






图像中瑕疵检测
1.概述
瑕疵检测是机器视觉任务中的一条分支,在技术发展的过程中对于图片处理的方式往往使用CNN(卷积神经网络)作为处理模型,毫无疑问CNN的在处理图像方面有着独特的优势,通过设置卷积核我们可以使得计算机提取图像的特征数据,再通过延伸纵向的网络模型增加网络神经元的个数,可以很好地让网络模型识别图片中的内容,所以说CNN在图像分类和识别当中都有着很好的效果,在实践过程中也有着很不错的表现。但是在图像瑕疵检测的任务中,我们不能单纯地使用CNN来提取特征,通过整体的图像特征来预测图片中瑕疵的信息,因为图片中瑕疵的信息站整体图片信息的比例很小,在这种情况下模型很容易忽略了这部分信息,但是我们恰好想要预测的就是这些内容。
2.瑕疵检测的开山鼻祖RCNN
在机器视觉发展的过程中,为了很好地处理包含重要信息的区域像素,应运而生RCNN(基于区域的卷积神经网络)模型,它的工作流程如下图所示。
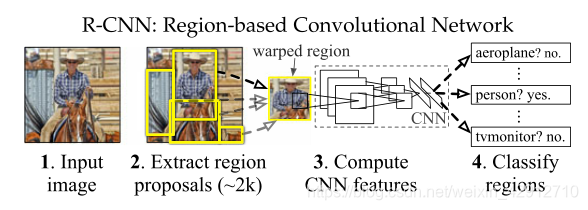
RCNN是CNN在图像检测中的一种扩展,用以弥补图像在小范围区域中的信息忽略的问题。其核心的思想是滑动窗口块的设置,在这里不过多赘述(参照论文《Region-Based Convolutional Networks for
Accurate Object Detection and Segmentation》)过程简述如下:在图片中自定义一个滑动窗口,利用这个滑动窗口从图像的开始位置进行扫描分析,在滑动窗口取出的这部分像素中,通过卷积等一系列操作,提取特征,再分析框选这部分内容中是否包含物体、包含哪种物体得出结果。当然这种模型显然的弊端就是自定义窗口的大小,窗口太大会造成模型预测不准确,窗口太小则会造成时间上的开销。如何权衡这些部分,就涉及到YOLO的内容了。
3.YOLO
YOLO(You Only Look Once),源自于《Y ou Only Look Once:
Unified, Real-Time Object Detection》这篇论文,它是在RCNN的基础上做出了很大的改进。
传统目标检测系统采用deformable parts models (DPM)方法,通过滑动框方法提出目标区域,然后采用分类器来实现识别。近期的R-CNN类方法采用region proposal methods,首先生成潜在的bounding boxes,然后采用分类器识别这些bounding boxes区域。最后通过post-processing来去除重复bounding boxes来进行优化。这类方法流程复杂,存在速度慢和训练困难的问题。
YOLO采用单个卷积神经网络来预测多个bounding boxes和类别概率,如图1-1所示。本方法相对于传统方法有如下有优点:
一,非常快。YOLO预测流程简单,速度很快。我们的基础版在Titan X GPU上可以达到45帧/s; 快速版可以达到150帧/s。因此,YOLO可以实现实时检测。
二,YOLO采用全图信息来进行预测。与滑动窗口方法和region proposal-based方法不同,YOLO在训练和预测过程中可以利用全图信息。Fast R-CNN检测方法会错误的将背景中的斑块检测为目标,原因在于Fast R-CNN在检测中无法看到全局图像。相对于Fast R-CNN,YOLO背景预测错误率低一半。
三,YOLO可以学习到目标的概括信息(generalizable representation),具有一定普适性。我们采用自然图片训练YOLO,然后采用艺术图像来预测。YOLO比其它目标检测方法(DPM和R-CNN)准确率高很多。
YOLO的准确率没有最好的检测系统准确率高。YOLO可以快速识别图像中的目标,但是准确定位目标(特别是小目标)有点困难。
3.1网络结构
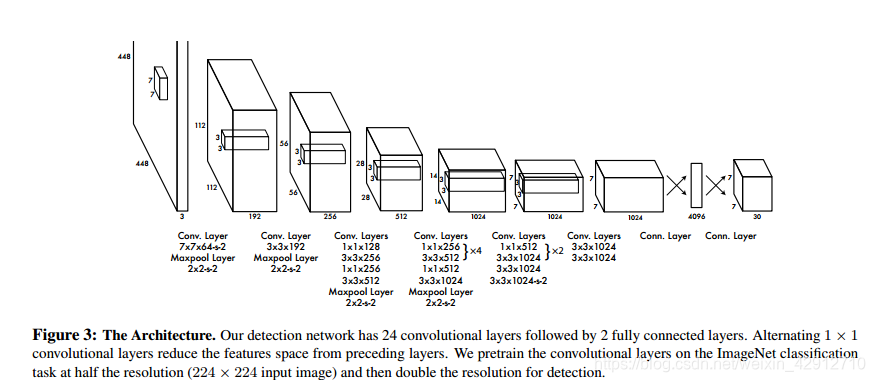
模型采用卷积神经网络结构。开始的卷积层提取图像特征,全连接层预测输出概率。模型结构类似于GoogleNet,如图3所示。作者还训练了YOLO的快速版本(fast YOLO)。Fast YOLO模型卷积层和filter更少。最终输出为7×7×30的tensor。
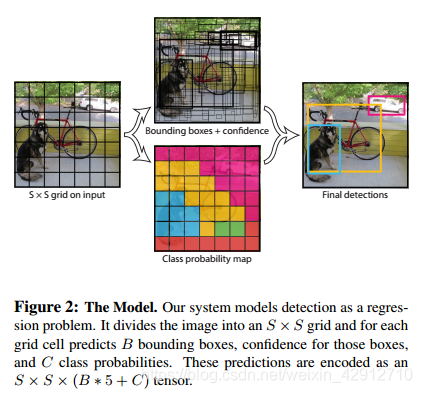
3.2检测过程
YOLO首先将图像分为S×S的格子(grid cell)。如果一个目标的中心落入格子,该格子就负责检测该目标。每一个格子(grid cell)预测bounding boxes(B)和该boxes的置信值(confidence score)。置信值代表box包含一个目标的置信度。然后,我们定义置信值为[公式]。如果没有目标,置信值为零。另外,我们希望预测的置信值和ground truth的intersection over union (IOU)相同。
每一个bounding box包含5个值:x,y,w,h和confidence。(x,y)代表与格子相关的box的中心。(w,h)为与全图信息相关的box的宽和高。confidence代表预测boxes的IOU和gound truth。
每个格子(grid cell)预测条件概率值C。概率值C代表了格子包含一个目标的概率,每一格子只预测一类概率。在测试时,每个box通过类别概率和box置信度相乘来得到特定类别置信分数:
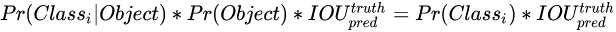
这个分数代表该类别出现在box中的概率和box和目标的合适度。在PASCAL VOC数据集上评价时,我们采用S=7,B=2,C=20(该数据集包含20个类别),最终预测结果为7×7×30的tensor。














 1416
1416











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









