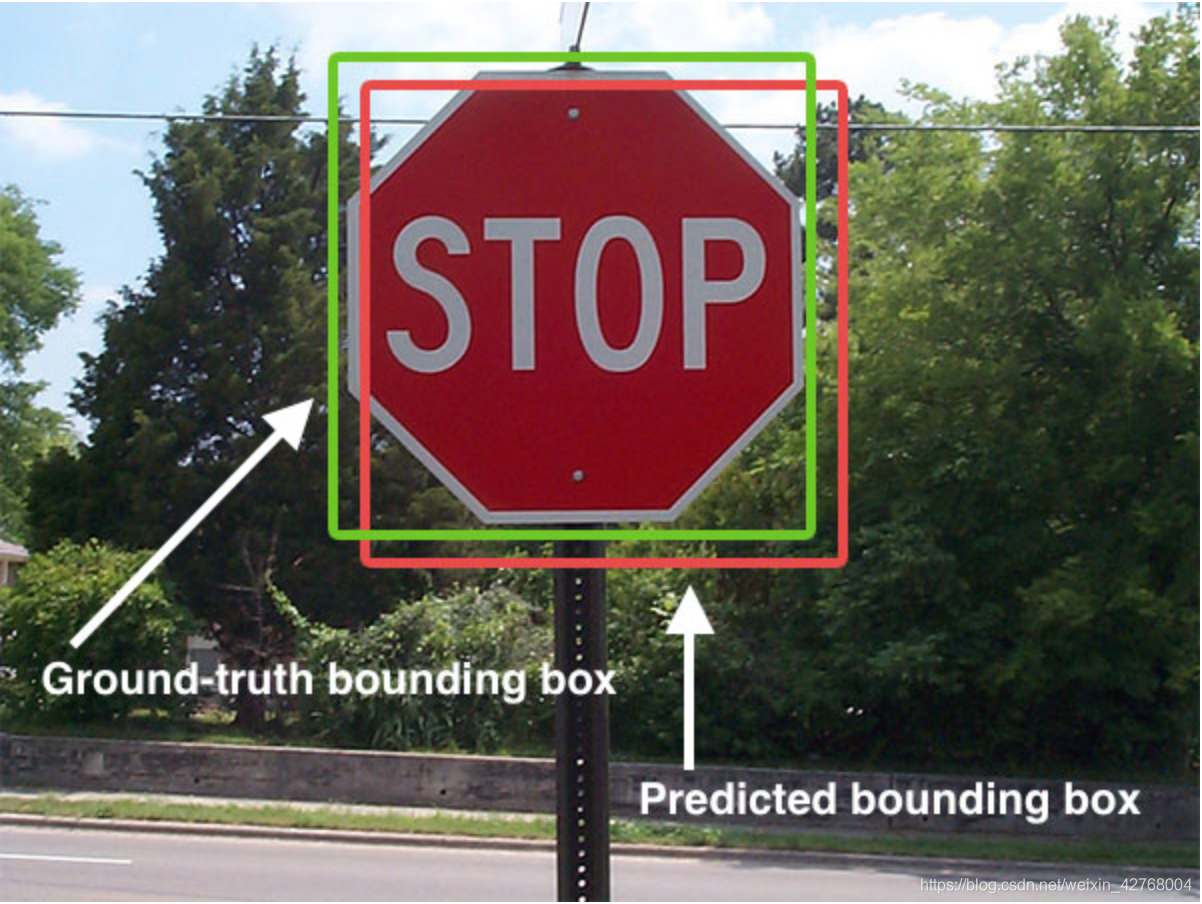
●IoU:两个区域的重叠程度
前面提到的检测框bounding box.分为两类:一类是真实目标框,也就是用于训练模型的图片中手动标注的目标框(Ground-truth bounding box)。另一类则是模型预测时的目标框(Predicted bounding box)
