







本节内容快速略过,主要说明怎么执行程序。。。。。
WordCount的python代码:
from pyspark import SparkContext
from pyspark import SparkConf
def CreateSparkContext():
sparkConf = SparkConf() \
.setAppName("WordCounts") \
.set("spark.ui.showConsoleProgress", "false") \
sc = SparkContext(conf = sparkConf)
print("master="+sc.master)
SetLogger(sc)
SetPath(sc)
return (sc)
def SetLogger(sc):
logger = sc._jvm.org.apache.log4j
logger.LogManager.getLogger("org").setLevel(logger.Level.ERROR)
logger.LogManager.getLogger("akka").setLevel(logger.Level.ERROR)
logger.LogManager.getRootLogger().setLevel(logger.Level.ERROR)
def SetPath(sc):
global Path
if sc.master[0:5] == "local":
Path = "file:/home/pythonwork/test/"
else:
Path = "hdfs://master:9000/user/alex/"
if __name__ == "__main__":
print("开始执行WordCount")
sc = CreateSparkContext()
print("开始读文本...")
text = sc.textFile(Path+"data/README.md")
print("文本文件共"+str(text.count())+"行")
counts = text.flat(lambda line: line.split(" ")) \
.map(lambda x: (x, 1)) \
.reduceByKey(lambda x, y: x+y)
print("文字共统计"+str(counts.count())+"项数据")
print("开始保存至本地...")
try:
counts.saveAsTextFile(Path+"data/output")
except:
print("输出目录已存在")
sc.stop()
1、使用pyspark.submit执行程序
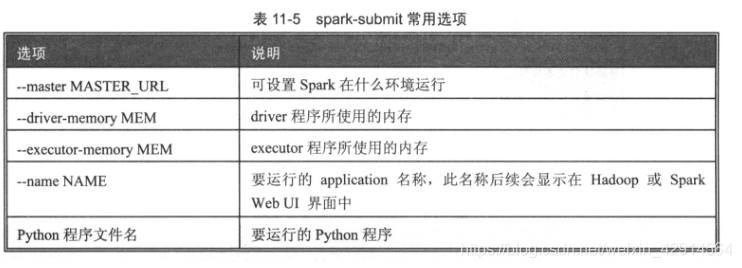

步骤:
打开hadoop,把数据上传到hdfs中,将程序写好后,使用以下代码执行即可
spark-submit --driver-memory 2g --master local[*] WordCount.py
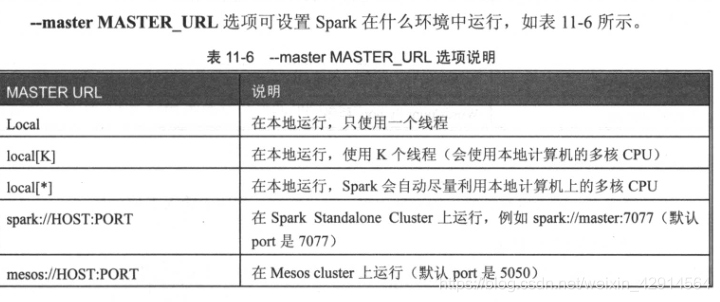
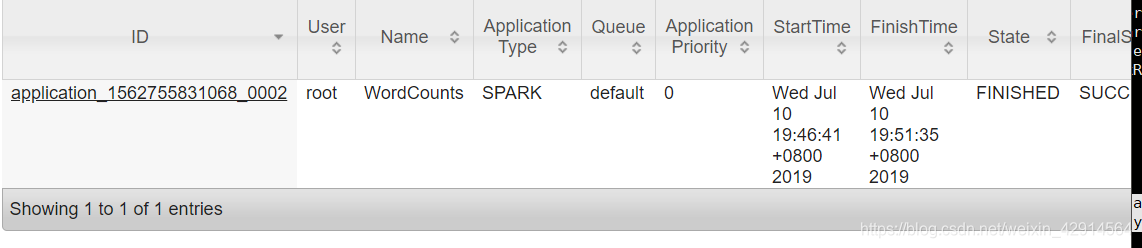
2、在Hadoop Yarn-client上运行

HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop spark-submit --driver-memory 512m --executor-cores 2 --master yarn --deploy-mode client WordCount.py
可在8088端口上查看运行情况
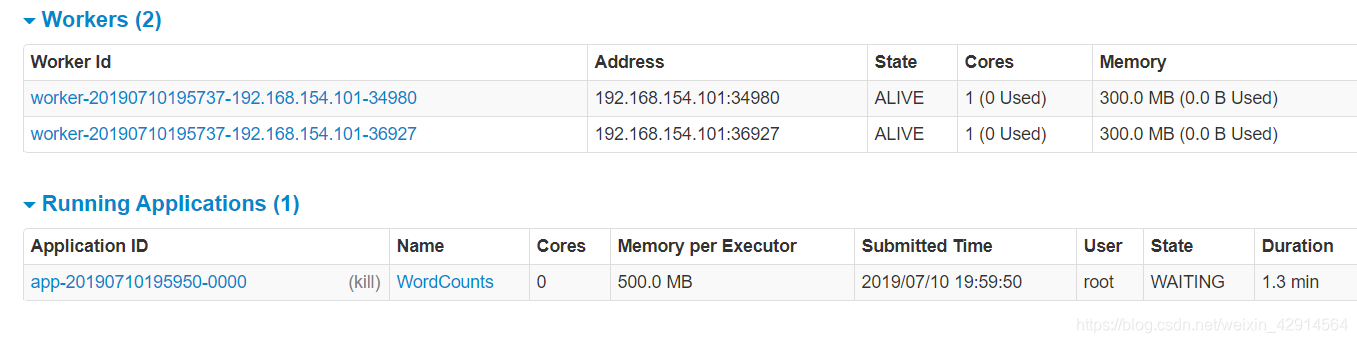
3、在Spark Standalone Cluster上运行
启用Standalone Cluster
/usr/local/spark/sbin/start-all.sh
运行
spark-submit --master spark://master:7077 --deploy-mode client
--executor-memory 500M --deploy-mode client --total-executor-cores 2 WordCount.py
8080端口上看运行情况(这里的内存我设置高了)














 746
746











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









