







Batch Normalization
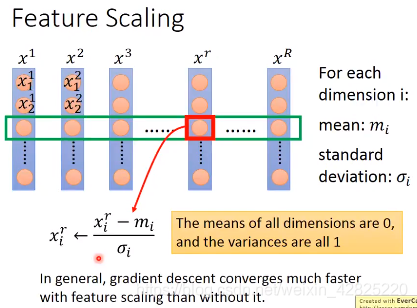
Feature Scaling/Feature Normalization/Feature Standardization
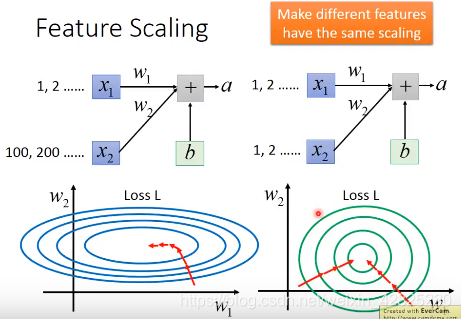
如果斜率差别大,那么不同方向上需要不同的learning rate,经过feature normalization后,error surface接近正圆形,使得训练更容易
计算过程:

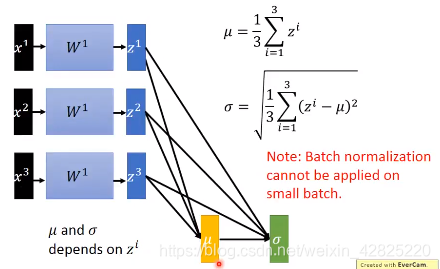
在神经网络的每一层都做feature scaling可以减轻internal covariate shift,可以确保每个layer的output的统计是固定的
internal covariate shift就是指后面layer的参数调整后,前面layer的参数也在同时调整
传统internal covariate shift解决方案:将learning rate调小
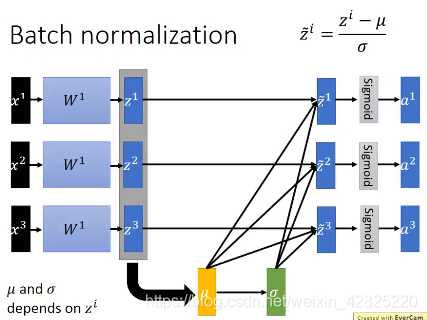
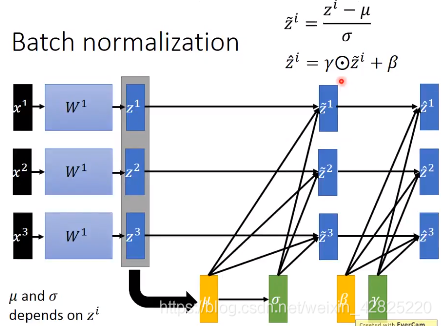
可以在激活函数前或者后做batch normalization,在前做的情况比较常用,能确保值是在0的附近,也就是微分比较大的地方
均值和标准差通常应当是基于整个数据集的,但数据集过于庞大,因此通常都会在batch上进行,所以batch的值不能太小
后向传播的时候同样会改变μ![]() 和σ
和σ![]() ,并不能直接当作常量,与传统的后向传播有一定的差别
,并不能直接当作常量,与传统的后向传播有一定的差别
也可以通过γ![]() 和β
和β![]() 改变μ
改变μ![]() 和σ
和σ![]() ,其中μ
,其中μ![]() 和σ
和σ![]() 是决定于数据的,而γ
是决定于数据的,而γ![]() 和β
和β![]() 是独立的,因此是不一样的:
是独立的,因此是不一样的:
测试阶段如何算μ![]() 和σ
和σ![]() :
:
- 将训练集的所有数据收集起来计算μ
 和σ
和σ
- 将过去算出来的μ
 和σ
和σ 收集起来,算加权平均
收集起来,算加权平均

BN的优点:
- 可以将learning rate设置得大一点(减轻internal covariate shift)
- 可以减轻梯度消失,可以保持值在梯度大的地方,尤其是sigmoid,tanh等
- 可以减小初始化参数对学习的影响
- 可以对抗过拟合,等同于做了regularization
- 对training和test都有帮助,对training帮助更大李宏毅教授














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