IoU的计算公式为:真实目标框与预测目标框相交的面积/两个目标框总的面积。
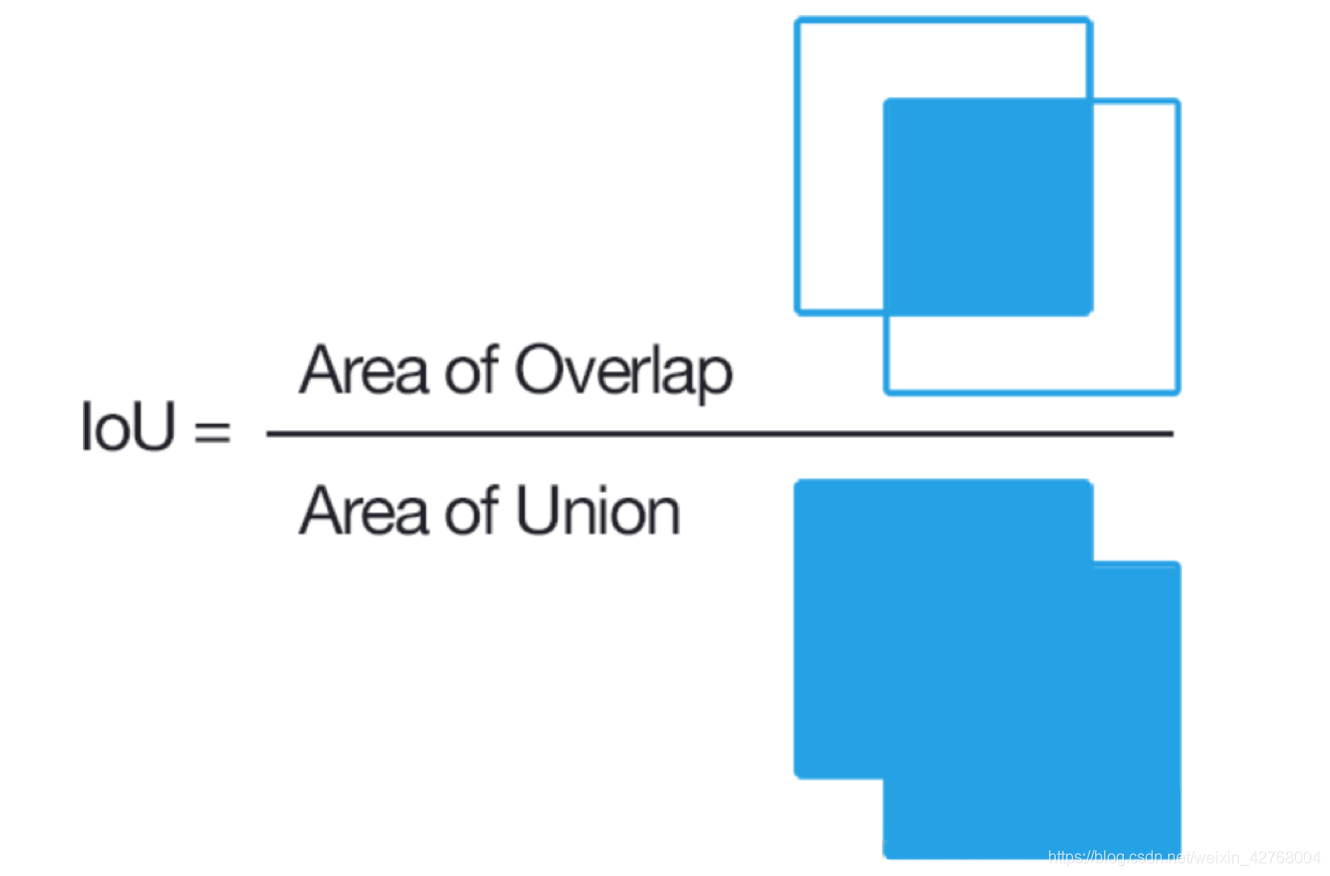
所以当结果为1时,真实目标框与预测目标框重合。也就是说目标检测的位置准确率为100%。
END
图片源于黑马程序员














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









