







在我们进行数据分析或者是机器学习模型建立的时候我们往往忽略数据处理的一个过程-----相关性分析。诚然,数据相互之间可能会存在一些联系,这些关系可能正相关,或者是负相关,也可能无关。
设X1,X2,X3,X4,X5为模型的自变量,Y为因变量。可以想到,如果X1与X2有很强的相关性或者X3与X2有相关性,即两两之间存在某种相关性,那么是不是意味着某个特征可以由其他特征表示?既然这样,有些特征也许是多余的。这些特征对我们的模型起不了很大的作用,甚至是模型的累赘,消耗内存。
在建立模型的过程中。 那么我们就需要一种能把这种关联性定量的工具来对数据进行分析。
- 皮尔逊相关性分析
皮尔逊相关性系数只能表达两两特征之间的关系。
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
% matplotlib inline
data2 = pd.read_csv(r'E:\Project1\section_1_day_data.csv',index_col=0)
X=data2.iloc[:, 0:10]
sns.heatmap(X.corr(),vmin=0, vmax=1);

print(X.corr()) #显示特征与特征之间的相关性系数。
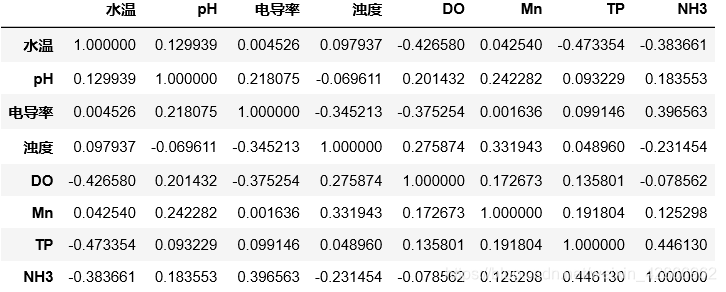
相关性区间为[-1,1],-1代表完全负相关,1代表完全正相关。为0代表完全不相关。因此,相关性系数绝对值越接近于1,两者特征之间的相关性最强。
怎么样,变量之间的相关性是不是一清二楚了?
报告老师,水温和参数TP之间的关系最强。小论文最后一章又有东西写了,多加几张表投个SCI四区论文水一下问题不大。
在这里要注意了,\右对角线上的都是1,代表变量与自身的关系。 ±代表正负相关。 因此,我们通常通过相关系数的绝对值来判断特征之间的相关性。














 2712
2712











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









